python分析链家二手房信息----数据分析实战(一)
2019-08-18 21:50
357 查看
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/weixin_42492529/article/details/99709295
链家二手房信息
[code]# 导入需要的库:科学计算包numpy, pandas 可视化包matplotlib, seaborn 机器学习包 sklearnimport numpy as npimport pandas as pdimport matplotlib as mplimport seaborn as snsimport matplotlib.pyplot as plt from IPython.display import display# 可以在引入Matplotlib后通过运行plt.style.use(style_name)来修改绘图的风格。所有可用的风格在plt.style.available中列出。# 比如,尝试使用plt.style.use('fivethirtyeight')、plt.style.use('ggplot')或者plt.style.use('seaborn-dark')。# 为了更好玩,可以运行plt.xkcd(),然后尝试绘制一些别的图形。plt.style.use("fivethirtyeight")# 防止出现中文乱码,应修改 seabron 配置文件sns.set_style({'font.sans-serif':['simhei','Arial']})%matplotlib inline# 导入数据,并进行初步观察lianjia_df = pd.read_csv('lianjia.csv')display(lianjia_df.head())上传的数据形式如下:
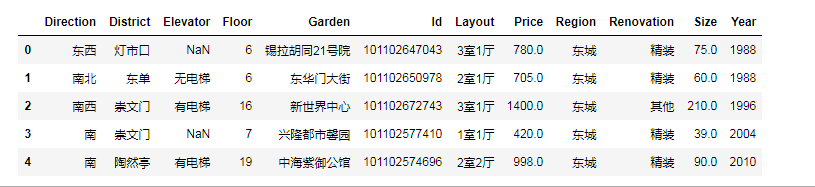
- Direction 方向
- District 地址
- Elevator 是否有电梯
- Floor 楼层
- Garden 家园
- Id ID
- Layout 布局
- Price 价格
- Region 地区
- Renovation 装修
- Size 面积
- Year 年份
[code]lianjia_df.info()
查看链家数据信息:
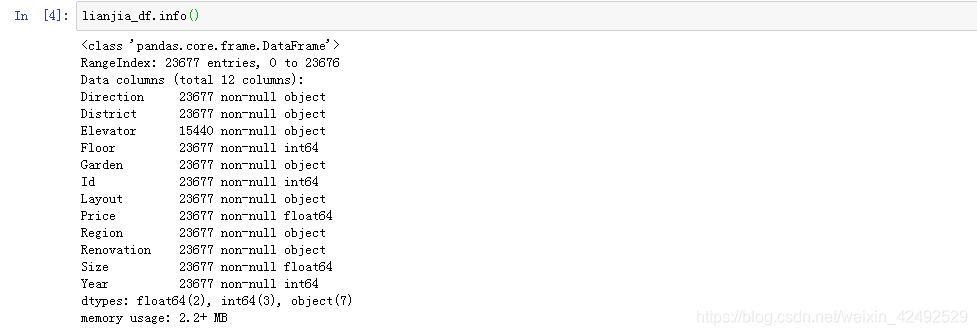
数据总共有23677条,Elevator 字段有缺失值。
[code]# 对数据进行描述性分析lianjia_df.describe()

[code]price 平均数 610标准差 411中位数 499最小值 60最大值 6000
这些统计结果简单直接,对于初始了解一个特征好坏非常有用,比如我们观察到 Size 特征 的最大值为1019平米,最小值为2平米,那么我们就要思考这个在实际中是不是存在的,如果不存在没有意义,那么这个数据就是一个异常值,会严重影响模型的性能。
[code]# 添加房屋均价df = lianjia_df.copy()df['PerPrice'] = round(lianjia_df['Price']/lianjia_df['Size'], 2)# 重新摆放列位置columns = ['Region', 'District', 'Garden', 'Layout', 'Floor', 'Year', 'Size', 'Elevator', 'Direction', 'Renovation', 'PerPrice', 'Price']df = pd.DataFrame(df, columns =columns)df.head()
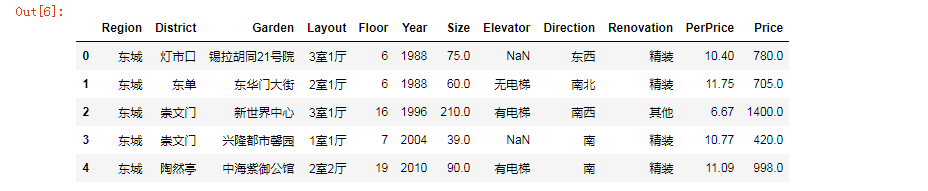
ID没有什么用,我们将其移除,房屋单价分析比较简单,价格/总面积,所以增加一个特征PerPrice.另外,特征的顺序也调整了一下,使它更方便分析。
数据可视化分析
Region 分析:
[code]# 对二手房区域分组对比二手房数量和每平米价格df_house_count = df.groupby('Region')['Price'].count().sort_values(ascending=False).to_frame().reset_index()df_house_mean = df.groupby('Region')['PerPrice'].mean().sort_values(ascending=False).to_frame().reset_index()# 画三个图,长,高figsize = (20, 15)f, [ax1, ax2, ax3] = plt.subplots(3, 1, figsize = (20, 20))# (每平米单价对比图)sns.barplot(x = 'Region', y = 'PerPrice', palette = "Blues_d", data = df_house_mean, ax = ax1)ax1.set_title('北京各大区二手房每平米单价对比',fontsize=15)ax1.set_xlabel('区域')ax1.set_ylabel('每平米单价')# 各区域二手房数量(使用箱线图)sns.barplot(x = 'Region', y = 'Price', palette = "Greens_d", data = df_house_count, ax = ax2)ax2.set_title('北京各大区二手房数量对比', fontsize=15)ax2.set_xlabel('区域')ax2.set_ylabel('数量')# 各大区二手房房屋总价sns.boxplot(x = 'Region', y = 'Price', data = df, ax = ax3)ax3.set_title('北京各大区二手房房屋总价', fontsize=15)ax3.set_xlabel('区域')ax3.set_ylabel('房屋总价')plt.show()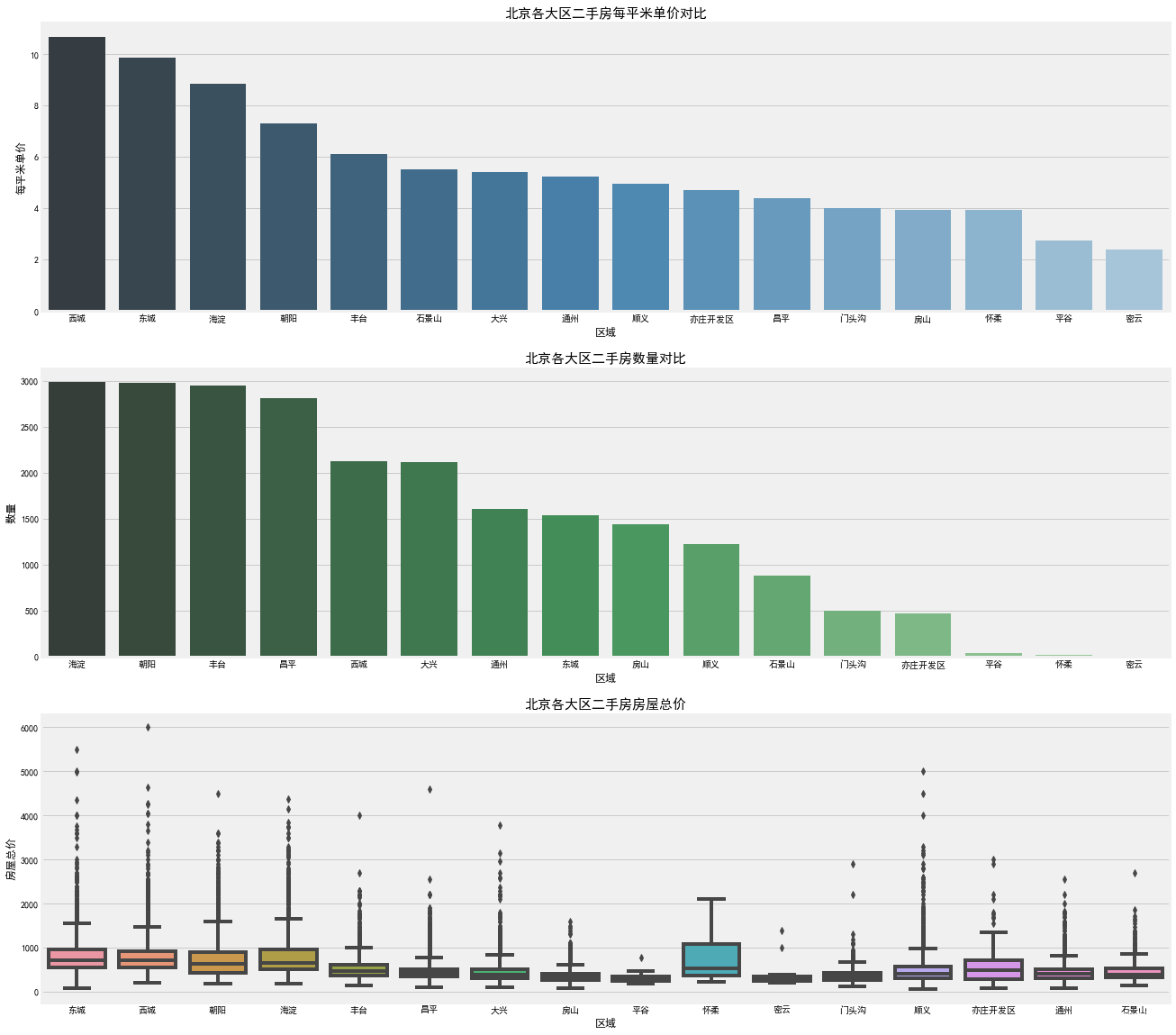
- 二手房均价:西城区的房价最贵均价大约11万/平,因为西城在二环以里,且是热门学区房的聚集地。其次是东城大约10万/平,然后是海淀大约8.5万/平,其它均低于8万/平。
- 二手房房数量:从数量统计上来看,目前二手房市场上比较火热的区域。海淀区和朝阳区二手房数量最多,差不多都接近3000套,毕竟大区,需求量也大。然后是丰台区,近几年正在改造建设,有赶超之势。
- 二手房总价:通过箱型图看到,各大区域房屋总价中位数都都在1000万以下,且房屋总价离散值较高,西城最高达到了6000万,说明房屋价格特征不是理想的正太分布。
Size特征分析
[code]# 画两幅图f, [ax1,ax2] = plt.subplots(1, 2, figsize=(15, 5))# 建房时间的分布 kdeplot(核密度估计图)# 核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。# 通过核密度估计图可以比较直观的看出数据样本本身的分布特征。sns.distplot(df['Size'], bins=20, ax=ax1, color='r')sns.kdeplot(df['Size'], shade=False, ax=ax1)# 建房时间和出售价格的关系sns.regplot(x='Size', y='Price', data=df, ax=ax2)plt.show()
得到如下的图:
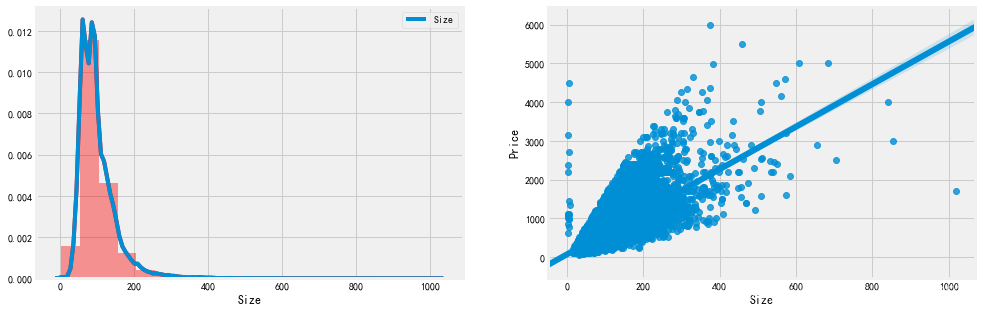
- 左图用 distplot 和 kdeplot 绘制柱状图体现了 Size 特征的分布,从图中可以看出,超过100平的房子挺多的,还有一部分超过200平的,这明显不符合常规。
- 右图绘制了Size 与 Price 的关系: regplot 绘制了 Size 和 Price 之间的散点图,可以看出 Size 特征基本与Price呈现线性关系,符合基本理论,面积越大,价格越高。但出现了两组明显的异常点:
- 面积不到10平米,但是价格超出10000万;
- 一个点面积超过了1000平米,价格很低,需要查看是什么情况。
[code]# 找出异常值 ,此时都是别墅,不在分析范围内,所以移除df.loc[df['Size']< 10]
得到如下结果:
[code]# 这条数据 1019平,无厅,可能是商品房,所以移除df.loc[df['Size'] > 1000]
得到的结果如下:
去除异常值后我们重新画图:
[code]# 去除异常值df = df[(df['Layout'] != '叠拼别墅') & (df['Size'] < 1000)]# 重新画图 图中无明显异常值f, [ax1,ax2] = plt.subplots(1, 2, figsize=(15, 5))# 建房时间的分布情况sns.distplot(df['Size'], bins=20, ax=ax1, color='r')sns.kdeplot(df['Size'], shade=True, ax=ax1)# 建房时间和出售价格的关系sns.regplot(x='Size', y='Price', data=df, ax=ax2)plt.show()
得到的结果是:
Layout特征分析
[code]f, ax1 = plt.subplots(figsize = (20, 20))sns.countplot(y = 'Layout', data = df, ax = ax1)ax1.set_title('房屋户型',fontsize=20)ax1.set_xlabel('数量')ax1.set_ylabel('户型')plt.show()得到的结果是:
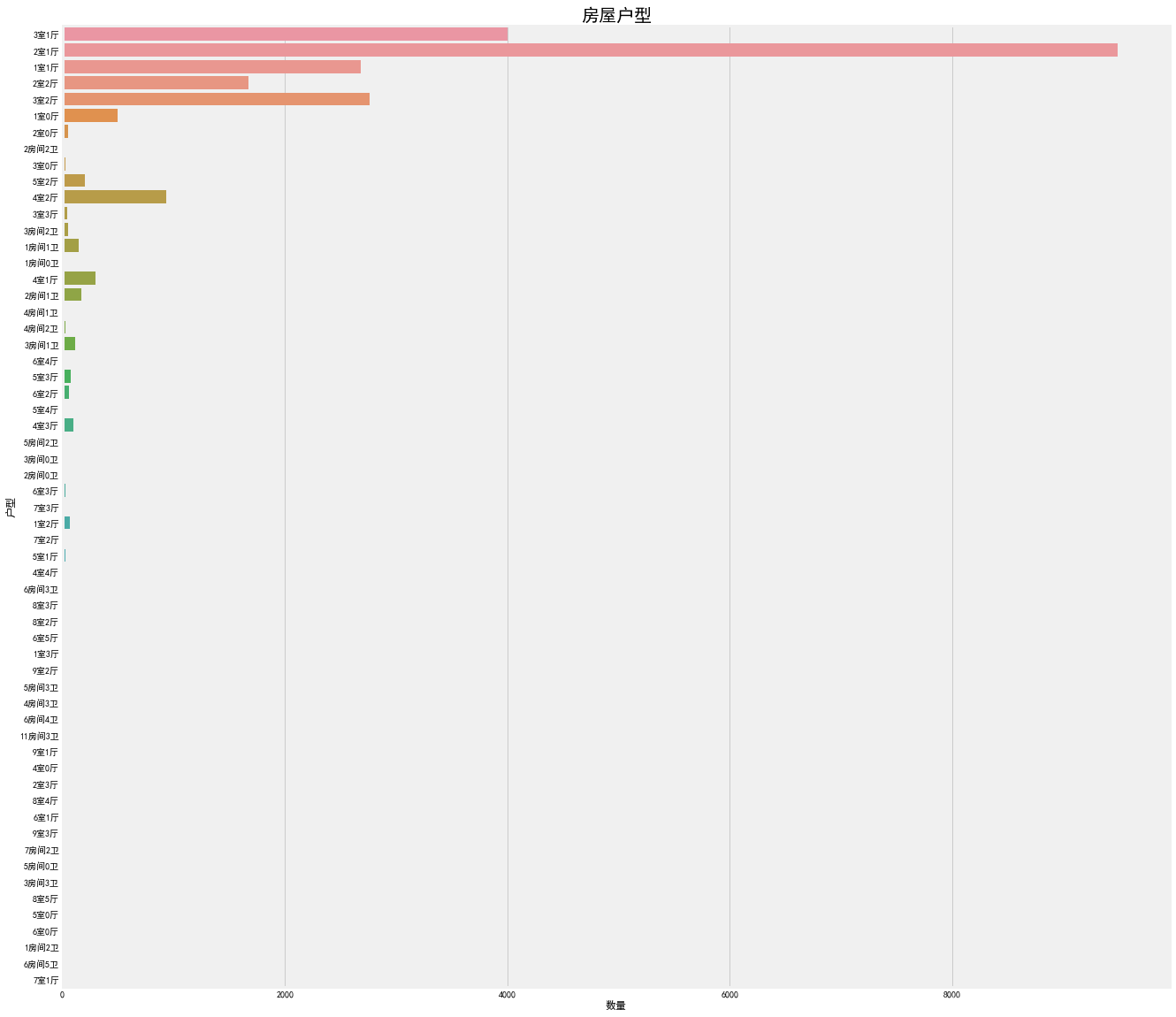
- 此特征比较混乱,各种叫法都有,没有统一的形式,应该做相应的处理
Renovation (装修)特征分析
[code]df['Renovation'].value_counts()# 去掉错误数据“南北”,去除 Renovation 中的异常值,df['Renovation'] = df.loc[(df['Renovation'] != '南北'), 'Renovation']# 画出分类直方图f, [ax1, ax2, ax3] = plt.subplots(3, 1, figsize =(10, 15))sns.countplot(df['Renovation'], ax = ax1)sns.barplot(x = 'Renovation', y = 'Price', data = df, palette = "Set3", ax = ax2)sns.boxplot(x = 'Renovation', y = 'Price', data = df, ax = ax3)plt.show()

- 精装修的房屋数量是最多的,毛坯房数量最少;对价格来说,精装修房屋价格较高,但毛配方的价格最高。
Elevator(电梯) 特征分析
[code]# 查询是否有缺失值,misn = len(df.loc[(df['Elevator'].isnull()), 'Elevator'])print('缺失值的数量是:', misn)df['Elevator'].value_counts()- 如果有缺失值,常用的方法有:平均值/中位数填补法,直接移除,或者根据其他特征建模预测等。也可根据业务进行填补。
[code]# 如果有错误值,需要移除,df['Elevator'] = df.loc[(df['Elevator'] == '有电梯')|(df['Elevator'] == '无电梯'), 'Elevator']# 填补 Elevator 缺失值df.loc[(df['Floor'] > 6)&(df['Elevator'].isnull()), 'Elevator'] = '有电梯'df.loc[(df['Floor'] <= 6)&(df['Elevator'].isnull()), 'Elevator'] = '无电梯'f, [ax1, ax2] = plt.subplots(1, 2, figsize = (20, 10))sns.countplot(df['Elevator'], ax = ax1)ax1.set_title('有无电梯数量对比', fontsize = 15)ax1.set_xlabel('是否与电梯')ax1.set_ylabel('数量')sns.barplot(x = 'Elevator', y = 'Price', data = df, ax = ax2)ax2.set_title('有无电梯房价对比', fontsize = 15)ax2.set_xlabel('是否有电梯')ax3.set_ylabel('总价')plt.show()- 观察可知,二手房有电梯的房屋数量居多,说明楼层较高,这样,土地的利用率也比较高,适合北京庞大人口的需要;
- 第二幅图,有电梯的房屋价格比无电梯的较高,因为包含了电梯的装修费和维护费;
Year(建房日期) 特征分析
[code]# 在数据集的不同子集上绘制同一图的多个实例 格子图grid = sns.FacetGrid(df, row = 'Elevator', col = 'Renovation', palette = 'seismic', size = 4)grid.map(plt.scatter, 'Year', 'Price')grid.add_legend()
得到的图如下:
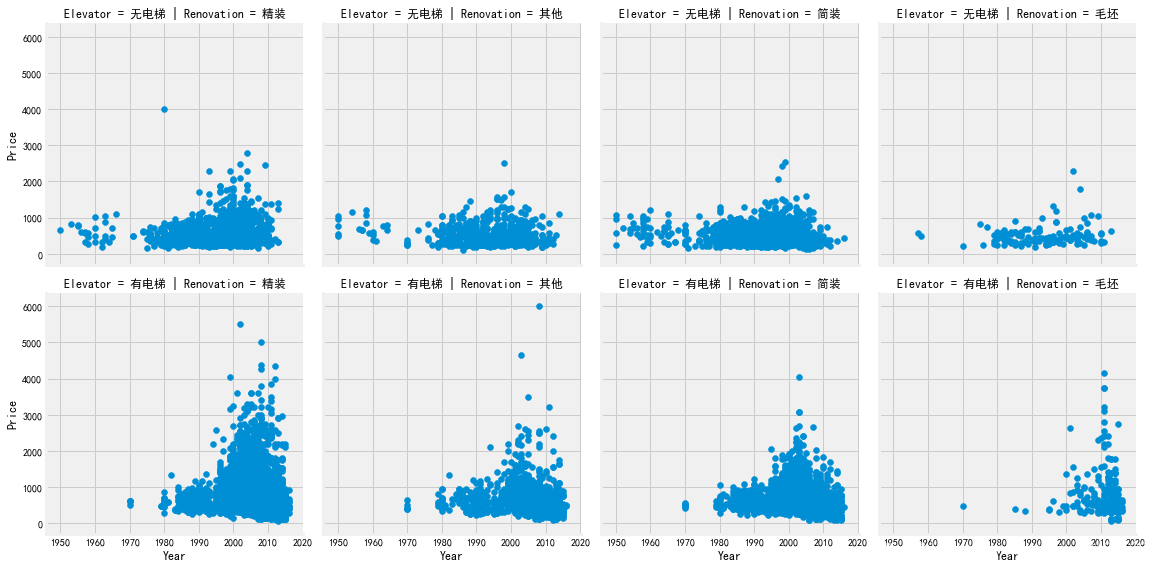
- 把Renovation和Elevator进行分类,使用 FaceGrid (网格面)分析 Year 特征,观察结果如下:整体来说,房价随着时间在增长。
- 90年代末以后的二手房,房价明显上涨;
- 1980年之前几乎不存在有电梯的房子;
- 1980年之前,无电梯的房子大多都是简装。
Floor (楼层)特征分析
[code]f, ax1 = plt.subplots(figsize=(20, 5))sns.countplot(x='Floor', data=df, ax= ax1)ax1.set_title('房屋户型', fontsize =15)ax1.set_xlabel('楼层')ax1.set_ylabel('数量')plt.show()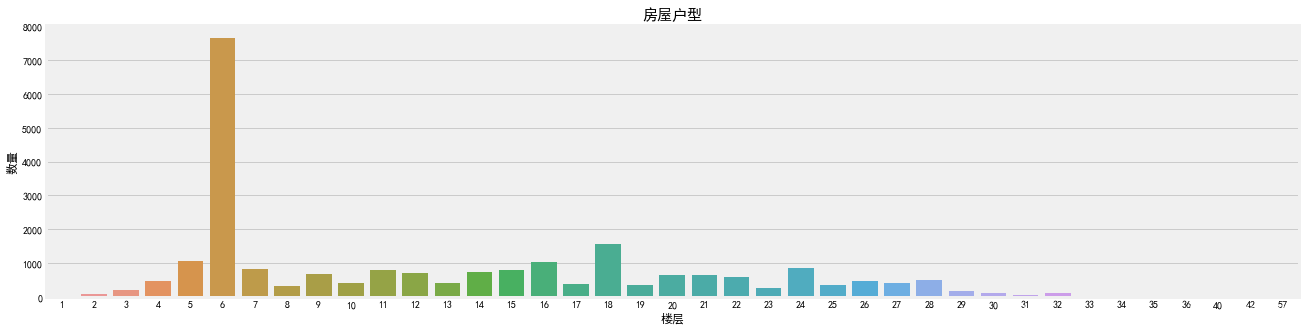
- 二手房中,楼层为6的房屋最多,达到了7600套。

相关文章推荐
- 数据分析实战——二手房信息分布分析
- python链家房源信息爬虫+数据分析
- Python爬虫三:抓取链家已成交二手房信息(58W数据)
- Python数据爬虫,爬链家的二手房信息
- Python数据分析与实战挖掘
- python 数据分析与挖掘实战
- python数据分析与挖掘实战-第六章拓展偷漏税用户识别
- python爬虫爬取链家二手房信息
- 大数据实战课程第一季Python基础和网络爬虫数据分析
- Python 数据分析微专业课程--项目实战10 国产烂片深度揭秘
- python数据分析与挖掘实战 第六章 拓展思考
- 【Python实战】Pandas:让你像写SQL一样做数据分析(二)
- 数据分析入门_PART1python基础语法_实战项目02基于Python的算法函数创建
- 使用python抓取分析链家网二手房数据
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
- python数据分析与挖掘实战第六章拓展思考题
- Python数据分析与挖掘实战第四章笔记之数据预处理
- python爬取拉勾网招聘信息并利用pandas做简单数据分析
- python数据分析和挖掘实战
- 用Python 爬取淘宝商品数据挖掘分析实战