知识蒸馏概念补充
知识蒸馏
Distilling the Knowledge in a Neural Network
这篇文章是2015年Hiton大神完成的一项黑科技技术,其第一次涉及了知识蒸馏(暗知识提取)的概念。可以从迁移学习和模型压缩的角度去理解这件事。
重点在于提出soft target来辅助hard target一起训练,而soft target来自于大模型的预测输出,为什么要用soft target?因为hard target包含的信息量(信息熵)很低,soft target包含的信息量比较大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target 不会像hard target那样只有马的index为1,其余为0,而可能是0.98和0.02)这样做的好处是,这个图像可能更像驴,而不是像汽车或者狗之类的,这样的soft概率存在于概率中,以及label之间的高低相似性都存在于soft target中,但是如果soft target是像这样的信息(0.98,0.01,0.01),就意义不大了,所以需要在softmax中增加温度参数T(这个设置在最终训练完之后的推理中是不需要的)
神经网络模型在预测最终的分类结果时,往往是通过softmax函数产生概率分布的,这里的T定义为温度参数,是一个超参数,qi是第i类的概率值大小
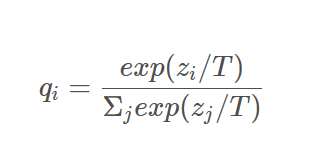
Loss 值为:
 其中soft loss 指的是对student model 中softmax(T=20)的输出与teacher model 的softmax(T=20)的输出求loss1
其中soft loss 指的是对student model 中softmax(T=20)的输出与teacher model 的softmax(T=20)的输出求loss1
hard loss 指的是对softmax(T=1)的输出与原始label求loss2
算法示意图:
 如图所示,教师网络的预测输出除以温度参数T之后,再做softmax变换,可以获得软化的概率分布(软目标),数值介于0-1之间,取值分布较为缓和,T数值越大,分布越缓和,而T越小,越容易放大错误分类的概率,引入不必要的噪声,针对较困难的分类或检测任务,T通常取1,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用one-hot矢量表示。total loss设计为软目标与硬目标所对应的交叉熵的加权平均,
如图所示,教师网络的预测输出除以温度参数T之后,再做softmax变换,可以获得软化的概率分布(软目标),数值介于0-1之间,取值分布较为缓和,T数值越大,分布越缓和,而T越小,越容易放大错误分类的概率,引入不必要的噪声,针对较困难的分类或检测任务,T通常取1,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用one-hot矢量表示。total loss设计为软目标与硬目标所对应的交叉熵的加权平均,
硬目标:0或1,软目标:(0,1)取值,对比于硬目标,软目标更soft
具体过程
1.首先用较大的T 来训练模型,这时候复杂的神经网络能产生更均匀分布的软目标。
2.之后小规模的神经网络用相同的T值来学习由大规模神经网络产生的软目标,接近这个软目标从而学习到数据的结构分布特征。
3.最后在实际应用中,将T值恢复到1,让类别概率偏向正确概率。
我们可以把数据结构信息和数据看成一种混合物,分布信息通过概率分布被蒸馏分离出来。首先,T值很大,相当于用很高的温度将关键的分布信息从原有的数据中分离出来,之后在同样的温度下用新模型融合蒸馏出来的数据分布,最后回复温度,让两者充分融合。这也是Hiton将这个迁移学习的过程称为知识蒸馏的原因之一。

- UIKit基础:5.UIView的概念普及以及Xcode的知识补充
- J2EE 字符 字节 编码知识概念
- 黑马程序员--Java学习日记之基础知识(思维导图&基础概念)
- Zabbix补充04 Zabbix核心概念回顾
- 数据库 知识 补充
- c语言学习之基础知识点介绍(二):格式化控制符和变量的补充
- 移动WEB基础知识(上)(基本概念,视口,移动浏览器)
- linux方面补充知识(1)
- linux学习(零) 硬件知识补充
- 【C#小知识】C#中一些易混淆概念总结(八)---------解析接口 分类: C# 2014-02-18 00:09 2336人阅读 评论(4) 收藏
- [企业信息化大家学系列]ERP基础知识问答之ERP概念
- 数据库知识基本概念
- sql 基础知识补充
- AutoLayout的起源、概念和基本知识
- 从概念到底层技术,一文看懂区块链架构设计(附知识图谱)
- 《深入理解Linux系统》书摘及补充知识
- Java学习笔记-《Java程序员面试宝典》-第四章基础知识-4.1基本概念(4.1.8-4.1.9)
- js基础知识点补充(5)
- Elasticsearch 基础概念知识
- Swift基础知识补充(二)