深度残差网络(ResNet)
引言
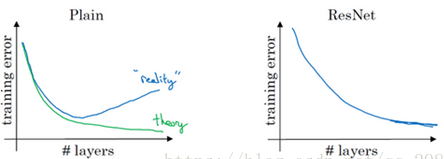
对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多。当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了准确率,而且很容易出现梯度消失和梯度爆炸。
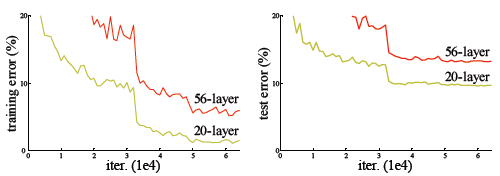
这种现象并不是由于过拟合导致的,过拟合是在训练集中把模型训练的太好,但是在新的数据中表现却不尽人意的情况。从上图可以看出,我们的训练准误差和测试误差在层数增加后皆变大了,这说明当网络层数变深后,深度网络变得难以训练。
如果大家还没理解的话,那我讲细一点,网络太深,模型就会变得不敏感,不同的图片类别产生了近似的对网络的刺激效果,这时候网络均方误差的减小导致最后分类的效果往往不会太好,所以解决思路就是引入这些相似刺激的“差异性因子”。
深度残差网络(ResNet)的设计就是为了克服这种由于网络深度的加深而产生的学习率变低、准确率无法有效提升的问题。
残差块
在一个网络中(假设有五层),如果前面四层已经达到一个最优的函数,那第五层就没有必要了,理想中我们可以把第五层设计为一个y=x层的恒等映射,可以让网络随着深度的增加而不退化。但是我们的非线性网络无法毕竟恒等映射网络。
但是不退化不是我们的目的,我们希望有更好性能的网络。ResNets学习的是残差函数$F(x)=H(x)-x$,这里如果$F(x)=0$,那么就是上面提到的恒等映射。
残差块(Residual block)(也可以理解为跳跃连接)的结构如下图所示:
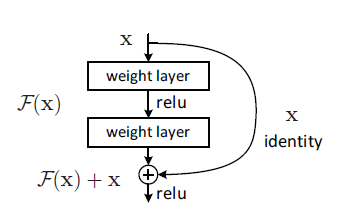
它有两层,我们用$\sigma$表示激活函数,如下表达式,
$$F(x)=\sigma(W_1x)$$
然后通过一个shortcut和第2个relu获得输出y
$$y=\sigma(W_2\sigma(W_1x)+x_{identity})$$
这个残差块往往需要两层以上,单单一层的残差块并不能起到提升作用。
残差网络的确解决了退化的问题,在训练集和校验集上,都证明了的更深的网络错误率越小,如下图

实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1, 如下图。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。
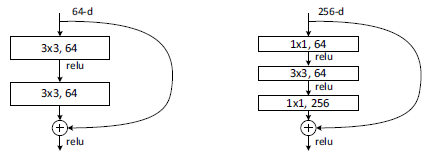
上面是两种不同的跳跃结构,主要就是使用了不同的卷积核。左边参数要比右边的多一倍。所以当网络很深时,用右边的比较好。
残差神经网络
下图是一个普通网络

下图是一个残差网络(ResNet)
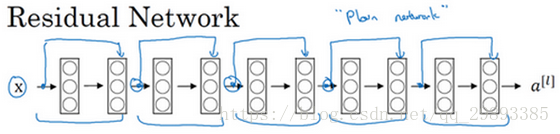
由此可见,把普通网络变成ResNet的方法就是加上跳跃连接,没两层增加一个捷径,构成一个残差块。
对于跳跃结构,当输入与输出的维度一样时,不需要做其他处理,两者相加就可,但当两者维度不同时,输入要进行变换以后去匹配输出的维度,主要经过两种方式,1)用zero-padding去增加维度,2)用1x1卷积来增加维度。
普通的神经网络,随着网络深度的加深,训练错误会越来越多。但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。
参考文献:
何恺明的论文:Deep Residual Learning for Image Recognition
CSDN博主的--深度学习笔记(七)--ResNet(残差网络)
CSDN博主三百斤菠萝--ResNet论文笔记

- 深度学习之神经网络结构——残差网络ResNet
- 深度残差网络(ResNet)浅析
- 深度残差网络(ResNet)浅析
- 深度学习: ResNet (残差) 网络
- 高速路神经网络(Highway Networks)与深度残差网络(ResNet)的原理和区别
- Deep Learning-TensorFlow (14) CNN卷积神经网络_深度残差网络 ResNet
- 深度学习——残差神经网络ResNet在分别在Keras和tensorflow框架下的应用案例
- 深度残差网络 ResNet
- 深度学习---残差resnet网络原理详解
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
- 深度学习论文随记(四)ResNet 残差网络-2015年Deep Residual Learning for Image Recognition
- [深度学习]Deep Residual Learning for Image Recognition(ResNet,残差网络)阅读笔记
- 深度残差网络:ResNet
- ResNet深度残差网络 论文翻译
- 大话深度残差网络(DRN)ResNet网络原理
- 深度残差网络RESNET
- 深度三维残差神经网络:视频理解新突破
- resnet__残差神经网络搭建
- 系统学习深度学习(二十)--ResNet,DenseNet,以及残差家族
- 深度残差网络(Deep Residual Network )