PythonCrawler 13day02
Python crawler Day02
第一天对爬虫的概念有所了解,从简单的爬虫开始学起来,以下是今天的知识点总结,千里之行始于足下!
爬取数据—urlllib库
爬虫步骤 :
网页抓取,数据提取,数据存储
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 在Python中有很多库可以用来抓取网页 ,Python urllib 库提供了一个从指定的 URL 地址获取网页数据,然后对其进行分析处理,获取想要的数据。
一、urllib模块urlopen()函数:
urlopen(url, data=None, proxies=None)
创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
参数url表示远程数据的路径,一般是网址;
参数data表示以post方式提交到url的数据(提交数据的两种方式:post与get,后面会讲到这个);
参数proxies用于设置代理。
urlopen返回 一个类文件对象(fd),它提供了如下方法:
**read() , readline() , readlines() , fileno() , close() **:这些方法的使用方式与文件对象完全一样;
info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息(header)
getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到;
geturl():返回请求的url;
urllib是一个URL处理包,这个包中集合了一些处理URL的模块
1.urllib.request模块是用来打开和读取URLs的;
2.urllib.error模块包含一些有urllib.request产生的错误,可以使用try进行捕捉处理;
3.urllib.parse模块包含了一些解析URLs的方法;
4.urllib.robotparser模块用来解析robots.txt文本文件.它提供了一个单独的RobotFileP
arser类,通过该类提供的can_fetch()方法测试爬虫是否可以下载一个页面。
urllib.request.urlopen()
简单爬虫示例
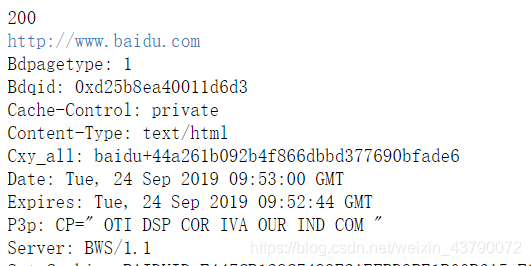
from urllib.request import urlopen#导入数据库 url = "http://www.baidu.com"#获取url response = urlopen(url) #发送请求 info = response.read() #读取内容 #print(info.decode()) #打印内容 print(response.getcode()) #打印状态码 print(response.geturl()) #打印真实url print(response.info()) #打印响应头
输出结果为:
Request对象的使用
我们知道利用urlopen()方法可以实现最基本请求的发起,但这几个简单的参数并不足以构建一个完整的请求。如果请求中需要加入Headers等信息,就可以利用更强大的Request类来构建。
我们依然用urlopen()方法来发送请求,只不过这次的参数不再是URL,而是一个Request类型的对象。通过构造这个数据结构,一方面我们可以将请求独立成一个对象,另一方面可更加丰富和灵活地配置参数。
Request的构造方法如下:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
url用于请求URL,这是必传参数,其他都是可选参数。 data如果要传,必须传bytes(字节流)类型的。如果它是字典,可以先用urllib.parse模块里的urlencode()编码。 headers是一个字典,它就是请求头,我们可以在构造请求时通过headers参数直接构造,也可以通过调用请求实例add_header()方法添加。
User Agent
浏览器就是互联网世界上公认被允许的身份,如果我们希望我们的爬虫程序更像一个真实用户,那我们第一步,就是需要伪装成一个被公认的浏览器。用不同的浏览器在发送
请求的时候,会有不同的 User-Agent 头。中文名为用户代理,简称UA
User Agent存放于Headers中
服务器就是通过查看Headers中的User Agent来判断是谁在访问。
urllib中默认的User Agent,会有Python的字样,如果服务器检查User Agent,可以拒绝Python程序访问网站。
设置User Agent
方法 1:在创建 Request 对象的时候,填入 headers 参数(包含 User Agent 信息),这个
Headers参数要求为字典;
方法2:在创建Request对象的时候不添加headers参数,在创建完成之后,使用add_header()的方法,添加headers,所以我们加下请求设备头,这个在哪里呢?

添加请求头最常用的用法就是通过修改User-Agent来伪装浏览器,默认的User-Agent是Python-urllib,我们可以通过修改它来伪装浏览器。简单实例如下:
from urllib.request import urlopen
from urllib.request import Request
#Request对象的使用
url = "http://www.baidu.com"
#伪装头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3887.7 Safari/537.36"
}
request = Request(url,headers=headers)
response = urlopen(request)
#读取内容
info = response.read()
#转码
print(info.decode())
get、post请求的使用
requests请求分为get请求和post请求。
Get请求:大部分被传输到浏览器的html,image,js…等都是通过Get方法发出请求的,他是获取数据的主要方法。例如(http://www.baidu.com)搜索
Get请求的参数都是在URL中体现的,如果有中文,需要转码,这时我们可以使用
- urllib.parse.urlencode()
- urllib.parse.quote()
get请求的常用参数包括:
url=self.url,params=data,headers=self.headers
url -->请求的路径地址(字符串类型)
params–>请求的参数(字典类型)
headers–>设置请求头(字典类型,常常用来设置User-Agent,模拟浏览器登录)
proxies–>设置请求代理(字典类型,格式{‘http’:‘host:port’}或者{‘http’:[‘host1:port1’,‘host2:port2’,…]})
带参数的get请求(两种方式是等效的)简单实例如下:
import requests
response = requests.get("http://httpbin.org/get?name=germey&age=22")
print(response.text)
########################
import requests
data = {
'name': 'germey',
'age': 22
}
response = requests.get("http://httpbin.org/get", params=data)
print(response.text)
// params=data 对于get请求 添加附加的格外的信息,这个信息一般用字典来存储,
可见返回的结果中args字段
输出结果如下:

Post请求:
上面我们说了Request请求对象的里有data参数,它就是用在POST里的,我们要传送的数据就是这个参数data,data是一个字典,里面要匹配键值对。
post请求的常用参数包括(与get的不同在于请求参数的表示不同,post用data,get用params):
url -->请求的路径地址(字符串类型)
data–>请求的参数(字典类型)
headers–>设置请求头(字典类型,常常用来设置User-Agent,模拟浏览器登录)
proxies–>设置请求代理(字典类型,格式{‘http’:‘host:port’}或者{‘http’:[‘host1:port1’,‘host2:port2’,…]})
post请求实例:
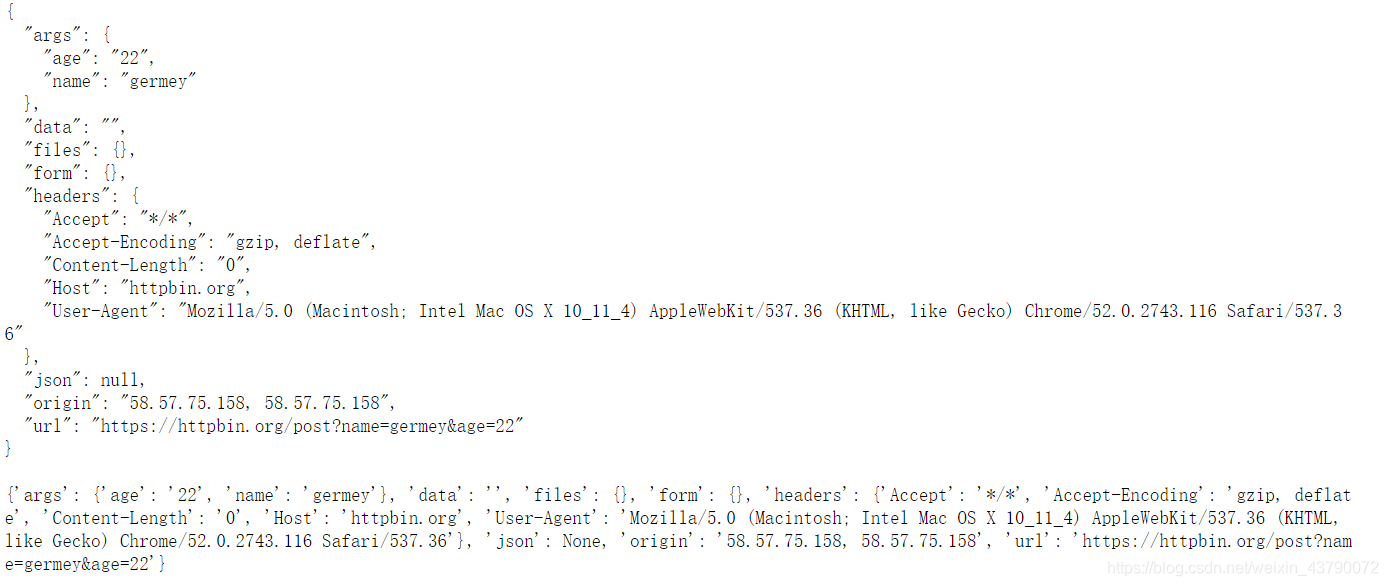
import requests
data = {'name': 'germey', 'age': '22'}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
response = requests.post("http://httpbin.org/post", params=data, headers=headers)
print(response.text)
print(response.json())
// params=data 对于get请求 添加附加的格外的信息,这个信息一般用字典来存储,
可见返回的结果中args字段
输出结果为:
get 和 post请求的区别:
Get:请求的url会附带查询参数
Post:请求的url不带参数
对于Get请求:查询参数在QueryString里保存
对于Post请求:查询参数在From表单里保存
贴吧小案例
#!/usr/bin/env python
# -*-coding:utf-8 -*-
# from urllib.requset import Request,urlopen
import requests
from urllib.request import urlopen
from urllib.parse import urlencode
from fake_useragent import UserAgent
def get_html(url):
headers = {
"User-Agent":UserAgent().chrome
}
request = requests.get(url,headers=headers)
response = urlopen(request)
print(response.read().decode())
return response.read()
def save_html(filename,html_bytes):
with open(filename,"wb") as f:
f.write(html_bytes)
def main():
content = input("请输入要下载的内容:")
num = input("请输入要下载多少页:")
base_url = "http://tieba.baidu.com/f?ie=utf-8"
for pn in range(int(num)):
args = {
"pn":pn * 50,
"kw":content
}
filename = "第" + str(pn + 1) + "页.html"
args = urlencode(args)
print("正在下载" + filename)
html_bytes = get_html(base_url.format(args))
save_html(filename,html_bytes)
if __name__ == '__main__':
main()
故不积跬步无以至千里不积小流无以成江河

- Py之Crawler:利用python尝试获取cn-proxy代理的IP地址——Jason niu
- Python crawler 豆瓣电影排行榜评分
- python crawler(1)
- Python crawler(二):BeautifulSoup的安装及使用
- python crawler(1)
- Simple Web Crawler Used Python
- 1.1爬虫基础——什么是网络爬虫(python crawler)
- python crawler(2)
- Python crawler(一):urllib的三种下载网页方法
- python错误解决:SyntaxError: Non-ASCII character '\xd3' in file crawler.py
- a summary of python crawler
- python-crawler
- [原创] Demo: Python crawler use chrome headless - pyppeteer
- Python-crawler-citeulike
- python crawler
- Crawler in python
- python yellow page thread crawler
- Python crawler based on python 3
- PythonWebCrawler-模拟浏览器爬取信息
- 76 python.crawler