python scrapy 报错 DEBUG: Ignoring response 403
2019-09-17 17:17
295 查看
【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>>

解决方案:
防止反爬机制,伪装user_agent
步骤:
(1). 打开默认浏览器
(2). F12 打开控制台->刷新页面 ->Network->请求头部找到 User-Agent
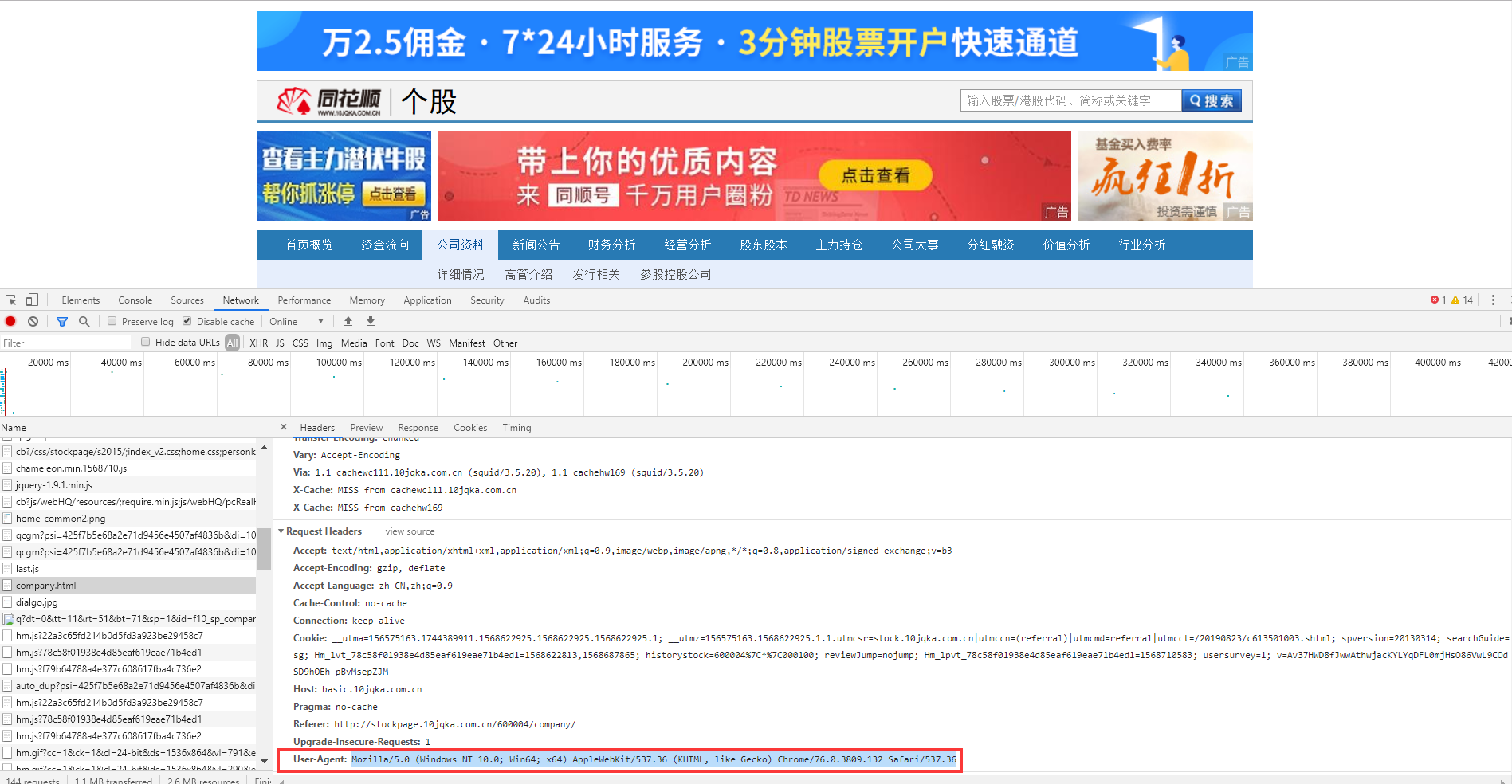
(3). 在scrapy项目中找到settings.py的 USER_AGENT = ' ' (把注释去掉,加以下内容,依据自己浏览器而定)
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36
(4). 重新启动scrapy即可

相关文章推荐
- python scrapy 报错 DEBUG: Ignoring response 403
- python scrapy 出现no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicate
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
- Python快速开发分布式搜索引擎Scrapy精讲—Requests请求和Response响应介绍
- [scrapy.spidermiddlewares.httperror] INFO: Ignoring respons 403...HTTP status code is not handled..
- 在Linux系统上安装Python的Scrapy框架的教程
- Python抓取框架 Scrapy的架构
- 安装scrapy报错 Python.h: 没有那个文件或目录
- 如何让 scrapy 不忽略 403的响应
- Python爬虫框架Scrapy获得定向打击批量招聘信息
- python笔记 基础语法·第11课【debug四种方式,try...except语句】
- 关于python无法安装Scrapy解决方案
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- pip install scrapy报错:error: Unable to find vcvarsall.bat解决方法(python scrapy安装windows下)
- (转)python爬虫----(scrapy框架提高(1),自定义Request爬取)
- python处理scrapy抓取生成的json数据遇到的问题
- python3 scrapy+Crontab部署过程
- 关于python scrapy的安装一个问题 No Moudle named cssselect
- python multiprocessing debug
- 【python爬虫】scrapy框架笔记(一):创建工程,使用scrapy shell,xpath