K-最近邻分类算法(KNN)及python实现
一、引入
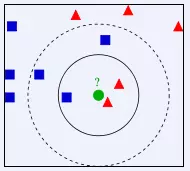
问题:确定绿色圆是属于红色三角形、还是蓝色正方形?
KNN的思想:
从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形
即如果一个样本在特征空间中的k个最相邻的样本中,大多数属于某一个类别,则该样本也属于这个类别。我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。
二、KNN算法
1.介绍
KNN即K-Nearest Neighbor,是一种memory-based learning,也叫instance-based learning,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。
KNN也是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归。若K=1,新数据被简单分配给其近邻的类。
2.步骤
1)计算测试数据与各个训练数据之间的距离;
(计算距离的方式前文讲k-means时说过,不清楚的可以去查看以下➡传送门)
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
K值是由自己来确定的
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
说明:对于步骤5的预测分类有以下两种方法
- 多数表决法:多数表决法类似于投票的过程,也就是在 K 个邻居中选择类别最多的种类作为测试样本的类别。
- 加权表决法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大,通过权重计算结果最大值的类为测试样本的类别。
特点
- 非参数统计方法:不需要引入参数
- K的选择:
K = 1时,将待分类样本划入与其最接近的样本的类。
K = |X|时,仅根据训练样本进行频率统计,将待分类样本划入最多的类。
K需要合理选择,太小容易受干扰,太大增加计算复杂性。 - 算法的复杂度:维度灾难,当维数增加时,所需的训练样本数急剧增加,一般采用降维处理。
三、算法优缺点
优点
- 简单、有效。
- 重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
- 计算时间和空间线性于训练集的规模(在一些场合不算太大)。
- 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
- 该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
缺点
- KNN算法是懒散学习方法(lazy learning),而一些积极学习的算法要快很多。
- 需要存储全部的训练样本
- 输出的可解释性不强,例如决策树的可解释性较强。
- 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算最近的邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
- 计算量较大。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
四、KNN与K-means的区别
废话不多说,咱直接上图:
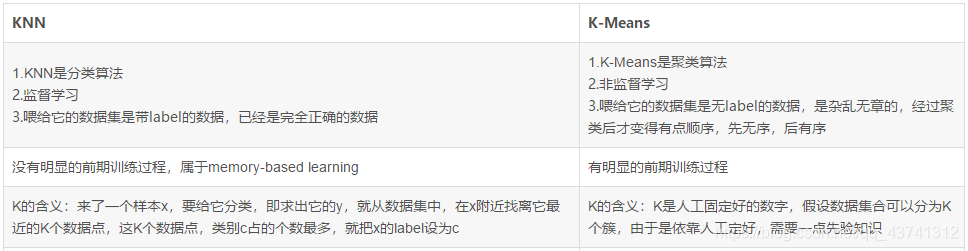
相似点:
虽然两者有很大且别,但两者也有共同之处。都包含了一个过程:给定一个点,在数据集找离它最近的点,即都用到了NN(Nearest Neighbor)算法。
五、python实例实现
下面引入一个实例,通过python代码具体看下KNN算法的流程。
from numpy import *
import operator
dataSet = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
def classify0(inX,dataSet,labels,k):
#求出样本集的行数,也就是labels标签的数目
dataSetSize = dataSet.shape[0]
#构造输入值和样本集的差值矩阵
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#计算欧式距离
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#求距离从小到大排序的序号
sortedDistIndicies = distances.argsort()
#对距离最小的k个点统计对应的样本标签
classCount = {}
for i in range(k):
#取第i+1邻近的样本对应的类别标签
voteIlabel = labels[sortedDistIndicies[i]]
#以标签为key,标签出现的次数为value将统计到的标签及出现次数写进字典
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#对字典按value从大到小排序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),rever
7ff7
se=True)
#返回排序后字典中最大value对应的key
return sortedClassCount[0][0]
if __name__ == '__main__':
print(classify0([1.1,0],dataSet,labels,3))

- 机器学习一:邻近算法【K最近邻(KNN,k-NearestNeighbor)分类算法】python代码实现KNN
- k最近邻算法(KNN)的简介和python实现
- python 实现 knn分类算法 (Iris 数据集)
- KNN最邻近规则分类算法实践实现【Python实现】
- KNN (K最近邻接算法)python 语言下的简单实现
- 机器学习与数据挖掘-K最近邻(KNN)算法的实现(java和python版)
- python实现KNN分类算法(含代码注解)
- 分类算法 -- KNN算法 (理论与python实现)
- python实战:sklearn的KNN算法实现手写数据的分类
- 基于qt和opencv3实现机器学习之:利用最近邻算法(knn)实现手写数字分类
- python运用sklearn实现KNN分类算法
- KNN分类算法原理与Python+sklearn实现根据身高和体重对体型分类
- K最近邻结点算法(k-Nearest Neighbor algorithm)KNN——python简单实现
- 数据挖掘10大算法(6)-K最近邻(KNN)算法的实现(java和python版)
- K-Nearest Neighbor(KNN) 最邻近分类算法及Python实现方式
- KNN分类算法及python代码实现
- KNN 算法的python实现 迭代训练方式,将最近的测试样例作为训练样例扩大训练集
- kNN分类算法python实现
- 基于python实现KNN分类算法
- Python KNN最近邻分类算法