前端演进思考
【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>>

0. 从模型说起
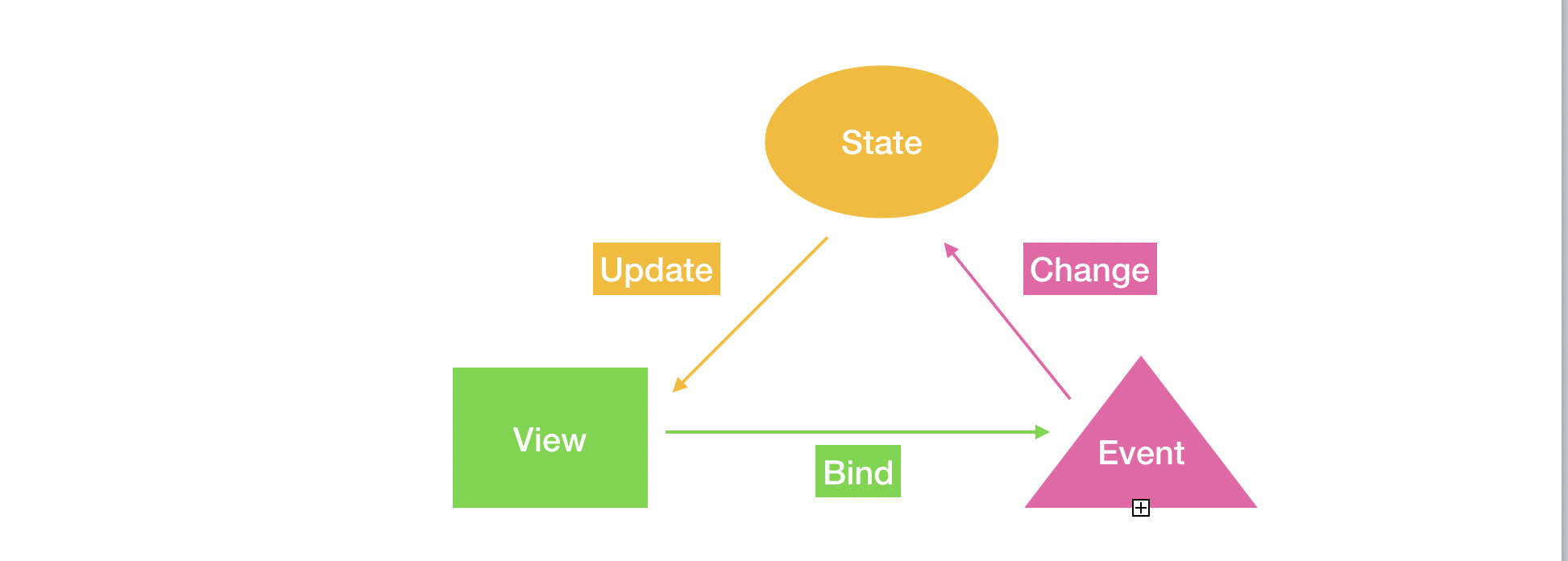
原生JS/jQuery 这时候开发者需要手动处理 Bind、Change 和 Update,jQuery 相比原生 JS,简化了操作,屏蔽了浏览器的兼容性。
三大框架 这时候开发者只需处理 Bind 和 Change,框架自动完成 Update。框架使用一套高效的 diff 算法最小化更新 DOM,因此除了简化开发者工作,还带来了前端性能的提升。
1. 组件思想
除此之外,框架另一个突出贡献是引入了 组件 思想,这使我们能将一个复杂的应用拆成多个组件逐个击破,还使我们能用一套基础组件组合出各种各样的应用,以高效的响应业务需求。
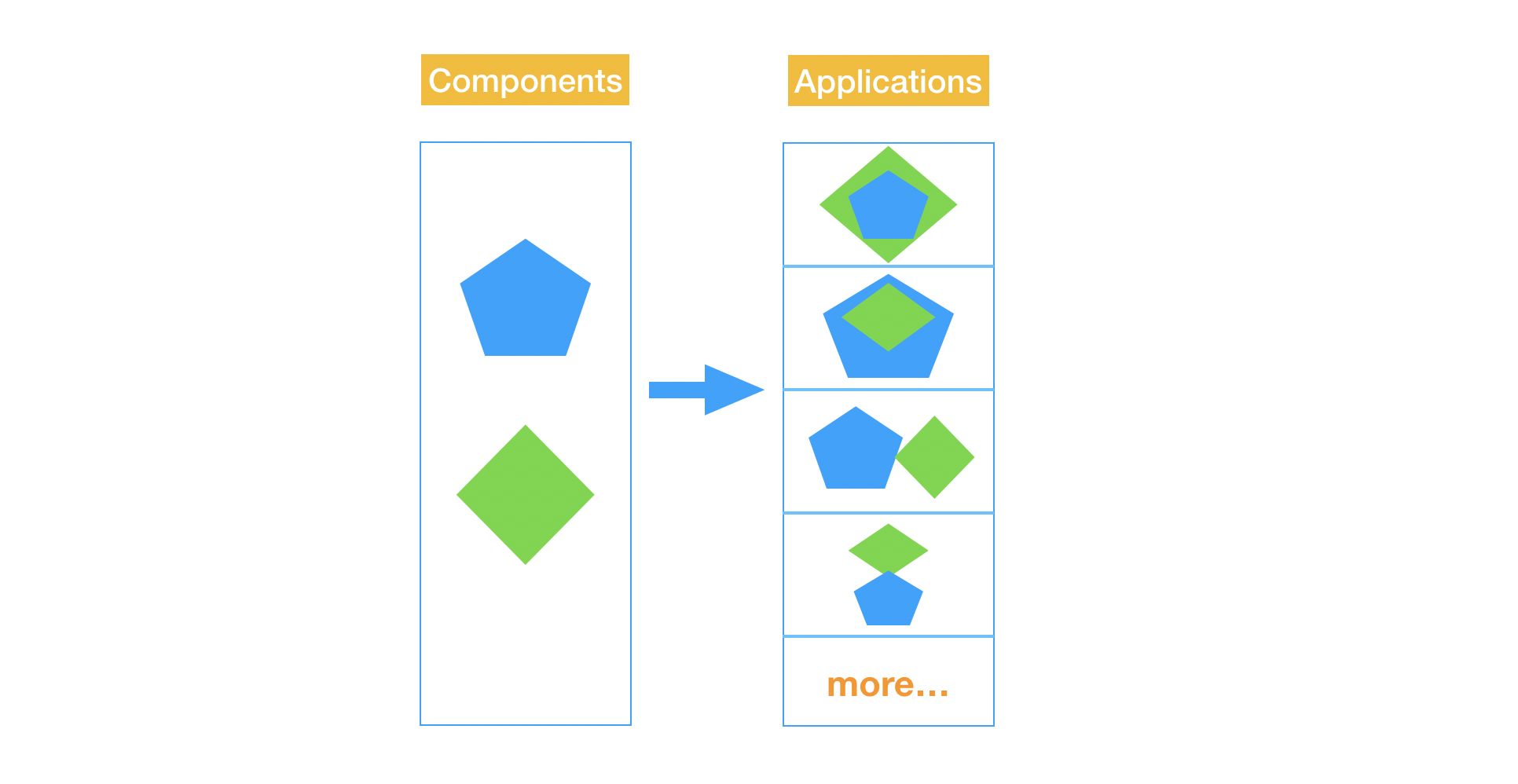
但是在大型应用中,这种方式又出现 2个严重的问题。
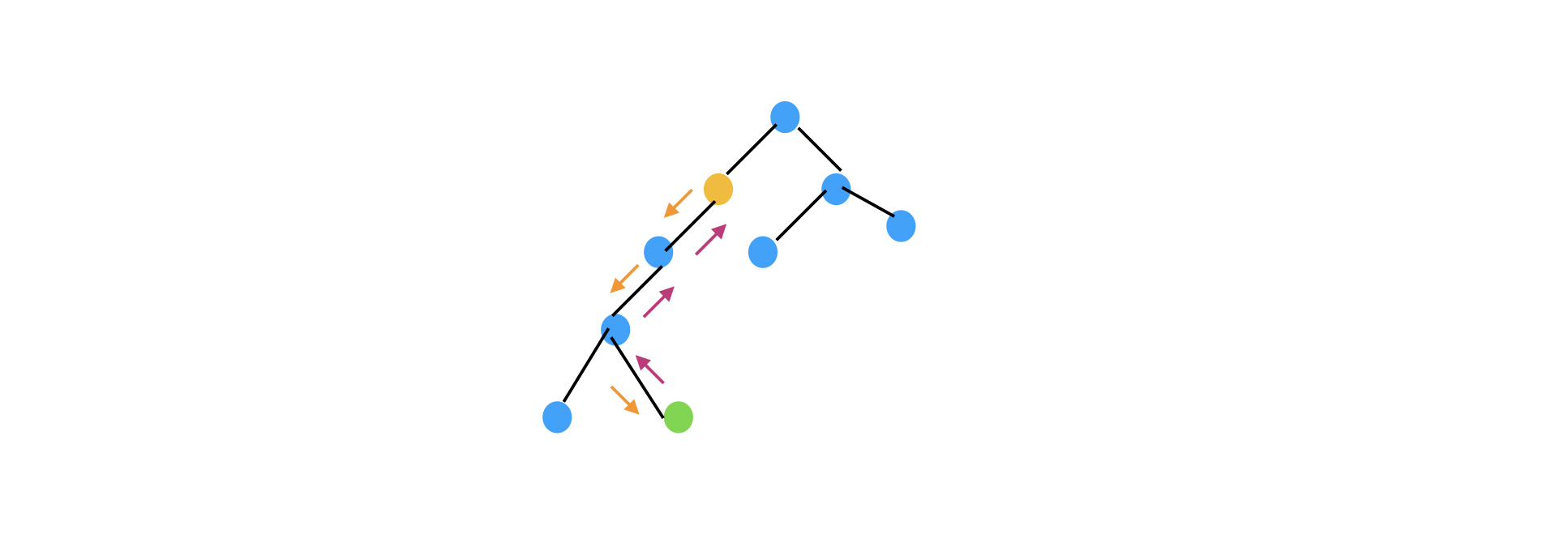
跨组件数据传递** 在单向数据流中,Props down & Event up,跨组件的数据传递非常困难,如上图的,中间2个组件即使不关注数据,也必须写上相关代码让数据传下来。联想到现实中,我们说的组织层级过多导致流程冗杂,也是类似的道理。
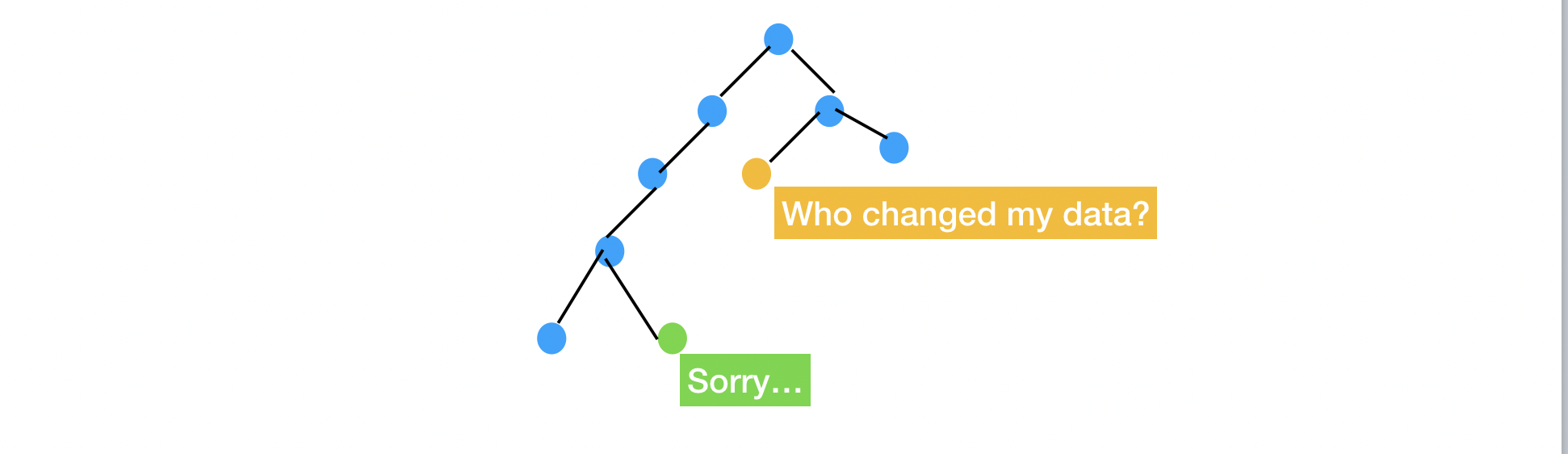
意外数据修改 JS 的数据类型和 Java 类似,除了少数几个基础类型是值,其他的都是 引用,因此在某个子组件里的数据修改,很容易影响到其他地方。尽管框架一再警告 props 应该看作只读的,但受制于语言特性,框架无法阻止意外的修改。
从开发者角度,我们也希望能 在一个地方就看到整个应用的状态,而不是深入到各个组件里去查看。
2. 状态管理
对于跨组件数据共享问题,一个自然的想法是:为啥不写一个公共的模块,把共享的变量都放到里面呢,之前写后端也是这样的呀?
前端还真不能这么干!根本原因在于我们要依赖框架的自动 Update 能力(第一张图),React 中 有且仅有两种情况会触发界面更新:
- state 变化(
setState) - context 变化(Redux)
(说 forceUpdate 的,看我眼神……)
于是 Redux 登场,理想情况下,数据流会被规整成下图那样:
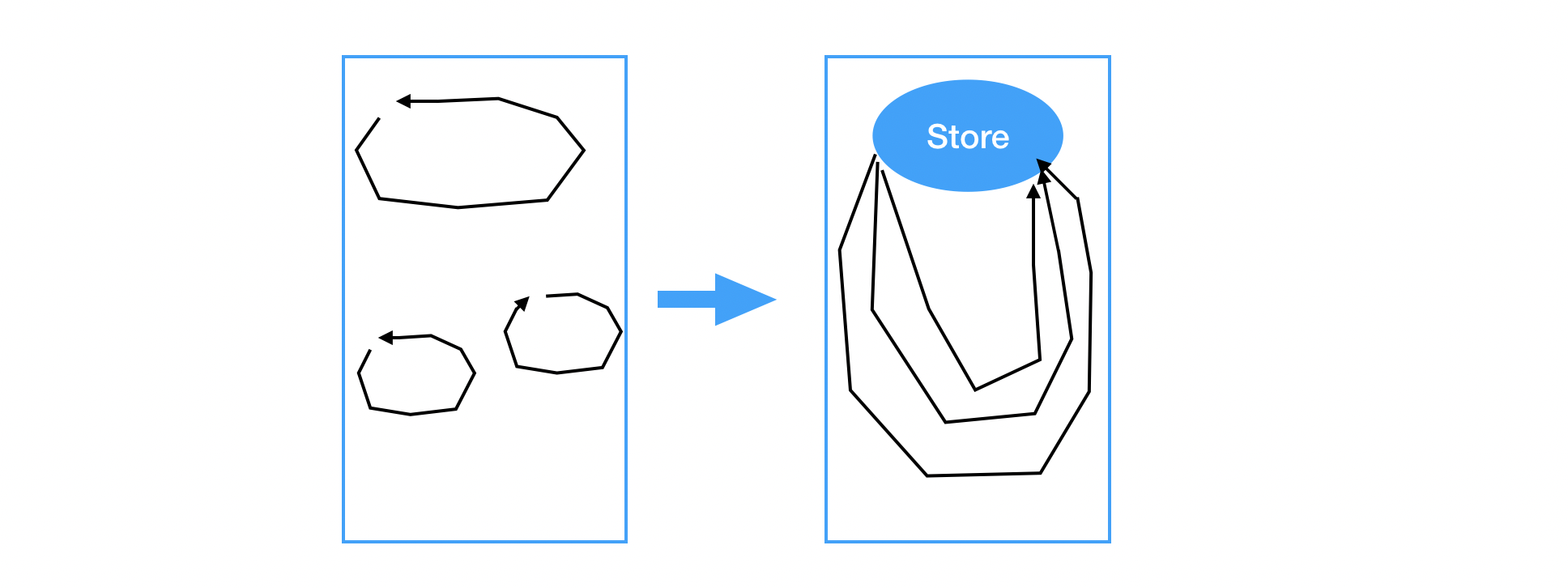
但是 Redux 也不是免费的,它带来两个我一直耿耿于怀的问题:
组件不能任意组合 组件连接 Redux 以后,即丧失了封闭性,如果页面上出现这样一个组件的两个实例,那这两个实例的状态就会互相影响。
割裂的逻辑 强行将逻辑拆成 action 和 reducer,一个功能要改3处代码,怎么看怎么蠢。
3. Maybe hooks?
较早前就听过 hooks,当时并不以为意,想着无非是给函数组件注入状态而已。数据和方法绑定,扒着指头数也就3种方式:
- 模块
- 类
- 闭包
类就挺直观的呀,干吗要要用闭包这种 tricky 方式去做?直到最近读文档,才发现这可能就是我一直心心念的 既要有清晰的数据流,又不割裂逻辑 的实现方式,抄 一段代码 感受感受:
class FriendStatusWithCounter extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0, isOnline: null };
this.handleStatusChange = this.handleStatusChange.bind(this);
}
componentDidMount() {
document.title = `You clicked ${this.state.count} times`;
ChatAPI.subscribeToFriendStatus(
this.props.friend.id,
this.handleStatusChange
);
}
componentDidUpdate() {
document.title = `You clicked ${this.state.count} times`;
}
componentWillUnmount() {
ChatAPI.unsubscribeFromFriendStatus(
this.props.friend.id,
this.handleStatusChange
);
}
handleStatusChange(status) {
this.setState({
isOnline: status.isOnline
});
}
// ...
function FriendStatusWithCounter(props) {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
const [isOnline, setIsOnline] = useState(null);
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(props.friend.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.friend.id, handleStatusChange);
};
});
// ...
}
看,hooks 能不受 class 组件生命周期钩子的限制,将逻辑相关的代码集中到一起了!
4. 其他
state 里该放什么数据 由于我们使用 state 的本质是利用框架的自动更新 DOM 的能力,因此 state 里只需放 界面相关 的数据。
Redux 里该放什么数据 Redux 的职责更多是数据管理,开发实践中,随业务迭代接口数据变动会比较频繁,适宜放 Redux 中;另外跨组件共享的数据也要放 Redux 中。总结起来就是 界面相关 && (服务端的 || 共享的) 应该放 Redux 中。
那岂不是和数据全貌相差太大了 只把界面相关的数据放 state 和 redux 里,会不会与业务数据全貌相差太大了呢?我认为不会,在后端“读写分离”的实践中,一般做法只是将查询和写入的服务放到不同的实例上,而更进一步的做法是 查询用的表和写入用的表都是不一样的!state 和 Redux 就是类似这样的读模型;界面无关的数据,完全可以再放到一个公共模块里。
作者:杨少军

- 当前前端发展演进的思考
- 关于大型网站技术演进的思考(二十)--网站静态化处理—web前端优化—中(12)
- 关于大型网站技术演进的思考(二十一)--网站静态化处理—web前端优化—下【终篇】(13)
- 关于大型网站技术演进的思考(二十一)--网站静态化处理—web前端优化—下【终篇】(13)
- 关于大型网站技术演进的思考(二十)--网站静态化处理—web前端优化—中(12)
- 关于大型网站技术演进的思考(十九)--网站静态化处理—web前端优化—上(11)
- 关于大型网站技术演进的思考(十九)--网站静态化处理—web前端优化—上(11)
- 关于大型网站技术演进的思考(十九)--网站静态化处理―web前端优化―上(11)
- 关于大型网站技术演进的思考(二十)--网站静态化处理―web前端优化―中(12)
- 关于大型网站技术演进的思考(十九)--网站静态化处理—web前端优化—上(11)
- 关于大型网站技术演进的思考(二十一)--网站静态化处理—web前端优化—下【终篇】(13)
- 关于大型网站技术演进的思考(二十一)--网站静态化处理―web前端优化―下【终篇】(13)
- 关于大型网站技术演进的思考(二十)--网站静态化处理—web前端优化—中(12)
- 关于大型网站技术演进的思考(二十)--网站静态化处理—web前端优化—中(12)
- 关于大型网站技术演进的思考(二十一)--网站静态化处理—web前端优化—下【终篇】(13)
- 关于大型网站技术演进的思考(二十):网站静态化处理—web前端优化—中(12)
- 关于大型网站技术演进的思考(二十一):网站静态化处理—Web前端优化(下)(13)
- 关于大型网站技术演进的思考(十九)--网站静态化处理—web前端优化—上(11)
- 关于大型网站技术演进的思考(一)--存储的瓶颈(1)
- 一个web前端程序员对于职业规划道路的思考