要租房又不想自己找怎么办?用Scrapy爬取租房信息
对于临近毕业的大学生(指自己)而言,怎样寻找便宜又实惠的房源无疑是人人都在关心的问题,今天就来看看怎样用爬虫技术快速抓取房源信息。
运行环境:
Python 3.6.3
Scrapy : 1.5.1
Twisted : 18.9.0
BeautifulSoup :4.6.3
fake_useragent :0.1.11
js2py :0.60
PyMySQL :0.9.3
难度:初级
网站总体难度较低,但联系方式的获取需要运用正则表达式/js引擎提取参数,携带参数和cookie后访问接口,因此对于爬虫初学者而言具有一定难度。
爬取到的数据:

(由于这个网站并不是把所有数据按顺序展示,而是每一页近乎随机的展示60条房源信息,且并不保证每一页数据不重复,因此一次运行无法爬取所有数据。本次运行选取的地区为广州,爬取的数据为2279条,时间为2019-05-01 23:53:13 ~ 2019-05-02 02:56:01。)
网站分析:
本次爬取的网站反爬手段相当单一,几乎所有数据都是静态加载,因此采取最初级的获取列表-获取单页-提取数据-翻页的流程即可。
在几个月前爬取这个网站时,房源联系人的联系方式都直接写在页面源码里,但几个月后再次爬取,发现联系方式变为了ajax动态加载,且ajax接口参数依赖于页面源码,导致速度被大大拖慢,目前没有找到可行的解决方法,希望有思路的朋友指点一二。
首先,创建scrapy项目:
[code]scrapy startproject zufang
在zufang/settings.py里,填写如下内容:
[code]HTTPERROR_ALLOWED_CODES = [404,400,502,503] DOWNLOAD_TIMEOUT = 5 DOWNLOAD_DELAY = 1.5
● HTTPERROR_ALLOWED_CODES :允许被中间件处理的Response。状态码未在HTTPERROR_ALLOWED_CODES中声明的Response将被Scrapy引擎直接抛弃。
● DOWNLOAD_TIMEOUT :最大超时时间。超过DOWNLOAD_TIMEOUT值的请求将会触发twisted.internet.TimeoutError异常(可被Middleware的process_exception方法捕获)。
● DOWNLOAD_DELAY :下载延迟。Scrapy保证请求间隔不小于DOWNLOAD_DELAY。
在item.py中写入如下内容:
[code]import scrapy class ZufangItem(scrapy.Item): house_url = scrapy.Field() #房屋链接 house_name = scrapy.Field() #房源名字 price = scrapy.Field() #房源租金 house_type = scrapy.Field() #房屋类型 house_area = scrapy.Field() #房屋面积 rental_method = scrapy.Field() #出租方式 community = scrapy.Field() #所在小区 gender = scrapy.Field() #性别要求 deposit = scrapy.Field() #押金方式 contact = scrapy.Field() #联系人 phone = scrapy.Field() #联系手机 time = scrapy.Field() #数据获取时间
如果想要了解一个租房信息,那么价格、面积、地址等信息显然是我们关注的部分,保存房屋链接可以让我们看中某个房源时方便的找到房源页面而不需要重新搜索,数据获取时间可以一定程度上体现数据的可用性——毕竟好的房源不会在网站上挂太久(笑)
在settings/spiders中创建文件houseSpider.py,并写入如下内容:
[code]import json,time from fake_useragent import UserAgent import bs4 import zufang.items import scrapy import js2py class houseSpider(scrapy.Spider): name = "mainSpider" ua = UserAgent() urls = ["https://gz.zu.anjuke.com/fangyuan/p1/",] #起始url地址
这里要注意的是,文件名houseSpider.py和类名houseSpider都不影响爬虫调用,scrapy引擎只会根据类的name属性来查找、调用爬虫。
静态页面的分析为避免拖延篇幅就不做展开,直接贴代码:
[code] def start_requests(self):
for url in self.urls :
yield scrapy.Request(url = url,
headers={"user-agent":self.ua.random},
callback=self.parse_house_list,
dont_filter=True)
def parse_house_list(self, response):
#解析网页。提取并请求其中所有的房源信息页。
soup = bs4.BeautifulSoup(response.body.decode("utf8"), "lxml")
info_list = soup.find_all(class_="zu-itemmod")
url_list = [url.a["href"] for url in info_list]
for url in url_list:
yield scrapy.Request(url = url,
headers={"user-agent":self.ua.random},
callback=self.parse_house,
dont_filter=True)
#请求下一页。
next_url = soup.find(class_="aNxt")
if next_url != None :
yield scrapy.Request(url=next_url["href"],
headers={"user-agent": self.ua.random},
callback=self.parse_house_list,
dont_filter=True)
def parse_house(self,response):
cookie = response.headers["Set-Cookie"].decode("utf8")
item = zufang.items.ZufangItem()
soup = bs4.BeautifulSoup(response.body.decode("utf8"),"lxml")
try :
#房屋链接
item["house_url"] = response.url
#房源名字
item["house_name"] = soup.find(class_="house-title").get_text()
#租金
item["price"] = soup.find(class_="price").em.get_text()
#房屋类型
item["house_type"] = soup.find_all(class_="house-info-item l-width")[0].find_all(name="span")[-1].get_text()
#房屋面积
item["house_area"] = soup.find(class_="info-tag no-line").em.get_text()
#出租方式
item["rental_method"] = soup.find(class_="full-line cf").find_all(name="span")[1].get_text()
#所在小区
item["community"] = soup.find_all(class_="house-info-item l-width")[2].a.get_text()
#性别要求
gender = soup.find_all(class_="house-info-item")[-1].find_all("span")[-1].get_text()
if "小区" in gender :
gender = "暂无"
item["gender"] = gender
#押金方式
item["deposit"] = soup.find(class_="full-line cf").find_all("span")[1].get_text()
#联系人
item["contact"] = soup.find(class_="broker-name").get_text()
详细讲一点:联系方式。
在房源页面点击查看电话后,在Network页面搜索对应的号码,能看到一个专门用于获取电话的请求:
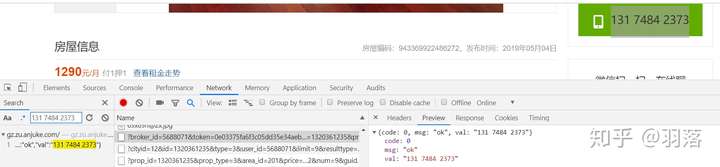
查看请求链接:
[code]https://gz.zu.anjuke.com/v3/ajax/getBrokerPhone/?broker_id=5688071&token=0e03375fa6f3c05dd35e34aeb2b52590&prop_id=1320361235&prop_city_id=12&house_type=1&captcha=
忽略为空的captcha,共有五个参数,分别是broker_id,token,prop_id,prop_city_id,house_type。
初学者看到这么多参数可能就晕了,但其实只要在源码里ctrl+f就可以看到:
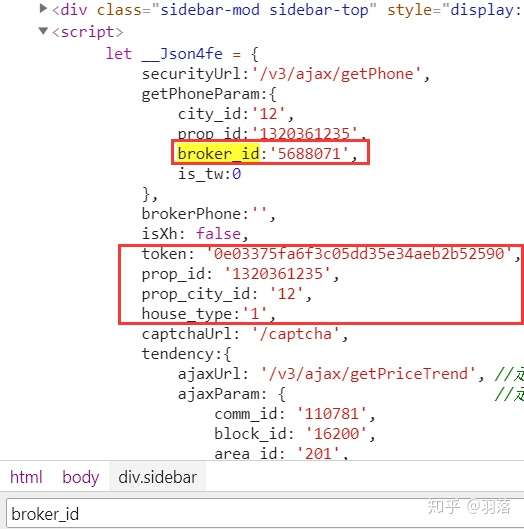
五个参数都在源码里写着,我们需要做得事情只是把它提取出来而已。
用正则提取显然会比较麻烦,这时候我们可以用到js2py了。使用方式非常简单,获取脚本文本,建立js2py.EvalJs对象,执行js文本后获取返回值,然后用模板替换出url,直接请求即可。
[code]phone_template = "https://gz.zu.anjuke.com/v3/ajax/getBrokerPhone/?broker_id={broker_id}&token={token}&prop_id={prop_id}&prop_city_id={prop_city_id}&house_type={house_type}"
js = soup.find_all(name="script")
context = js2py.EvalJs()
for i in js:
if "brokerPhone" in i.get_text():
context.execute(i.get_text())
data_dict = getattr(context, "__Json4fe")
broker_id = data_dict["getPhoneParam"]["broker_id"]
token = data_dict["token"]
prop_id = data_dict["prop_id"]
prop_city_id = data_dict["prop_city_id"]
house_type = data_dict["house_type"]
yield scrapy.Request(url = self.phone_template.format(
broker_id=broker_id,
token=token,
prop_id = prop_id,
prop_city_id = prop_city_id,
house_type = house_type,
),headers={"user-agent":self.ua.random,"cookie" : cookie},
meta = {"item":item,"url" :response.url,},
callback=self.parse_phone,dont_filter=True)
break
眼尖的读者应该看到了,headers里还额外提交了cookie参数,这个cookie是哪来的呢?
重新打开主页面的请求信息,可以看到Response Headers里set-cookie项:
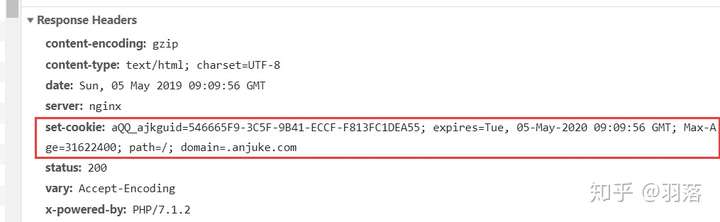
这里设置的cookie也是获取联系号码的必备参数,实际效果类似于自己动手,用Python实现Pixiv动图下载器(附模拟登录流程)中Pixiv使用的Referer头。
在发送请求前保存cookie即可:
[code]cookie = response.headers["Set-Cookie"].decode("utf8")
获取到联系号码后,将其保存,并同时保存当前时间,最后返回处理完成的item:
[code] def parse_phone(self,response):
item = response.meta["item"]
js = json.loads(response.text)
item["phone"] = "".join(js["val"].split())
item["time"] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
yield item
在项目目录下新建run.py文件,并输入以下内容:
[code]from scrapy import cmdline
if __name__ == "__main__" :
cmdline.execute("scrapy crawl mainSpider".split())
运行run.py即可直接启动Scrapy项目,而不用每次都切换到命令行界面了。
运行run.py,就可以在控制台中看到提取完成的数据了:
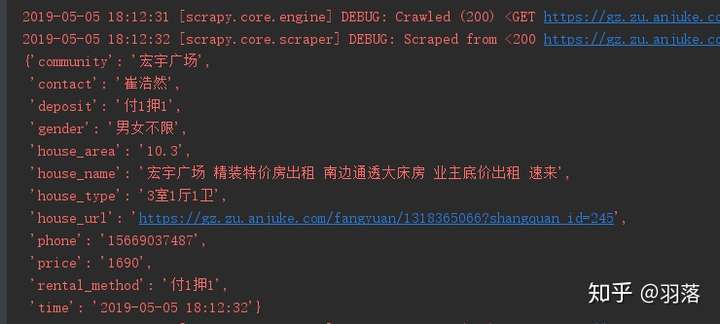
数据入库:
对于这种小规模的爬虫,数据入库部分非常简单,无需在意性能开销、网络传输开销等,直接在Pipelines中编写SaveDataPipeline即可。利用twisted.enterprise.adbapi实现异步插入:
[code]from twisted.enterprise import adbapi
import zufang.settings as settings
class SaveDataPipeline(object):
#SQL命令模板
insert_template = """
INSERT INTO house_table VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);
"""
def __init__(self):
self.dbpool = adbapi.ConnectionPool("pymysql",
host=settings.sqlsetting["HOST"],
port=settings.sqlsetting["PORT"],
db=settings.sqlsetting["DB"],
user=settings.sqlsetting["USER"],
password=settings.sqlsetting["PASSWORD"],
charset=settings.sqlsetting["CHARSET"],
cp_reconnect=True) #自动检测失效连接并重连。
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.insert_data,item)
query.addErrback(self.error_hander,item)
return item
def insert_data(self,cursor,item):
house_id = item["house_url"].split("/")[-1].split("?")[0]
cursor.execute(self.insert_template,[house_id,item["house_url"],item["house_name"],
item["price"],item["house_type"],item["house_area"],
item["rental_method"],item["community"],item["gender"],
item["deposit"],item["contact"],item["phone"],item["time"]])
def error_hander(self,failure,item):
#由于网站数据的展示并非有序且唯一,所以主键重复是可能的。捕获后抛出即可。
if "for key 'PRIMARY'" in str(failure) :
print("主键重复:",item["house_url"].split("/")[-1])
其中数据库配置在settings中读取:
[code]with open("DataBaseSettings.ini","r") as fp:
sqlsetting = json.loads(fp.read())["default"]
DataBaseSettings.ini使用json格式存储配置,格式如下:
[code]{
"default":{
"HOST":"your DB host",
"PORT":port,
"DB":"house_data",
"USER":"your DB username",
"PASSWORD":"your DB password",
"CHARSET":"utf8"
}
}
(个人认为将敏感配置单独编写是非常好的习惯,可以有效避免诸如“某网站管理员将数据库密码明文上传至GITHUB”一类的惨案发生。)
你可以在我的github中下载到本篇文章中的源码:OrsPced
警告:
本篇文章原定发表日期为5月2日,因延迟发表,作者对文章中爬虫规则的有效性不做保证(但你可以留言让我改)
本文首发于知乎:https://zhuanlan.zhihu.com/p/71137275
END

- 网络安全事件频发,怎么保护自己的生物识别信息?
- scrapy爬虫案例爬取赶集网租房信息并入库
- 论互联网时代自己的私人信息是怎么泄露的
- 教你们怎么查自己的手机信息
- 教你们怎么查自己的手机信息
- 使用scrapy框架爬取链家网站租房信息
- 借用此地,发个售/租房信息。自己的。
- scrapy 爬虫怎么写入日志和保存信息
- 怎么在eclipse中修改自己的git账号信息?解决办法
- 想在自己的android应用中获得当天的天气情况,这该怎么做呢?不用担心。中国国家气象局提供了获取所在城市天气预报信息接口。通过这个接口,我们就可以获取天气信息了。
- Win10系统怎么更改盘符来彰显自己的个性
- Scrapy pycharm 爬取豆瓣排名前250信息
- 任吾等再怎么想磨炼自己,身旁终缺一人相伴
- Android系统获取应用的Crash信息,保存在本地(可以自己实现上传到自己的服务器)
- 七夕快到了,中国人自己的情人节,恋爱中的情人们怎么过呢
- json 解析 多条信息时 只解析自己想要的信息
- [Oracle] 11G自己主动收集统计信息
- 怎么才能提高自己的应变能力?
- 自己的英文名字怎么写
- <h:outputText>标签 中怎么限制字数 多余的用省略号,并且鼠标放上时显示全部信息