Python基础语法学习笔记梳理一:数据类型
一、数据类型:
在Python中,常见的数据类型可以分为:整数(int)、浮点数(float)、字符串(str)、列表(list)、字典(dictionary)五类。
查询数据类型所用到的函数为:type()函数。
1、整数(int)
在数学意义中理解的整数即为Python中用到的数据类型:整数。例:1,2,-1,-3等。
要将字符串类型的整数转换为整数类型的整数,用到的函数为int()函数。
例:
代码如下:
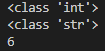
a='2' b=int(a) print(type(a)) print(type(b))
代码运行结果如下图:
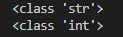
2、浮点数(float)
在数学意义中理解的小数即为Python中用到的数据类型:浮点数。例:1.2,2.5,-1.3,-3.0等。
要将字符串类型的整数转换为整数类型的整数,用到的函数为float()函数。
例:
代码如下:
a='1.5' b=2.0 c=float(a) print(b*c) print(type(b*c))
代码运行结果如下图:
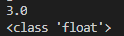
注:字符串类型的整数、浮点数均无法进行数学计算,需要将其转换成相应的数据类型再进行数学运算。整数和浮点数之间进行数学计算可以不用转换为相同类型。
例:
代码如下:
a = '1.5' b = 2 c = float(a) print(type(b)) print(b*c) print(type(b*c))
代码运行结果图如下:
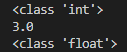
3、字符串(str)
在Python中,由两个单引号引用的量,视为字符串类型数据。例:‘3’,‘a’,‘我们’。
字符串类型数据无法进行数学运算,但可以进行逻辑运算(布尔运算)。
4、列表(list)
列表是由多个元素按一定顺序排列组成。
语法:列表名=[元素1,元素2,…]
例:list1 = [‘a’,‘3’,‘我们’]
说明:
(1)元素顺序固定,若两个列表元素的内容相同,但排列顺序不同,仍认定为两个不同的列表;
(2)元素的提取通过偏移量(索引)进行。被提取的可以是单个元素,也可以是列表中的某一片段。
(3)元素的增加和删除需要用到额外的函数和语句。增添元素:append()函数。删除元素:del 语句。
列表元素的提取通过偏移量(索引)进行,提取的语法为:列表名[偏移量(索引)]。
对偏移量的说明:(左右空,取到头;左要取,右不取)
(1)偏移量从零开始计数;
(2)提取多个元素时,偏移量起止数据中间需要用冒号“:”进行连接。冒号前后的偏移量均可省略,省略代表取到尽头的一个元素。若起止偏移量均未省略,则终止位偏移量不被提取。
(3)当偏移量为负值时,默认将列表首尾相接排序后,从零位向左为-1位依次索引元素。
例:
代码如下:
(a)定义与提取元素:
list1=[1,2,4,0,-1] list2=['?','我们','A','3'] print(list1[0]) print(list2[2]) print(list2)
代码运行结果图如下:
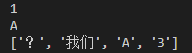
(b)多个列表元素的提取:
代码如下:
list1=[1,2,4,0,-1] list2=['?','我们','A','3'] a=list1[2:] print(a) b=list1[:2] print(b) c=list1[1:4] print(c)
代码运行结果图如下:

(c)列表元素的数据类型及运用:
代码如下:
list1=[1,2,4,0,-1] list2=['?','我们','A','3'] print(type(list1[1])) print(type(list2[3])) num1=list1[1]+list1[2] print(num1)
代码运行结果图如下:
列表元素的增加:append()函数
语法:列表名.append(元素)
说明:
(1)新增的元素可以是整数、浮点数、字符串等,也可以是列表或字典(即列表嵌套);
(2)append()函数括号中的参数只能是一个,即满足数量为1,如列表[2,3,5]视为一个参数,字符串’我们,一直在前行’视为一个参数;
(3)所增加的元素均在列表的末尾,即最后一位。
例:
代码如下:
list1=[1,2,4,0,-1]
list2=['?','我们','A','3']
list1.append(list2[1:])
print(list1)
list2.append('Python')
print(list2)
list1.append(3)
print(list1)
代码运行结果图如下:

列表元素的删除:
del语句:可以根据索引而非值,从列表中删除一个元素。也可以用于从列表中删除片段或者整个列表。
语法:del 列表名[偏移量]
说明:在删除列表中多个元素时,偏移量的书写规范与提取多个元素的书写规范相同,即用冒号连接起止偏移量,规则同样为“左右空,取到头,左要取,右不取”。
例:
代码如下:
list1=[1,2,4,0,-1] list2=['?','我们','A','3'] list3=list1+list2 print(list3) del list1[2:] print(list1) del list2[1] print(list2) del list3
注:此时在上述代码的下一行输入print(list3)后运行,会有如图报错,即整个列表已被删除:

代码运行结果图如下:

列表的合并方法:1、“+”;2、extend()函数:list.extend(list2)
例:
代码如下:
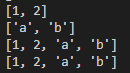
list1=[1,2] list2=['a','b'] list3=list1[:] list3.extend(list2) list4=list1+list2 print(list1) print(list2) print(list3) print(list4)
代码运行结果图如下:
注:代码中list3=list1[:]是为了保证list1不被改变。如果换为list3=list1,则list1的内容也会随之改变。这是列表的属性决定的,详细原因参见下图:

5、字典(dictionary)
字典由键值对组成,可以简单理解为带有标签的列表,标签是键,可用来进行索引,列表中的元素则是每一个键下对应的值,值依靠键索引进行提取。
语法:字典名={键1:值,键2:值,键3:值……}
索引语法:字典名[键名]
例:dic1={‘Susan’:‘470’,‘Leo’:‘539’,‘Marry’:‘591’}
说明:
(1)字典的元素由键值对组成,键与值为一一对应关系;
(2)字典中的键具有唯一性,不可出现重复,但每一个键所对应的值不具备唯一性;
(3)字典通过键进行索引,与键值对排列顺序无关,即只要两字典中的键值对相同,则认定两字典相同。
(4)特殊情况:在for…in…循环中,若遍历对象为字典,则变量提取的是***键名***而非值。
例:
代码如下:
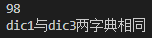
dic1={'张明':'98','李双':'80','王亮':'76','陈阔':'84'}
dic2={'刘坤':'87','吴磊':'87','郑琦':'96','王亮':'76'}
dic3={'王亮':'76','陈阔':'84','张明':'98','李双':'80'}
print(dic1['张明'])
if dic1==dic2:
#条件判断,如果两个字典相同,则会执行下一行打印语句
print('dic1与dic2两字典相同')
if dic1==dic3:
#条件判断,如果两个字典相同,则会执行下一行打印语句
print('dic1与dic3两字典相同')
代码运行结果图如下:
字典元素的增加:赋值语句
格式:字典名[键名] = 值
字典元素的删除:del语句
格式:del 字典名[键名]
例:
代码如下:
dic1={'张明':'98','李双':'80','王亮':'76','陈阔':'84'}
dic2={'刘坤':'87','吴磊':'87','郑琦':'96','王亮':'76'}
dic1['赵强']='78'
print(dic1)
del dic2['王亮']
print(dic2)
代码运行结果图如下:

列表与字典的异同:
相同点:修改元素可通过赋值语句完成,支持任意嵌套
不同点:列表中的元素有明确的位置,同样的元素,位置不同则列表不同;字典只要键值对相同即可,不考虑键值对排列顺序。
针对嵌套列表/字典的元素提取方法:“剥洋葱”法。
原则:辨析种类,层层递进。
说明:列表与字典可以进行嵌套,对于带有嵌套的列表或字典,在提取元素时需要根据每一层嵌套情况进行分层索引。
嵌套可以分为三类:列表嵌套列表,字典嵌套字典,字典与列表嵌套。
列表嵌套列表,从最外层开始进行索引即可。格式:列表名[最外层偏移量][其次层偏移量]……(有几层嵌套就有几个偏移量)
字典嵌套字典,从最外层开始索引键名即可。格式:字典名[最外层键][其次层键]……(有几层嵌套就有几个键)
字典与列表嵌套,从最外层开始,辨析每一层嵌套的类型是字典还是列表,使用对应的提取方式进行索引。
例:
代码如下:
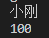
students = {
'第一组':['小明','小红','小刚','小美'],
'第二组':['小强','小兰','小伟','小芳']
}
scores = [
{'小明':95,'小红':90,'小刚':100,'小美':85},
{'小强':99,'小兰':89,'小伟':93,'小芳':88}
]
print(students['第一组'][2])
print(scores[0]['小刚'])
代码运行结果图如下:
详解:students是字典内嵌套列表,共计2层嵌套,应有2个索引量。最外层为字典类型,其次是列表类型。故在提取时,第一个索引量为键名,第二个索引量为代表位置的整数值——列表偏移量。
scores是列表内嵌套字典,共计2层嵌套,应有2个索引量。最外层为列表类型,其次是字典类型。故在提取时,第一个索引量为列表偏移量,第二个索引量为字典键名。

- 2-2.Python基础学习笔记day02-标识符、数据类型及运算符
- Python学习笔记【week01day3上】基本语法、标识符、数据类型及相互转换、math()、random()
- Python学习笔记(一):基础语法、变量类型、运算符(快速入门篇)
- Python学习笔记(一)--Python基础知识:变量、数据类型、模块与字符串
- [python学习笔记] 数据类型与语法
- python 入门学习笔记之基本语法与基本数据类型
- Go学习笔记----1,基础语法与数据类型
- Python编程:从入门到实践 学习笔记 基础知识(一) 变量与简单数据类型
- 王亟亟的Python学习之路(三)-基础语法以及基本数据类型
- 【学习笔记】Python基础-数据类型与变量
- JavaScript学习笔记(1):基础语法&数据类型与变量
- 【零基础入门学习Python笔记005】闲聊之Python的数据类型
- 王亟亟的Python学习之路(三)-基础语法以及基本数据类型
- 小甲鱼:Python学习笔记001_变量_分支_数据类型_运算符等基础
- 学习笔记:Python基础 —— 数据类型和变量
- 学习笔记☞ python 基础(python3)【一】(python相关介绍,核心数据类型(数字),赋值语句,算数运算符优先级)
- 2-1.Python基础学习笔记day02-标识符、数据类型及运算符
- python学习3:基础语法——变量&数据类型
- Python学习笔记一(简介及基础数据类型)
- Python3学习笔记【基础1--数据类型,运算符】