python入门之jieba库的使用
2019-10-18 18:52
141 查看
对于一段英文,如果希望提取其中的的单词,只需要使用字符串处理的split()方法即可,例如“China is a great country”。


然而对于中文文本,中文单词之间缺少分隔符,这是中文及类似语言独有的“分词问题”。
jieba(“结巴”)是python中一个重要的第三方中文分词函数库。jieba库是第三方库,不是python安装包自带的,因此,需要通过pip指令安装。
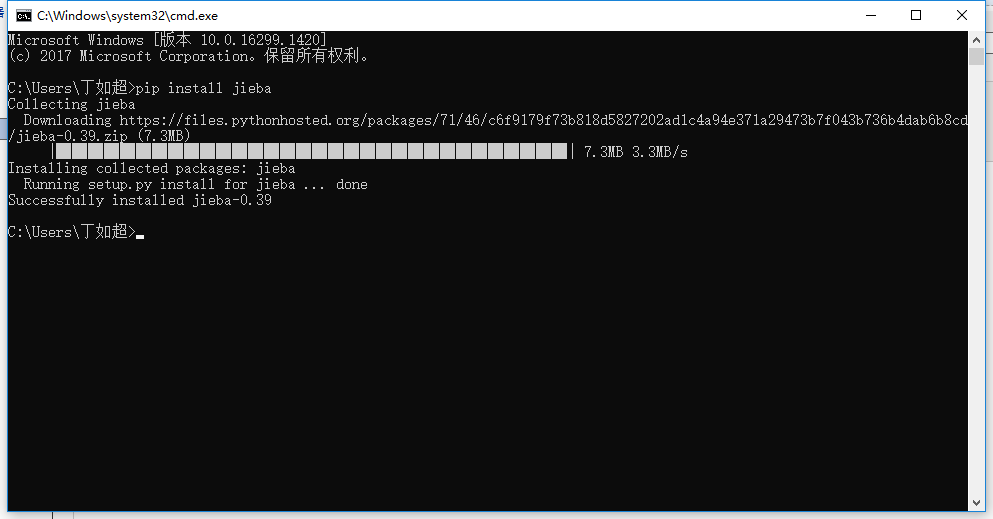
Windows 下使用命令安装:在联网状态下,在命令行下输入
pip install jieba进行安装,安装完成后会提示安装成功 。
- jieba分词的三种模式
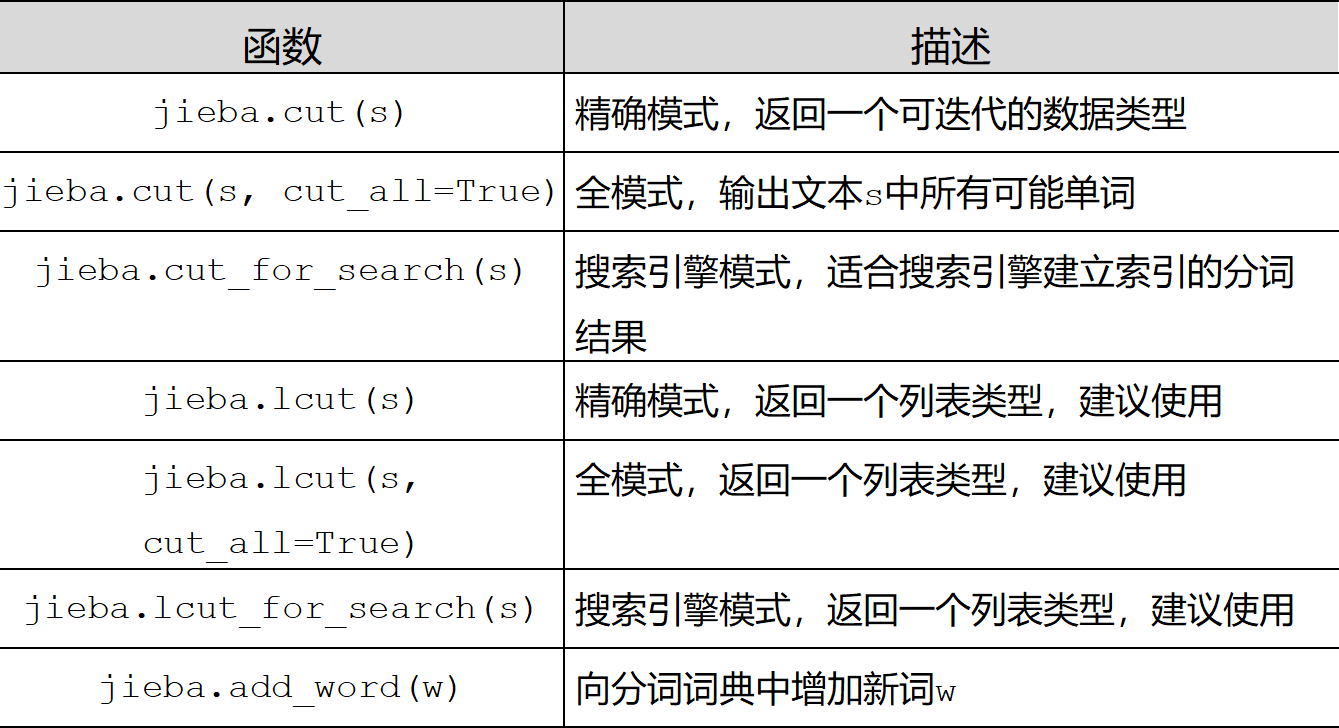
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
- jieba库常用函数
- 举例如下
jieba._lcut("中华人民共和国是一个伟大的国家")
jieba._lcut("中华人民共和国是一个伟大的国家",cut_all=True)
jieba._lcut_for_search("中华人民共和国是一个伟大的国家")
运行结果:


相关文章推荐
- Python个人快速入门学习(九)jieba库的使用
- python PyQt4库使用入门
- Android入门之旅5—使用Python脚本开发Android应用
- Protocol Buffers的安装使用和C++/Python入门示例
- ZODB入门 -- 如何通过面向对象的动态语言 Python 使用对象数据库
- Python中一些自然语言工具的使用的入门教程
- Python 爬虫入门(二)—— IP代理使用
- 12步入门Python中的decorator装饰器使用方法
- [Python]第三方库-Scrapy入门使用
- 使用Python开发windows GUI程序入门实例
- 使用Python中的greenlet包实现并发编程的入门教程
- Python入门基础-easygui的使用_fileopenbox()的使用
- Python爬虫入门(6):Cookie的使用
- 转 Python爬虫入门三之Urllib库的基本使用
- Python爬虫入门一之Urllib库的基本使用
- Python的ORM框架Peewee使用入门(三)
- 安装内容[Python]第三方库-Scrapy入门使用
- python基础教程之简单入门说明(变量和控制语言使用方法)
- python安装与使用入门
- python入门基础教程03 Python开发环境基本使用