YARN底层基础库
2019-08-30 16:39
357 查看
YARN基础库是其他一切模块的基础,它的设计直接决定了YARN的稳定性和扩展性,YARN借用了MRV1的一些底层基础库,比如RPC库等,但因为引入了很多新的软件设计方式,所以它的基础库更多,包括直接使用了开源序列化框架Protocol Buffers和Apache Avro,自定义的服务库、事件库和状态机等
目录 一. 概述 二. Protocol Buffers 三. Apache Avro
四. 底层通信库
五. 服务库与事件库 六. 状态机库
一. 概述 Yarn基础库是其他一切模块的基础,它的设计直接决定了Yarn的稳定性和扩展性 Yarn的基础库主要有 :
YARN提供的对外类是Yarn RPC,用户只需使用该类便可以构建一个基于HadoopRPC且采用Protocol Buffers序列化框架的通信协议 五. 服务库与事件库 服务库 对于生命周期较长的对象,YARN采用了基于服务的对象管理模型对其进行管理,该模型主要有以下几个特点 :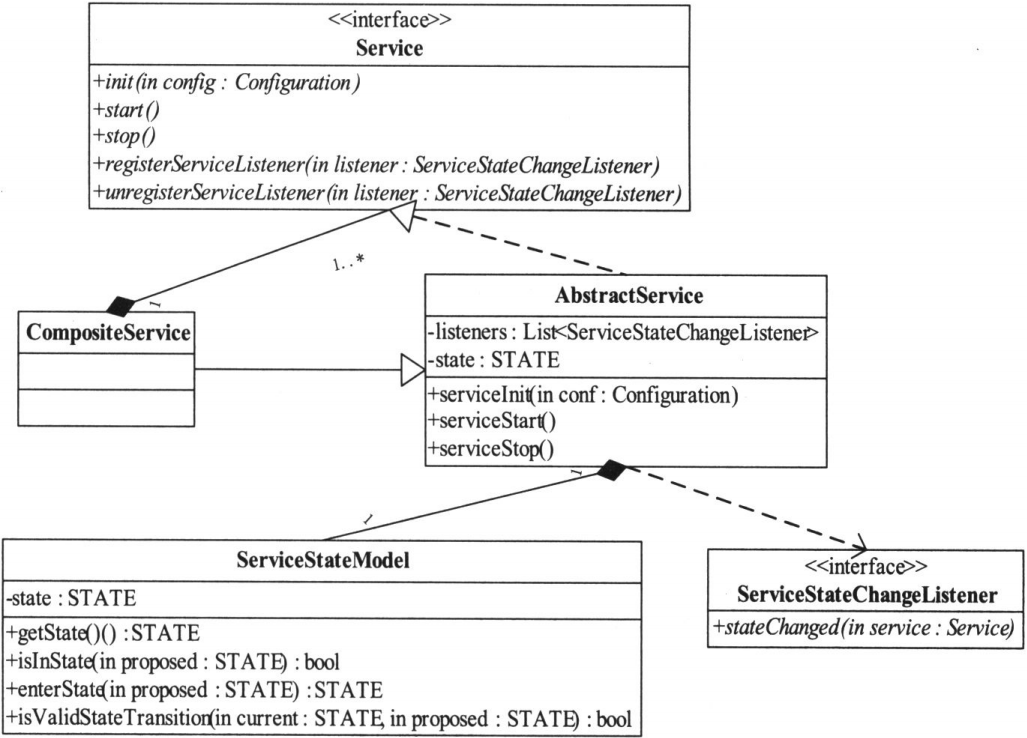 YARN中服务模型的类图
YARN中,RM和NM属于组合服务,它们内部包含多个单一服务和组合服务,以实现对内部多种服务的统一管理
事件库
YARN采用了基于事件驱动的并发模型,该模型能够大大增强并发性,从而提高系统整体性能。为了构建该模型,YARN将各种处理逻辑抽象成事件和对应事件调度器,并将每类事件的处理过程分割成多个步骤,用有限状态机表示
YARN中服务模型的类图
YARN中,RM和NM属于组合服务,它们内部包含多个单一服务和组合服务,以实现对内部多种服务的统一管理
事件库
YARN采用了基于事件驱动的并发模型,该模型能够大大增强并发性,从而提高系统整体性能。为了构建该模型,YARN将各种处理逻辑抽象成事件和对应事件调度器,并将每类事件的处理过程分割成多个步骤,用有限状态机表示
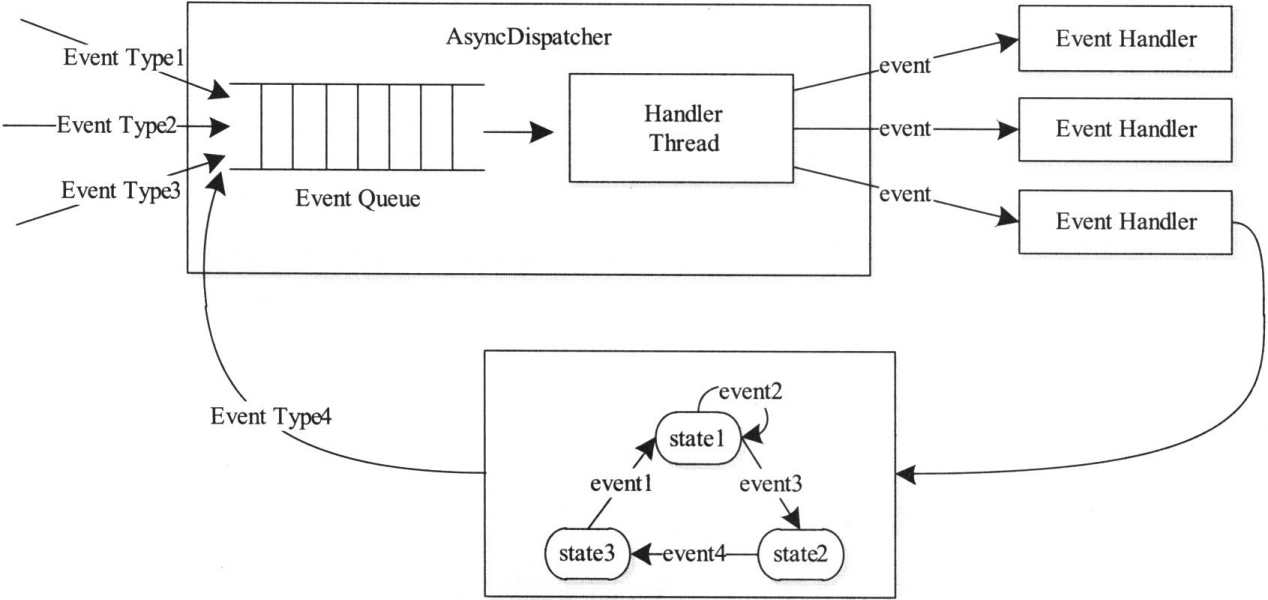 YARN的事件处理模型
整个处理过程大致为 :处理请求会作为事件进入系统,由中央异步调度器(AsyncDispatcher)负责传递给相应事件调度器(Event Handler)。该事件调度器可能将该事件转发给另外一个事件调度器,也可能交给一个带有有限状态机的事件处理器,其处理结果也以事件的形式输出给中央异步调度器。而新的事件会再次被中央异步调度器转发给下一个事件调度器,直至处理完成(达到终止条件)
YARN中,所有核心服务实际上都是一个中央异步调度器,包括RM、NM和AppMaster等,它们维护了事先注册的事件与事件处理器,并根据接收的事件类型驱动服务的运行
使用YARN事件库时,通常先定义一个中央异步调度器,负责事件的转发与处理,然后根据实际业务需求定义一系列的事件与事件处理器,并注册到中央异步调度器实现事件统一管理和调度。以MRAppMaster为例,它内部包含一个中央异步调度器,并注册了TaskAttemptEvent/TaskAttemptImpl、TaskEvent/TaskImpl、JobEvent/JobImpl等一系列事件/事件处理器,由中央异步调度器统一管理和调度
服务化和事件驱动软件设计思想的引入,使得YARN具有低耦合、高内聚的特点,各个模块只需完成各自功能,而模块之间则采用事件联系起来,系统设计简单且维护方便
YARN服务库和事件库的使用
YARN服务库和事件库的使用方法,介绍一个简单的实例,该例子涉及任务和作业两种对象的事件以及一个中央异步调度器
(1) 定义Task事件
YARN的事件处理模型
整个处理过程大致为 :处理请求会作为事件进入系统,由中央异步调度器(AsyncDispatcher)负责传递给相应事件调度器(Event Handler)。该事件调度器可能将该事件转发给另外一个事件调度器,也可能交给一个带有有限状态机的事件处理器,其处理结果也以事件的形式输出给中央异步调度器。而新的事件会再次被中央异步调度器转发给下一个事件调度器,直至处理完成(达到终止条件)
YARN中,所有核心服务实际上都是一个中央异步调度器,包括RM、NM和AppMaster等,它们维护了事先注册的事件与事件处理器,并根据接收的事件类型驱动服务的运行
使用YARN事件库时,通常先定义一个中央异步调度器,负责事件的转发与处理,然后根据实际业务需求定义一系列的事件与事件处理器,并注册到中央异步调度器实现事件统一管理和调度。以MRAppMaster为例,它内部包含一个中央异步调度器,并注册了TaskAttemptEvent/TaskAttemptImpl、TaskEvent/TaskImpl、JobEvent/JobImpl等一系列事件/事件处理器,由中央异步调度器统一管理和调度
服务化和事件驱动软件设计思想的引入,使得YARN具有低耦合、高内聚的特点,各个模块只需完成各自功能,而模块之间则采用事件联系起来,系统设计简单且维护方便
YARN服务库和事件库的使用
YARN服务库和事件库的使用方法,介绍一个简单的实例,该例子涉及任务和作业两种对象的事件以及一个中央异步调度器
(1) 定义Task事件
 初始状态:最终状态:事件=1:1:1
(2) 一个初始状态、多个最终状态、一种事件。该方式表示状态机在preState状态下,接收到Event事件后,执行函数状态转移函数Hook,并将当前状态转移为Hook的返回值所表示的状态
初始状态:最终状态:事件=1:1:1
(2) 一个初始状态、多个最终状态、一种事件。该方式表示状态机在preState状态下,接收到Event事件后,执行函数状态转移函数Hook,并将当前状态转移为Hook的返回值所表示的状态
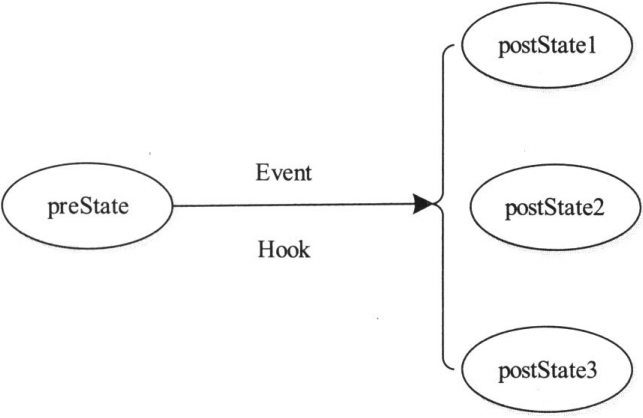 初始状态:最终状态:事件=1:N:1
(3) 一个初始状态、一个最终状态、多个事件。该方式表示状态机在preState状态下,接收到Event1、Event2和Event3中的任何一个事件,将执行函数状态转移函数Hook,并在执行完成后将当前状态转换成postState
初始状态:最终状态:事件=1:N:1
(3) 一个初始状态、一个最终状态、多个事件。该方式表示状态机在preState状态下,接收到Event1、Event2和Event3中的任何一个事件,将执行函数状态转移函数Hook,并在执行完成后将当前状态转换成postState
 初始状态:最终状态:事件=1:1:N
状态机类
YARN自己实现了一个非常简单的状态机库(位于包org.apache.hadcop.yarn.state中)。YARN对外提供了一个状态机工厂StatemachineFactory,它提供多种addTransition方法供用户添加各种状态转移,一旦状态机添加完毕后,可通过调用installTopology完成一个状态机的构建
我每天会写文章记录大数据技术学习之路,另外我自己整理了些大数据的学习资料,目前全部放在我的公众号"SmallBird技术分享",加入我们一起学习交流,并且回复'分享'会有大数据资源惊喜等着你~
初始状态:最终状态:事件=1:1:N
状态机类
YARN自己实现了一个非常简单的状态机库(位于包org.apache.hadcop.yarn.state中)。YARN对外提供了一个状态机工厂StatemachineFactory,它提供多种addTransition方法供用户添加各种状态转移,一旦状态机添加完毕后,可通过调用installTopology完成一个状态机的构建
我每天会写文章记录大数据技术学习之路,另外我自己整理了些大数据的学习资料,目前全部放在我的公众号"SmallBird技术分享",加入我们一起学习交流,并且回复'分享'会有大数据资源惊喜等着你~
目录 一. 概述 二. Protocol Buffers 三. Apache Avro
四. 底层通信库
五. 服务库与事件库 六. 状态机库
一. 概述 Yarn基础库是其他一切模块的基础,它的设计直接决定了Yarn的稳定性和扩展性 Yarn的基础库主要有 :
- Protocol Buffers : Protocol Buffers是Google开源的序列化库,具有平台无关,高性能,兼容好等优点.Yarn将ProtocolBuffers用到RPC通信中,默认情况下,Yarn RPC中所有参数采用Protocol Buffers进行序列化/反序列化
- Apache Avro : Avro是Hadoop生态系统中的RPC框架,具有平台无关,支持动态模式等优点,Avro的最初设计动机是解决Yarn RPC兼容性和扩展性差等问题
- RPC库 : Yarn采用MR1中的RPC库,但其中采用的默认序列化方法被替换成了Protocol Buffers
- 服务库和事件库 : Yarn将所有的对象服务化,以便统一管理(创建,销毁等),而服务之间则采用事件机制进行通信
- 状态机库 : 状态机是一种表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型
- 平台无关,语言无关
- 高性能,解析速度是XML的20 ~ 100倍
- 体积小,文件大小仅是XML的1/10 ~ 1/3
- 使用简单
- 兼容性好
- 丰富的数据结构类型
- 快速可压缩的二进制数据形式
- 存储持久数据的文件容器
- 提供远程过程调用RPC
- 简单的动态语言结合功能
- 支持动态模式。Avro不需要生成代码,有利于搭建通用的数据处理系统,避免了代码入侵
- 数据无需加标签
- 无需手工分配的域标识
YARN提供的对外类是Yarn RPC,用户只需使用该类便可以构建一个基于HadoopRPC且采用Protocol Buffers序列化框架的通信协议 五. 服务库与事件库 服务库 对于生命周期较长的对象,YARN采用了基于服务的对象管理模型对其进行管理,该模型主要有以下几个特点 :
- 将每个被服务化的对象分为4个状态 : NOTINITED(被创建),INITED(已初始化),STARTED(已启动),STOPPED(已停止)
- 任何服务状态变化都可以触发另外一些动作
- 可通过组合的方式对任意服务进行组合,以便进行统一管理
YARN中服务模型的类图
YARN中,RM和NM属于组合服务,它们内部包含多个单一服务和组合服务,以实现对内部多种服务的统一管理
事件库
YARN采用了基于事件驱动的并发模型,该模型能够大大增强并发性,从而提高系统整体性能。为了构建该模型,YARN将各种处理逻辑抽象成事件和对应事件调度器,并将每类事件的处理过程分割成多个步骤,用有限状态机表示
YARN的事件处理模型
整个处理过程大致为 :处理请求会作为事件进入系统,由中央异步调度器(AsyncDispatcher)负责传递给相应事件调度器(Event Handler)。该事件调度器可能将该事件转发给另外一个事件调度器,也可能交给一个带有有限状态机的事件处理器,其处理结果也以事件的形式输出给中央异步调度器。而新的事件会再次被中央异步调度器转发给下一个事件调度器,直至处理完成(达到终止条件)
YARN中,所有核心服务实际上都是一个中央异步调度器,包括RM、NM和AppMaster等,它们维护了事先注册的事件与事件处理器,并根据接收的事件类型驱动服务的运行
使用YARN事件库时,通常先定义一个中央异步调度器,负责事件的转发与处理,然后根据实际业务需求定义一系列的事件与事件处理器,并注册到中央异步调度器实现事件统一管理和调度。以MRAppMaster为例,它内部包含一个中央异步调度器,并注册了TaskAttemptEvent/TaskAttemptImpl、TaskEvent/TaskImpl、JobEvent/JobImpl等一系列事件/事件处理器,由中央异步调度器统一管理和调度
服务化和事件驱动软件设计思想的引入,使得YARN具有低耦合、高内聚的特点,各个模块只需完成各自功能,而模块之间则采用事件联系起来,系统设计简单且维护方便
YARN服务库和事件库的使用
YARN服务库和事件库的使用方法,介绍一个简单的实例,该例子涉及任务和作业两种对象的事件以及一个中央异步调度器
(1) 定义Task事件
public class TaskEvent extends AbstractEvent<TaskEventType> {
private String taskID;
public TaskEvent (String taskID, TaskEventType type) {
super(type);
this.taskID = taskID;
}
public String getTaskID() {
return taskID;
}
}
// Task事件类型定义
public enum TaskEventType {
T_KILL,
T_SCHEDULE
}
(2) 定义Job事件
public class JobEvent extends AbstractEvent<JobEventType> {
private String jobID;
public JobEvent (String jobID, JobEventType type) {
super(type);
this.jobID = jobID;
}
}
//Job事件类型定义
public enum JobEventType {
JOB_KILL,
JOB_INIT,
JOB_START
}
(3) 事件调度器
定义一个中央异步调度器,它接收Job和Task两种类型事件,并交给对应的事件处理器处理
@SuppressWarnings("unchecked")
public class SimpleMRAppMaster extends CompositeService {
private Dispatcher dispatcher; //中央异步调度器
private String jobID;
private int taskNumber; //该作业包含的任务数目
private String[] taskIDs; //该作业内部包含的所有任务
public SimpleMRAppMaster (String name, String jobID, int taskNumber) {
super(name);
this.jobID = jobID;
this.taskNumber = taskNumber;
taskIDs = new String[taskNumber];
for (int i = 0; i < taskNumber; i++) {
taskIDs[i] = new String (jobID + "_task_" + i);
}
}
public void serviceInit (final Configuration conf) throws Exception {
dispatcher = new AsyncDispatcher(); //定义一个中央异步调度器
//分别注册Job和Task事件调度器
dispatcher.register(JobEventType.class, new JobEventDispatcher());
dispatcher.register(TaskEventType.class, new TaskEventDispatcher());
addService((Service)dispatcher);
super.serviceInit(conf);
}
public Dispatcher getDispatcher() {
return dispatcher;
}
private class JobEventDispatcher implements EventHandler<JobEvent> {
@Override
public void handle (JobEvent event) {
if (event.getType() == JobEventType.JOB_KILL) {
System.out.println("Receive JOB_KILL event, killing all the tasks");
for (int i = 0; i < taskNumber; i++) {
dispatcher.getEventHandler().handle(new TaskEvent(taskIDs[i], TaskEventType.T_KILL));
}
} else if (event.getType() == JobEventType.JOB_INIT) {
System.out.println("Receive JOB_INIT event, scheduling tasks");
for (int i = 0; i < taskNumber; i++) {
dispatcher.getEventHandler().handle(new TaskEvent(taskIDs[i], TaskEventType.T_SCHEDULE));
}
}
}
}
private class TaskEventDispatcher implements EventHandler<TaskEvent> {
@Override
public void handler (TaskEvent event) {
if (event.getType() == TaskEventType.T_KILL) {
System.out.println("Receive T_KILL event of task" + event.getTaskID());
} else if (event.getType() == TaskEventType.T_SCHEDULE) {
System.out.println("Receive T_SCHEDULE of task" + event.getTaskID());
}
}
}
}
(4). 测试程序
@SuppressWarnings("unchecked")
public class SimpleMRAppMasterTest {
public static void main (String[] args) throws Exception {
String jobID = "job_20131215_12";
SimpleMRAppMaster appMaster = new SimpleMRAppMaster("Simple MRAppMaster", jobID, 5);
YarnConfiguration conf = new YarnConfiguration(new Configuration());
appMaster.serviceInit(conf);
appMaster.serviceStart();
appMaster.getDispatcher().getEventHandler().handle(new JobEvent(jobID, JobEventType.JOB_KILL));
appMaster.getDispatcher().getEventHandler().handle(new JobEvent(jobID, JobEventType.JOB_INIT));
}
}
事件驱动带来的变化
MRV1中,对象之间的作用关系是基于函数调用实现的,当一个对象向另外一个对象传递消息时,会直接采用函数调用的方式,且整个过程是串行的
基于函数调用的编程模型时低效的,它隐含着整个过程是串行、同步进行的。MRV2引入了事件驱动编程模型是一种更加高效的方式。
在基于事件驱动的编程模型中,所有对象被抽象成了事件处理器,而事件处理器之间通过事件相互关联。 每种事件处理器处理一种类型的事件,同时根据需要触发另外一种事件
相比于基于函数调用的编程模型,这种编程模型具有异步、并发等特点,更加高效,因此更适合大型分布式系统
六. 状态机库
状态机由一组状态组成,这些状态分为三类:初始状态、中间状态和最终状态。状态机从初始状态开始运行,经过一系列中间状态后,到达最终状态并退出。在一个状态机中,每个状态都可以接收一组特定事件,并根据具体的事件类型转换到另一个状态。当状态机转换到最终状态时,则退出
YARN状态转换方式
YARN中,每种状态转换由一个四元组表示,分别是转换前状态(preState)、转换后状态(postState)、事件(event)和回调函数(hook)
YARN定义了三种状态转换方式 :
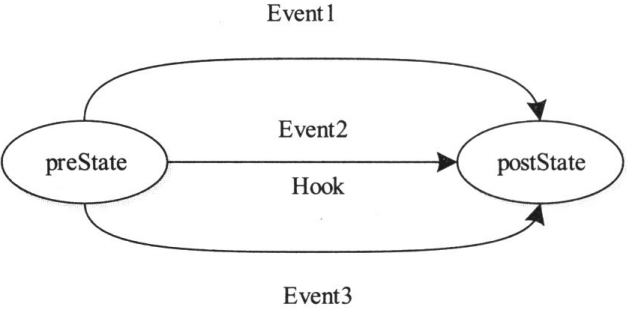
(1) 一个初始状态、一个最终状态、一种事件。该方式表示状态机在preState状态下,接收到Event事件后,执行函数状态转移函数Hook,并在执行完成后将当前状态转换为postState
初始状态:最终状态:事件=1:1:1
(2) 一个初始状态、多个最终状态、一种事件。该方式表示状态机在preState状态下,接收到Event事件后,执行函数状态转移函数Hook,并将当前状态转移为Hook的返回值所表示的状态
初始状态:最终状态:事件=1:N:1
(3) 一个初始状态、一个最终状态、多个事件。该方式表示状态机在preState状态下,接收到Event1、Event2和Event3中的任何一个事件,将执行函数状态转移函数Hook,并在执行完成后将当前状态转换成postState
初始状态:最终状态:事件=1:1:N
状态机类
YARN自己实现了一个非常简单的状态机库(位于包org.apache.hadcop.yarn.state中)。YARN对外提供了一个状态机工厂StatemachineFactory,它提供多种addTransition方法供用户添加各种状态转移,一旦状态机添加完毕后,可通过调用installTopology完成一个状态机的构建
我每天会写文章记录大数据技术学习之路,另外我自己整理了些大数据的学习资料,目前全部放在我的公众号"SmallBird技术分享",加入我们一起学习交流,并且回复'分享'会有大数据资源惊喜等着你~

相关文章推荐
- 音视频底层、即时通讯技术、音视频交互、跨平台基础
- Hadoop基础之YARN的工作流程
- 【0基础Python学习笔记02】-基础知识-网络底层基础
- linux 之 基础API底层执行过程
- php基础语法底层实现
- MyBatis底层基础和拦截器 - 第一部分
- java基础(八)-----java中的常量池技术(底层)
- USB学习笔记(一)------USB底层基础知识
- 操作系统虚拟化底层基础之命名空间(namespace)
- Yarn_基础
- Java底层基础类探索
- android底层开发-android基础架构
- Yarn的作业提交流程底层原理精讲【小二讲堂】
- Java中高级面试题—基础知识—2)HashMap的底层实现,之后会问ConcurrentHashMap的底层实现;
- 第一课:ARM底层开发笔记之ARM基础概念
- EF 底层基础方法
- Hadoop基础教程-第5章 YARN:资源调度平台(5.4 YARN集群运行)(草稿)
- Android-项目开发基础—JNI与底层调用(十三)
- 揭秘FaceBook Puma演变及发展——FaceBook公司的实时数据分析平台是建立在Hadoop 和Hive的基础之上,这个根能立稳吗?hive又是sql的Map reduce任务拆分,底层还是依赖hbase和hdfs存储
- MyBatis底层基础和拦截器 - 第一部分