Kafka+SparkStreaming整合详解
今天也要努力学习
SparkStreaming+Kafka
1.SpringStreaming+Kafka 接受数据和发送数据
(1)SparkStreaming 接受kafka方式
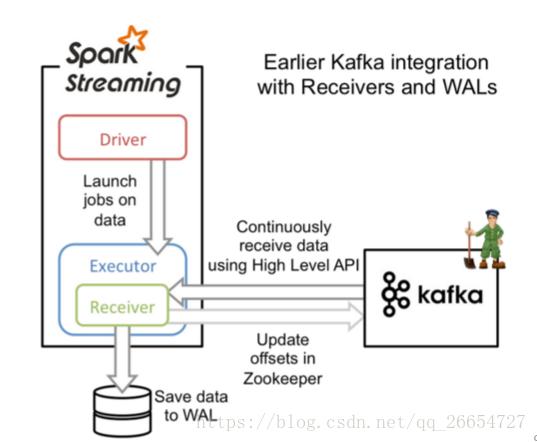
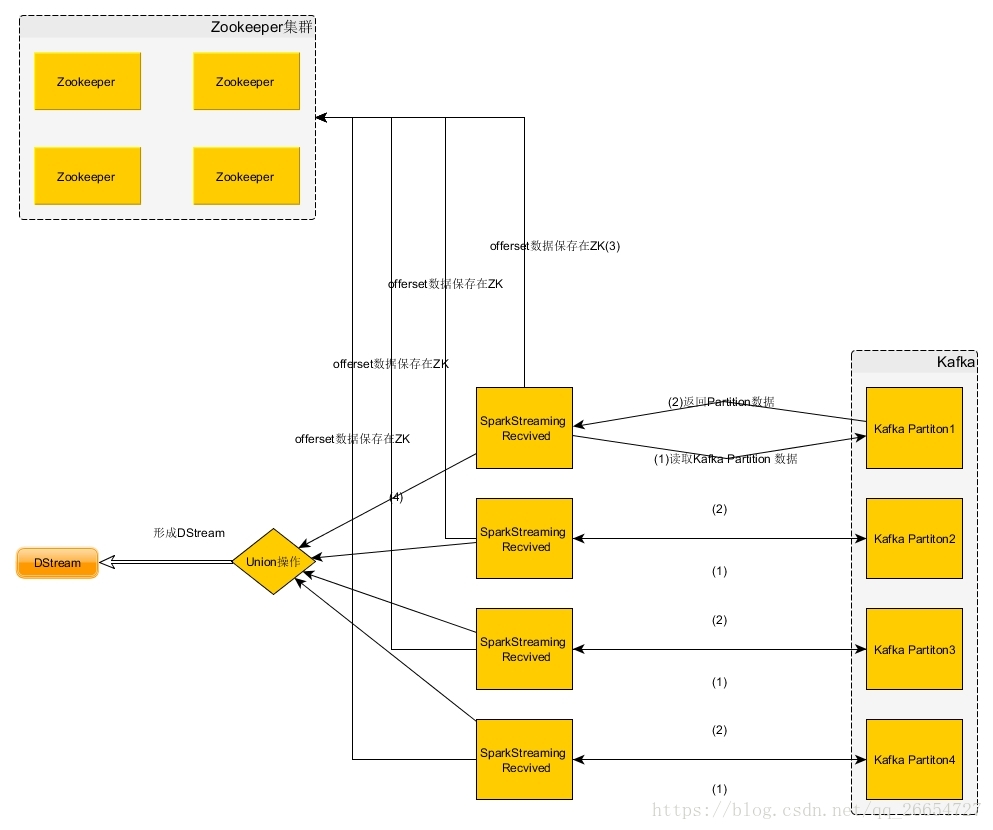
- 基于Received的方式
- 基于DirectKafkaStreaming
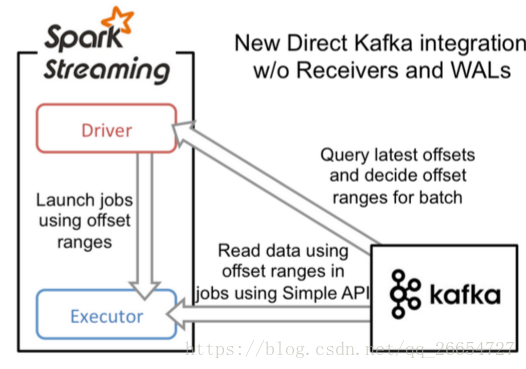
DirectKafkaStreaming 相比较 ReceiverKafkaStreaming
- 简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
- 高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
- 精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
(2)Spark 发送数据至Kafka中
一般处理方式 : 在RDD.forpartition进行操作
[code]input.foreachRDD(rdd =>
// 不能在这里创建KafkaProducer
rdd.foreachPartition(partition =>
partition.foreach{
case x:String=>{
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
println(x)
val producer = new KafkaProducer[String,String](props)
val message=new ProducerRecord[String, String]("output",null,x)
producer.send(message)
}
}
)
)
此方式的缺点在于每次foreach操作都需要重新创建一次kafkaProduce 主要花费时间都在 创建连接的时候.
基于此我们以以下方式进行操作
- 首先,我们需要将KafkaProducer利用lazy val的方式进行包装如下:
[code]
import java.util.concurrent.Future
import org.apache.kafka.clients.producer.{ KafkaProducer, ProducerRecord, RecordMetadata }
class KafkaSink[K, V](createProducer: () => KafkaProducer[K, V]) extends Serializable {
/* This is the key idea that allows us to work around running into
NotSerializableExceptions. */
lazy val producer = createProducer()
def send(topic: String, key: K, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, key, value))
def send(topic: String, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, value))
}
object KafkaSink {
import scala.collection.JavaConversions._
def apply[K, V](config: Map[String, Object]): KafkaSink[K, V] = {
val createProducerFunc = () => {
val producer = new KafkaProducer[K, V](config)
sys.addShutdownHook {
// Ensure that, on executor JVM shutdown, the Kafka producer sends
// any buffered messages to Kafka before shutting down.
producer.close()
}
producer
}
new KafkaSink(createProducerFunc)
}
def apply[K, V](config: java.util.Properties): KafkaSink[K, V] = apply(config.toMap)
}
- 之后我们利用广播变量的形式,将KafkaProducer广播到每一个executor,如下:
[code]// 广播KafkaSink
val kafkaProducer: Broadcast[KafkaSink[String, String]] = {
val kafkaProducerConfig = {
val p = new Properties()
p.setProperty("bootstrap.servers", Conf.brokers)
p.setProperty("key.serializer", classOf[StringSerializer].getName)
p.setProperty("value.serializer", classOf[StringSerializer].getName)
p
}
log.warn("kafka producer init done!")
ssc.sparkContext.broadcast(KafkaSink[String, String](kafkaProducerConfig))
}
- 这样我们就能在每个executor中愉快的将数据输入到kafka当中:
[code]//输出到kafka
segmentedStream.foreachRDD(rdd => {
if (!rdd.isEmpty) {
rdd.foreach(record => {
kafkaProducer.value.send(Conf.outTopics, record._1.toString, record._2)
// do something else
})
}
})
2.Spark streaming+Kafka调优
2.1 批处理时间设置
参数设置:
2.2 合理的Kafka拉取量
参数设置: spark.streaming.kafka.maxRatePerPartition
2.3 缓存反复使用的Dstream(RDD)
DStream.cache()
2.4 设置合理的GC
长期使用Java的小伙伴都知道,JVM中的垃圾回收机制,可以让我们不过多的关注与内存的分配回收,更加专注于业务逻辑,JVM都会为我们搞定。对JVM有些了解的小伙伴应该知道,在Java虚拟机中,将内存分为了初生代(eden generation)、年轻代(young generation)、老年代(old generation)以及永久代(permanent generation),其中每次GC都是需要耗费一定时间的,尤其是老年代的GC回收,需要对内存碎片进行整理,通常采用标记-清楚的做法。同样的在Spark程序中,JVM GC的频率和时间也是影响整个Spark效率的关键因素。在通常的使用中建议:
[code]--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC"
- 1
2.5 设置合理的CPU资源数
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。
2.6设置合理的parallelism
partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个partition参数来显式控制具体的分片数量。
在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前文阐述过Spark中的partition和Kafka中的Partition是一一对应的,我们一般默认设置为Kafka中Partition的数量。
2.7使用高性能的算子
- 使用reduceByKey/aggregateByKey替代groupByKey
- 使用mapPartitions替代普通map
- 使用foreachPartitions替代foreach
- 使用filter之后进行coalesce操作
- 使用repartitionAndSortWithinPartitions替代repartition与sort类操作

- Spark Streaming 1.3对Kafka整合的提升详解
- SparkStreaming与Kafka的整合(基础)
- <转>整合Kafka到Spark Streaming——代码示例和挑战
- 【转】Spark Streaming和Kafka整合开发指南
- Kafka+Spark Streaming+Redis实时计算整合实践
- sparkstreaming整合kafka实时流处理的pom文件模板
- spark streaming + kafka整合二(Direct Approach (No Receiver))
- kafka0.8版本和sparkstreaming整合的两种不同方式
- kafka flume sparkStreaming整合
- 整合Kafka到Spark Streaming
- Michael G. Noll:整合Kafka到Spark Streaming——代码示例和挑战
- Spark-Streaming与Kafka整合
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
- Kafka+Spark Streaming+Redis实时计算整合实践
- SparkStreaming整合Kafka--之Receiver和直连方式介绍
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark streaming整合Kafka之Direct方式
- 整合Kafka到Spark Streaming——代码示例和挑战