大数据Spark:从入门到实战(理论和实战相结合,附上视频教程&项目源码)
本文是由菜鸟窝出品的12天大数据特训营课程摘录出来的,关于大数据spark的入门到实战视频可以戳此查看第三章:https://www.cniao5.com/course/10244
一、Spark简介
1、大数据简介:
Spark是大数据相关的最活跃的开源项目,是继 MapReduce框架之后的下一代大数据处理框架。
Spark是一个开源的内存计算框架,类似MapReduce, 用于使用商业服务器集群来处理和分析数据。 Spark API允许开发者创建分布式应用程序,使用整个集 群的资源,而不需要知道所有底层细节。
2、Spark发展历史
Spark是在Matei Zaharia的博士论文《An Architecture for Fast and General Data Processing on Large Cluster》(大型集群上 的快速和通过数据处理架构)的基础上发展而来。
2009年,Spark起源于加州大学伯克利分校的 实验室(AMPLab)。
2010年,Spark成为开源项目。 2013年,Spark被捐赠给Apache软件基金会。 同年,Databricks公司成立。
2014年,Spark称为Apache的顶级项目
3、Spark版本历史

二、Hadoop与MapReduce
2.1、MapReduce计算框架的缺点
1.可编程性较差
2.缺乏一个通用计算引擎
3.计算速度慢
2.2. Spark计算框架的优点
1、良好的编程性:
Spark程序比相应的MapReduce应用程序要简单得多。
Spark提供了丰富的API。
与MapReduce相比,Spark job只需要原有代码量的十分之一。
MapReduce版本的wordCount程序

Spark版本的wordCount程序

2、一个通用计算引擎
Spark是一个真正的通用 处理框架,可用于:
①批处理
②交互式分析
③流处理
④机器学习
⑤图计算

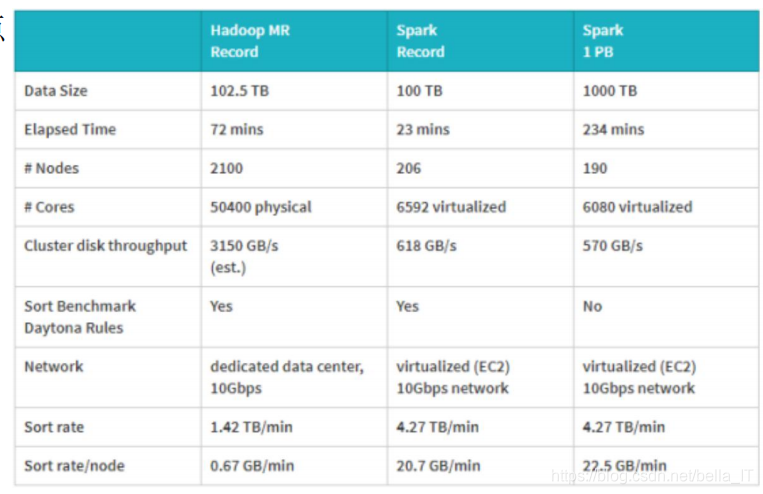
3、计算速度快
Spark在MapReduce的性能 上提供了100X的改进。 2014年的排序比赛:
Hadoop架构设计思想—数据不同代码动,即计算处理 应该移动到数据所在的位置。 Spark继承了这一设计思想,在此之上提供了内存计算、 执行计划等优化。
与MapReduce不同,Spark每个job不局限于两个 stage(阶段)–可以有任意数量的stage(阶段)。 Spark不是将复杂算法分成多个job, 而是在job中包 含多个stages,使Spark可以进行更多优化,例如, 最小化shuffle数据和磁盘IO。
Spark可以独立运行,但在生产环境中,Spark会读取HDFS上的数据,使用YARN作 为资源管理器。在Hadoop集群中,Spark和MapReduce可以同时使用,以提供分布 式数据处理,如图所示

三、Spark工具栈
1.Spark Core Spark Core是Spark的主要执行引擎,Spark的所 有功能都基于这个引擎。它提供了Spark的主要功 能,比如任务调度,内存管理、故障恢复和处理存 储。
2.SparkSQL 处理结构化数据,通过SQL和Hive查询语言(HQL) 查询数据。
3.SparkStreaming 流处理,用于处理流数据。
4.MLlib 提供了机器学习算法,如分类、聚类和协同过滤。
5.GraphX 图计算,可以操作像社交网络中包含的关系图。

四、安装Spark
1.CentOS 单机安装
1、安装JDK:Java8
2、下载Spark2.3,并解压
3、设置JAVA_HOME、SPARK_HOME 环境变量
4、启动Spark
5、启动Spark shell
2.CentOS3节点安装:(Node1 主节点 Node2 从节点 node3 从节点)

3.Spark集群管理器
standalone集群管理器 Spark可以在它自己的专用集群上运行,称为standalone Spark集群。
standalone集群管理器的体系结构
standalone的集群管理器使用worker和master进程来执行计算。 worker进程管理每个集群节点的CPU/RAM等计算资源。 master进程负责分配资源。
在standalone集群管理器上部署的Spark应用程序使用以下实体:
driver程序:这是由数据处理逻辑组 成的主Spark应用程序。
Executor:这是一个运行在worker节点上的 JVM进程,处理driver提交的job计算任务。
Task:task是数据处理job的子组件。
注意: Spark应用程序和驱动程序被用作彼此的同义词。
下图显示了standalone Spark集群的体系结构。Driver程序使用SparkContext对象,作为 Spark 工具库的入口点,连接到一个Spark集群。
SparkContext对象在worker节点上启动Executor。并向他们发送应用程序代码。job被分 解为task,并由Executor执行。
在Spark standalone 集群中,Spark Master和Worker进程管理Spark应用程序。

4.Spark与Scala
可以用三种不同的语言编写Spark应用程序: Scala, Python 和 Java。
相对于其他两种语言,Scala有较好的性能,而且比Java 应用程序代码更简单。
对于Spark开发工程师,建议花些时间学习Scala语言:
尽管您可以在不了解Scala的情况下使用Spark,但如果您 知道Scala,就可以阅读Spark源代码,因为Spark是用 Scala编写的。
Spark RDD中的方法都是模仿Scala集合API的。RDD中的方 法如:map、filter、reduce,Scala中都有类似的函数。
Scala提供的另一个巨大优势是,Spark shell用于调试和开发 工作非常有用。Spark是一种解释型语言,隐藏有spark shell; 由于Java是一种编译语言,所以没有shell。
许多Spark的特性首先在Scala中编写。
5.函数式编程
Spark依赖于函数式编程,它使用函数作为基本编程输入。函数没有状态或 副作用,只包含输入和输出。
(1)将函数作为参数传递
Spark使用函数作为参数,而大多数 RDD操作都接受这些函数参数。它将 函数应用于RDD中的每条数据记录。 举个例子: scala> def toUpper(s):return s.upper() scala> mydata = sc.textFile(“test.txt”) scala> mydata.map(toUpper).take
(2) 函数式编程
你也可以使用匿名函数,这主要是 为了短期的一次性功能。
举个例子: 匿名函数 Scala> mydata.map(line => line.toUpperCase()).take(2) 您可以使用下划线()代表匿名参数,上述代码等价于: Scala> mydata.map(.toUpperCase()).take(2)
6.Spark功能入口—SparkContext
(1) SparkContext对象是使用Spark功能的入口。Spark Driver程序中最重 要的一步就是创建SparkContext对象。使用SparkContext对象,Spark 应用程序就可以通过资源管理器访问Spark集群。
(2)要创建SparkContext对象,首先要创建SparkConf对象。SparkConf对 象中包含需要传递给SparkContext对象的配置参数。
(3)创建完成SparkContext对象之后,我们就可以访问Spark相关的功能方 法来创建RDD、共享变量,进行数据处理了。
(4)在一个JVM中,只能存在一个激活状态的SparkContext对象。可以使用 SparkContext对象的stop方法来停止SparkContext。
7.RDD简介
RDD是Spark的基本数据结构,是一个数据记录的不可变的分布式集合。这 个集合被分成多个逻辑分区partition,在集群中的不同节点上进行计算。
RDD全称为:Resilient Distributed Dataset(弹性分布式数据集):
Resilient弹性 体现在使用RDD DAG实现容错,可以重新计算丢失的分区。
Distributed分布式 体现在使用RDD DAG实现容错,可以重新计算丢失的分区。
Dataset数据集 代表所处理的数据记录,如从本地文件系统加载的数据。

- vue.js入门和项目实战视频教程+素材+源码(16套全)
- 大数据,云计算,架构,数据分析师,Hadoop,Spark,Storm,Kafka,人工智能,机器学习,深度学习,项目实战视频教程
- 视频干货Spark企业级项目实战,源码深度剖析,实时流处理,机器学习,数据分析
- 云计算大数据(Hadoop)开发工程师项目实战视频教程(九部分)
- 安卓程序员必看安卓开发项目视频教程 32G安卓开发项目实战+源码
- 云星数据---Scala实战系列(精品版)】:Scala入门教程011-Scala实战源码-变量声明
- storm视频教程下载|storm入门到项目实战视频教程
- Redis 视频教程 大数据 高性能 集群 NoSQL 设计 实战 入门 命令
- 云星数据---Scala实战系列(精品版)】:Scala入门教程012-Scala实战源码-Scala操作符
- 云星数据---Scala实战系列(精品版)】:Scala入门教程028-Scala实战源码-Scala 的特质 (接口)04
- 云星数据---Scala实战系列(精品版)】:Scala入门教程043-Scala实战源码-Scala Set操作
- 云星数据---Scala实战系列(精品版)】:Scala入门教程059-Scala实战源码-Scala package 包
- Spark入门到精通视频学习资料--第八章:项目实战(2讲)
- 【资源分享】基于Spark的机器学习-智能客户系统项目实战视频教程
- 云星数据---Scala实战系列(精品版)】:Scala入门教程019-Scala实战源码-Scala 伴生类
- 云星数据---Scala实战系列(精品版)】:Scala入门教程020-Scala实战源码-Scala 继承关系
- 云星数据---Scala实战系列(精品版)】:Scala入门教程035-Scala实战源码-Scala apply方法03 创建对象demo
- [视频教程] 聚合数据 iOS 项目开发实战:条码查询器
- 云星数据---Scala实战系列(精品版)】:Scala入门教程049-Scala实战源码-Scala implicit 操作
- 云星数据---Scala实战系列(精品版)】:Scala入门教程047-Scala实战源码-Scala method操作