【爬虫】scrapy下载股票列表(一)——对接selenium中间件
2019-06-29 16:30
375 查看
先送上传送门,scrapy中文网,画风清奇的使用说明网站:http://www.scrapyd.cn/doc/139.html
安装完python就可以一键安装scrapy了
pip3 install scrapy
新建一个项目
scrapy startproject stock
看到如下输出:
You can start your first spider with: cd stock scrapy genspider example example.com
装了PYCHARM或者别的python开发工具的童鞋就可以在PYCHARM里面找到对应路径打开这个项目了(file->open…->打开文件夹)。scrapy已经自动创建了项目框架:

第一步在spiders文件夹下面创建一个py文件,
stock_spider.py
scrapy的规则
A:首先我们需要创建一个类,并继承scrapy的一个子类:scrapy.Spider 或者是其他蜘蛛类型,后面会说到,除了Spider还有很多牛X的蜘蛛类型;
B:然后定义一个蜘蛛名,name=“” 后面我们运行的话需要用到;
C:定义我们需要爬取的网址,没有网址蜘蛛肿么爬,所以这是必须滴;
D:继承scrapy的一个方法:start_requests(self),这个方法的作用就是通过上面定义的链接去爬取页面,简单理解就是下载页面。
我们从东方财富网下载股票列表
先简单的保存HTML下来看看
'''
这是主程序
'''
import scrapy
class StockSpider(scrapy.Spider):
name = 'stock_spider'
def start_requests(self):
# 东方财富网获取股票列表
urls = [
'http://quote.eastmoney.com/center/gridlist.html#hs_a_board',
]
headers = {
'Referer': 'http://quote.eastmoney.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
for url in urls:
yield scrapy.Request(url=url, headers=headers, callback=self.parse)
def parse(self,response):
filename = 'stock_file'
with open(filename,'wb') as f:
f.write(response.body)
self.log('save file %s' % filename)
在项目中就有了如下文件:
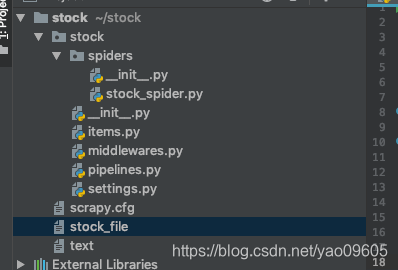
打开一看:
<div class="listview full"> <table id="table_wrapper-table" class="table_wrapper-table"><thead></thead><tbody></tbody></table>`
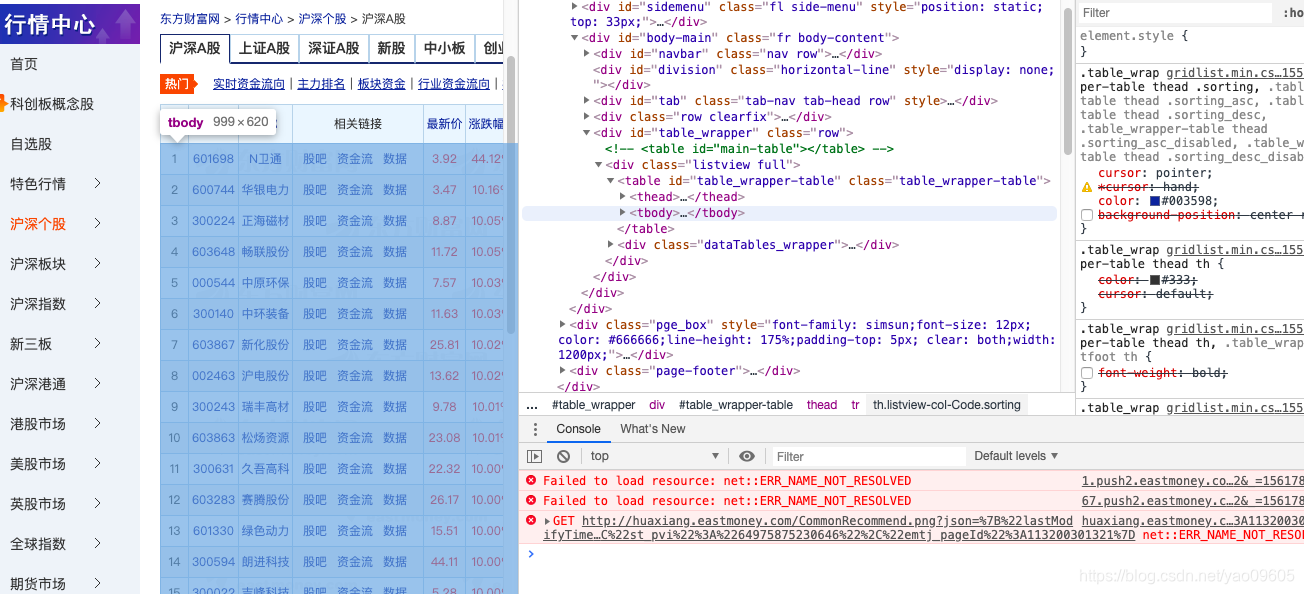
我们最需要的<tbody>
标签里什么都没有,丧心
这个时候需要使用
selenium作为中间件,当中遇到一点小问题,传送门:
打开项目中
middlewares.py
输入如下代码:
这里用到了chromedriver配置传送门:
from scrapy import signals
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
class StockMiddleware(object):
def process_request(self, request, spider):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
self.driver = webdriver.Chrome(chrome_options=chrome_options, executable_path='/Users/yaochenli/stock/stock/chromedriver')
self.driver.get(request.url)
time.sleep(3)
html = self.driver.page_source
self.driver.quit()
return scrapy.http.HtmlResponse(request.url, body=html.encode('utf-8'), encoding='utf-8', request=request)
再打开
settings.py
先将robotstxt_obey改成false

再打开DOWNLOADER_MIDDLEWARES 将中间的类名改成我们刚刚添加的类名

全部保存好
scrapy crawl stock_spider
再打开文件看

可以看到我们要的
<tbody>的内容已经有了
先到这里。

相关文章推荐
- 【爬虫】scrapy下载股票列表(二)—— 内容解析及中间件模拟翻页
- 【爬虫】scrapy下载股票列表(四)——对接mongodb保存数据
- 【爬虫】scrapy下载股票列表(三)—— 设置日志
- Scrapy爬虫 -- 编写下载中间件,实现随机User-Agent
- 【python爬虫】网易云歌单下载(scrapy+selenium)
- scrapy爬虫学习系列五:图片的抓取和下载
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
- python+selenium+scrapy搭建简单爬虫
- 网络爬虫之Scrapy实战四:爬取网页下载图片
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装爬虫框架Scrapy(离线方式和在线方式)(图文详解)
- 爬虫 scrapy 框架学习 2. Scrapy框架业务逻辑的理解 + 爬虫案例 下载指定网站所有图片
- 爬虫"用python抓取某音乐网站,然后将歌曲名、歌手、链接存入excel表格中" 列表、循环、函数都有用,有些可能需要先‘pip install’下载模块)
- Python 利用scrapy爬虫通过短短50行代码下载整站短视频
- scrapy_cookie禁用_延迟下载_自定义爬虫setting
- python3 简单爬虫实战|使用selenium来模拟浏览器抓取选股宝网站信息里面的股票
- scrapy selenium 爬虫
- [Python爬虫]Scrapy配合Selenium和PhantomJS爬取动态网页
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
- python爬虫实战-爬取视频网站下载视频至本地(selenium)