论文笔记:Rethinking Knowledge Graph Propagation for Zero-Shot Learning (DGP)
 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
Rethinking Knowledge Graph Propagation for Zero-Shot Learning (DGP)
来源:挪威北极大学&清华&中山& MIT &中科院自动化所 & CMU, arxiv-2018,paper,code
摘要
部分总结
本文在 Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs [1] 的基础上进行了改进,包括:
- 更少的GCN层数,本文中使用了2层神经网络进行计算(即GPM,上文使用了6层)
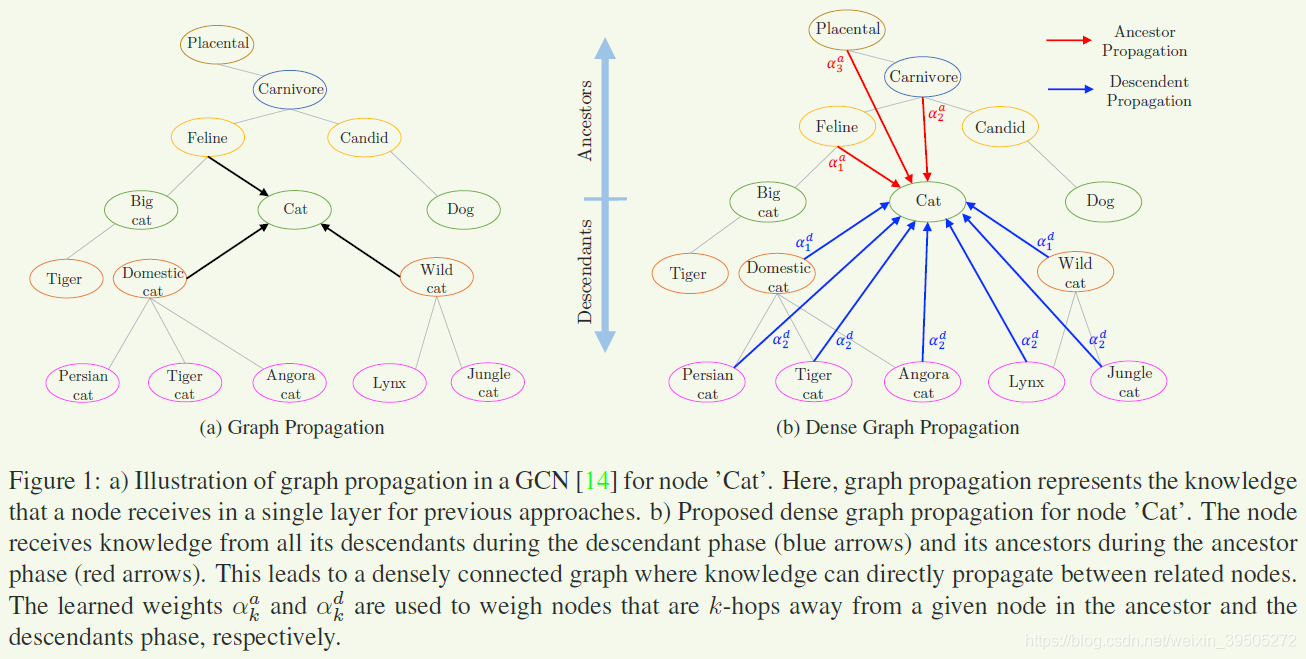
- 减少层数的同时,一些较远节点将不被考虑在内,为了解决这个问题,作者将一些节点的祖先节点/子孙节点直接与该节点相连,生成了更密集的图,即DGPM,这些直接相连的边按照距离的远近,加入attention机制进行了加权计算(即ADGPM)
- 提出了在CNN部分根据graph信息进行fine tune的计算方式,使得提取图片特征的卷积网络可以根据一些新出现的class进行更新
主要是通过在语义空间构建seen class和unseen class之间的关系,来实现知识迁移
论文摘要
- 在图中相关的概念通过共享统计优势,使得模型在数据缺乏的情况下拥有处理新的类别的泛化能力时,应用图结构的模型拥有高度的 sample efficient
- 作者认为多层的结构(同时使得传播发生在远距离节点)使得性能下降,因为进行 多余的拉普拉斯平滑
- DGP:使得远距离节点有机会直接连接,他们之间关系通过节点的祖先/后代进行权重衡量
Introduction
- zero-shot image classification:关注于使用seen和unseen节点之间的语义关系来利用先验知识,将图像正确的分到unseen的类别中
- 此前的工作通过 类别的语义描述 或者 语义关系 来使用先验知识,通常基于 未知的类可以发现和已知类的相似性 这个假设。
- 在 [1] 中,知识图谱和类别的语义描述之间产生了结合作用。作者认为其工作中应当减少网络层数削弱平滑效果。
GCN使得神经网络可以应用在非欧式空间中,表现出一种消息传递的作用。GCN 表现出一种拉普拉斯平滑的作用,特征表示会跟随深度的增加变得更加相似使得分类变得更加容易 (?,特征变得相似难道不会增加分类难度吗)。比如,一个连通图中,当网络层数 n→∞n\to\inftyn→∞,特征会收敛到相同的表示使得所有的信息丢失 (?,这难道不是和参数有关吗,还是说神经网络变得无法训练?)
- 作者通过实验论证了上面的观点,即 浅层网络总能比之前的工作要好。但 当网络变浅时,信息就无法在图中很好地传递了。因此作者希望通过将节点与部分远亲节点直连来使得浅层网络也能考虑到远亲节点的影响 (?,为什么使用非图结构就能很好地衡量权重而使用原始的并且统一的图结构却不能) 。这样的设计使得原始的图结构化信息有所丢失,为了更好地衡量远亲节点的影响,作者使用了 weighting scheme
- 这里作者使用的训练方法有些独特。为了更好地使得 CNN 能够适应新的分类器,使用了两步训练的方式 使用 DGP 来预测 CNN 最后一层的参数
- 使用 DGP 预测的结果作为 CNN 最后一层的参数并固定,finetune 其他的参数
- 所以这个 GCN 中有没有参数?
- 预测参数有怎样的好处?(这是从seen到unseen迁移的关键)
contribution
- DGP 模块,更有效地使用密集连接的结构传播信息
- 一个新的对于 DGP 模块的加权框架,权重基于节点之间的距离获得
Related Work
GCN
图卷积是一类图神经网络,基于局部化图算子。优势在于图结构使其可以共享类之间的统计优势,使其有高度的抽样效率。通过引入切比雪夫多项式,其运算效率有了很大的提高。
Zero-shot learning
此前的方法:
- 多重对齐
- 线性自编码器
- 低秩空间字典嵌入
- 利用基于知识图谱上的属性和关系的语义关系
本文借鉴的是其中 model-of-models的思想,即通过一个模型来预测另一个模型中使用的参数。
方法
使用 C< 3ff7 /mi>\mathcal{C}C 表示所有类的集合,Cte\mathcal{C}_{te}Cte 和 Ctr\mathcal{C}_{tr}Ctr 分别为测试集和训练集中的类别,要求 Cte∩Ctr=∅\mathcal{C}_{te}\cap\mathcal{C}_{tr}=\emptyCte∩Ctr=∅。使用 SSS 维的语义表征向量 z∈RSz\in\mathbb{R}^{S}z∈RS 表示所有的类别,以及 Dtr={(X⃗i,ci),i=1,...,N}\mathcal{D}_{tr}=\{(\vec{X}_{i},c_{i}),i=1,...,N\}Dtr={(Xi,ci),i=1,...,N} 表示训练集中的样本(图像及标签)。
GCN for Zero-shot Learning
使用类别标签的 word embedding以及知识图谱来对未知的类进行预测。
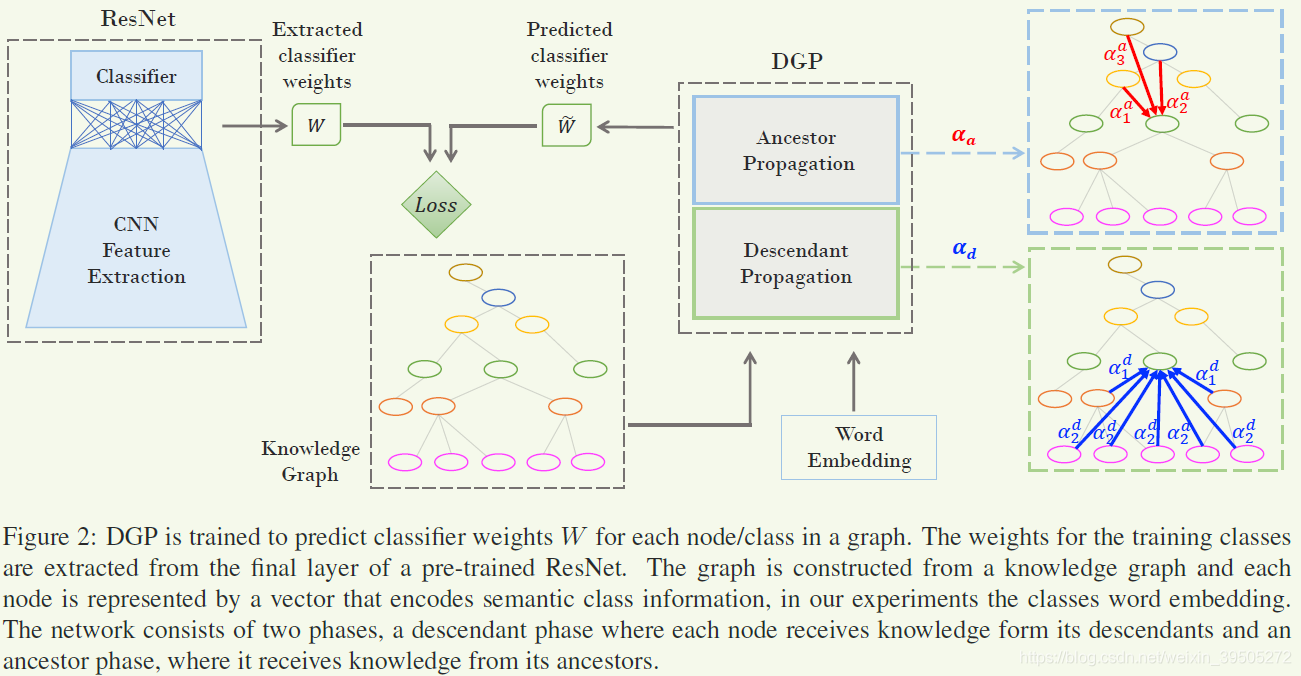
DGP中考虑了所有的 seen 和 unseen 特征,使用词嵌入向量的方式。对于 zero-shot 的任务,目标就是通过预测一组新的参数来扩展CNN,使得这组参数能够适应 unseen classes 的分类。训练过程中,DGP使用了一种半监督的方法来预测 CNN 最后一层的参数(对于所有 seen 和 unseen 的类),这样就使得我们能够利用知识图谱提供的类别的语义描述之间关系的信息来扩展原有的 CNN 分类器,使之能够适应 unseen 的类。
这样的描述符合逻辑,将 CNN 按照功能分离——特征提取+线性分类器。然后假设特征提取不带有类别特异性(实际上作者似乎排除了这个假设,通过fine-tune),通过影响分类器就能影响最终的分类结果。实际上作者应该是认为两部分都能影响最终的判断,但分类器更加直接,因此使用了 DGP 来预测并固定,前面的应用finetune调整。
具体描述:给定一个有 NNN 个节点的图,每个节点使用 SSS 维输入特征表示,X∈RN×SX\in\mathbb{R}^{N\times{S}}X∈RN×S 就表示特征矩阵。这里每一个节点表示一个不同的概念/类。类之间的链接使用对称的邻接矩阵表示 A∈RN×NA\in\mathbb{R}^{N\times{N}}A∈RN×N,其中包括自环。传播法则表示为:
(1)H(l+1)=σ(D−1AH(l)Θ(l))H^{(l+1)}=\sigma(D^{-1}AH^{(l)}\Theta^{(l)})\tag{1}H(l+1)=σ(D−1AH(l)Θ(l))(1)
其中 H(l)H^{(l)}H(l) 表示第 lll 层的激活结果,Θ∈RS×F\Theta\in\mathbb{R}^{S\times{F}}Θ∈RS×F 表示第 lll 层的可学习参数,FFF 表示其中的过滤器数量。对于第一层,H0=XH^{0}=XH0=X,σ(⋅)\sigma(\cdot)σ(⋅) 这里使用Leaky ReLU,Dii=∑jAijD_{ii}=\sum_{j}A_{ij}Dii=∑jAij 是节点度矩阵,D∈RN×ND\in\mathbb{R}^{N\times{N}}D∈RN×N,这和此前的图卷积工作是相似的。Semi-supervised classification with graph convolutional networks
通过优化
(2)L=12M∑i=1M∑j=1P(Wi,j−W~i,j)2\mathcal{L}=\frac{1}{2M}\sum_{i=1}^{M}\sum_{j=1}^{P}(W_{i,j}-\tilde{W}_{i,j})^{2}\tag{2}L=2M1i=1∑Mj=1∑P(Wi,j−W~i,j)2(2)
来训练 GCN 预测参数的能力。MMM 表示训练时类别数目,PPP 表示权重向量的维度。ground truth 权重通过抽取预训练的 CNN 分类器得到。
讲道理这样做的话性能最好也不会超过 CNN 分类网络的性能。
图卷积的拉普拉斯算子可以写作 (I−γD−1L)H(I-\gamma{D}^{-1}L)H(I−γD−1L)H,使用 γ=1\gamma=1γ=1,再结合 L=D−AL=D-AL=D−A 得到 D−1AHD^{-1}AHD−1AH,表示只考虑一阶邻居节点之间的关系。这样使用多层图卷积就能够稀释信息。
Dense Graph Propagation Module
使用 descendant propagation 和 ancestor propagation 来实现目标并避免问题。
使用两个邻接矩阵,Aa∈RN×NA_{a}\in\mathbb{R}^{N\times{N}}Aa∈RN×N 表示节点和其 ancestor 的关联,AdA_{d}Ad 表示节点和其后代的关联,满足 Ad=AaTA_{d}=A_{a}^{T}Ad=AaT。应用的传播公式为:
(3)H=σ(Da−1Aaσ(Dd−1AdXΘd)Θa).H=\sigma\Big(D_{a}^{-1}A_{a}\sigma(D_{d}^{-1}A_{d}X\Theta_{d})\Theta_{a}\Big).\tag{3}H=σ(Da−1Aaσ(Dd−1AdXΘd)Θa).(3)
这里因为打破了原有的连接关系,因此只使用一层网络表示。
距离加权框架
为了使得 DGP 能够更好地衡量不同的“邻居”之间的权重关系,作者提出了新的加权计算框架,通过节点之间距离来计算权重。需要注意的是,权重在原始的知识图谱上计算而不是 dense graph (符合预期)。使用 wa={wia}i=0K\mathcal{w}^{a}=\{\mathcal{w}_{i}^{a}\}_{i=0}^{K}wa={wia}i=0K 和 $ wd={wid}i=0K\mathcal{w}^{d}=\{\mathcal{w}_{i}^{d}\}_{i=0}^{K}wd={wid}i=0K 来表示学习到的对于祖先和后代的传播权重,其中 iii 表示节点之间有 iii 跳,w0\mathcal{w}_{0}w0 表示自环,wK\mathcal{w}_{K}wK 表示距离大于 K−1K-1K−1 的节点之间的权重关系。使用 αka=softmax(wka)=exp(wka)∑i=0Kexpwia\alpha_{k}^{a}=softmax(\mathcal{w}_{k}^{a})=\frac{\exp(\mathcal{w}_{k}^{a})}{\sum_{i=0}^{K}\exp{\mathcal{w}_{i}^{a}}}αka=softmax(wka)=∑i=0Kexpwiaexp(wka) 来归一化权重。
看起来这个公式是和节点无关的,只是单纯通过距离衡量,具体加权参数可学习
作者的实验中 K=4K=4K=4。
作者认为这里的想法是和 attention 机制类似的,但不同的地方在于作者只对有相连关系的节点之间考虑了 attention。实验中作者发现使用完全的 attention 会导致性能下降,作者假设这是由于在给定的信息较少的情况下(稀疏的label graph),更多的复杂探测会使得模型过拟合。
Finetuning
训练过程分两步:
- 训练 DGP 来预测最后一层的预训练 CNN 参数
- 使用 DGP 预测的参数并固定,使用交叉熵损失调整特征提取部分的参数(对于seen class)
实验
21K ImageNet dataset 将不同类别的数据按照距离划分为难易程度不同的集合。并且评价数据集和预训练ResNet-50的数据集中的数据都不相同。
detail
- 使用在 ImageNet 2012 上预训练的 ResNet-50 数据集,以及 在 Wikipedia dataset 上训练的 GloVe 文本模型作为图中的概念特征
- DGP 模型由两层组成组成,特征维度是 2048,最终输出的维度和 ResNet-50 中最后一层的参数个数一致,为 2049 for weights and bias
- 在DGP的输出中使用 L2 正则化,同时也正则化了作为gt的参数值
- 训练过程:每层 Dropout = 0.5,训练 3000 epochs,lr=0.001,使用Adam weight decay=0.0005。leaky ReLUs斜率为0.2
- Finetune过程:20 epochs,使用SGD,学习率0.001,momentum=0.9
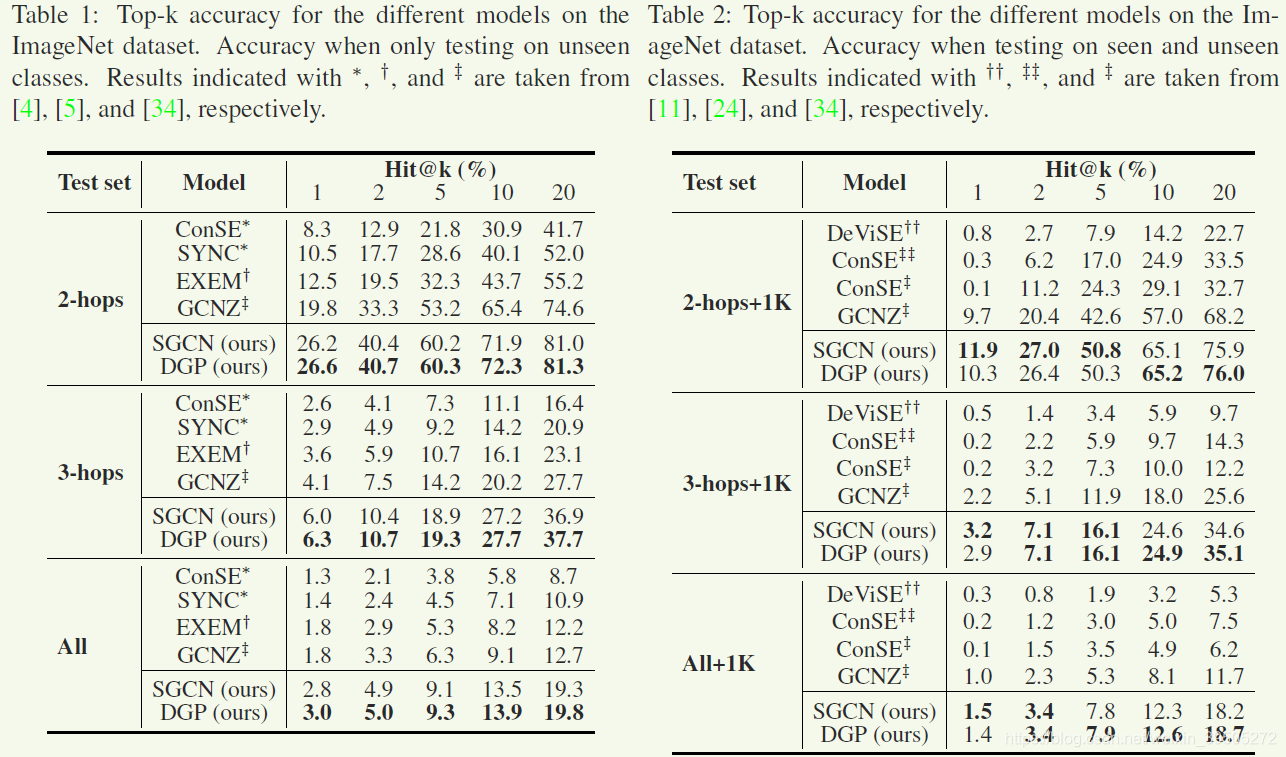
对比实现
- Devise:使用卷积网络提取出来的特征信息,通过线性映射,将语义信息映射到 word-embedding 空间,通过两个空间中的向量距离完成分类
- ConSE:将图像特征映射到一个凸组合中,这个组合是由 T 个最近的 seen 类的语义嵌入通过加权得到的,权重使用图像属于 seen 类的可能性大小获得。最终分类器也是使用距离度量完成分类
- EXEM:通过平均属于同一个 seen 类的图像的PCA投影来创建类别原型,学习一个核回归器,将语义空间嵌入向量映射到原型中,使用这个回归器能够得到 unseen 类的视觉原型,然后使用距离进行分类
- SYNC:将视觉模型空间和语义空间 align,增加一些虚类来链接 seen 和 unseen 的类,将新的嵌入使用虚类的凸组合表示
- GCNZ:使用 GCN 来预测卷积网络中最后一层的参数(和本文最相思)
- SGCN:作者在GCN的基础上将非对称归一化后面加上一个单隐层作为新的baseline,和GCNZ的不同只在于归一化方式不同(即是否对称),作者说这样的非对称归一化方式是有效的。实验结果展示的SGCN也使用了作者提出的两阶段finetune方法
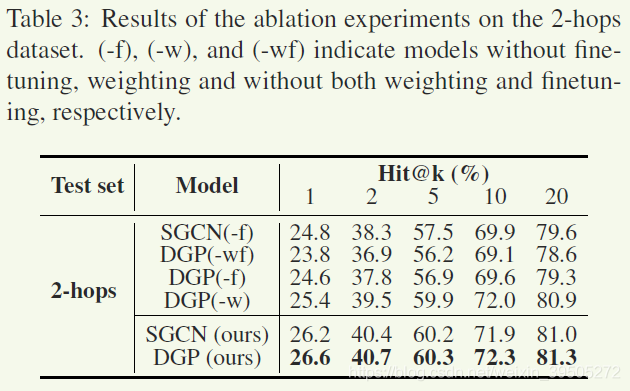
ablation study
TPO-5结果展示

模型分析
加权结构分析
作者对比了按照距离加权模块最终得到的权重,证明距离越近权重越大。
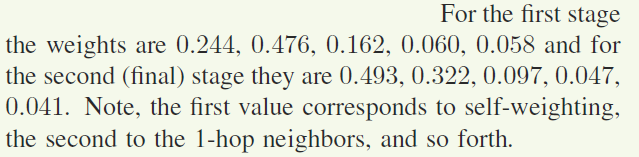
而且远距离的节点产生的影响很小
感觉作者列一个表格更清楚
层数分析
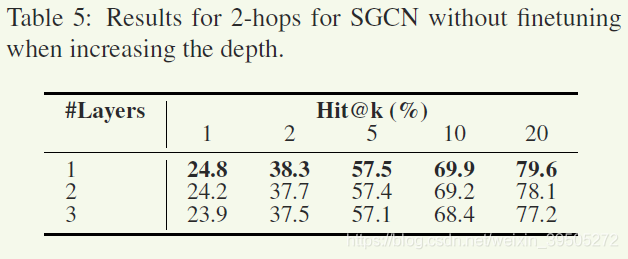
后面总结
两阶段传播的有效性

这里作者对比的是使用完成的邻接矩阵进行两次更新
4000直观来看变化也不是很大,差异基本在0.5,感觉可以认为这并不是主要的作用模块,考虑到作者为了对比用同一个矩阵传播了两次,不知道如果真的单纯使用一个矩阵做结果会怎样。
思考点:
- 为什么通过叠加层次没有效果? 如果作者的结论是正确的,那么不应该是单纯的在这里失效,应该是 GCN 本质上的传播方法失效。不管是什么任务都不想得到一个 over smooth 的结果。作者对于这一点并没有详细证明,只是放上了实验。
- 加权的操作有效的原因 看起来加权的方式只是运用了知识图谱这个先验知识,根据距离得到加权结果。这个效果和直接加权(也就是直接使用attention)的结果相比如何呢?
- Finetune过程 作者使用的finetune过程比较繁琐,而且其实不够直观,有没有 end-to-end 的训练方法呢?单单就预测参数这件事应该是有的,但不能使用现有的loss函数了(因为作者将 pre-train 的 weight 作为了 gt,感觉这也是无奈之举)
- 学习预测参数过程的设计 现在很多 meta 方法都能设计出直接预测参数的端到端监督,可以想象作者这个方法是依赖于 pre-train 效果的,再怎么好也不可能超越 pre-train,而且不排除结果收到 pre-train 影响的可能性(似乎没法证明最后一层的 pre-train 参数就是对当前任务最有效的)

- 【论文学习笔记】Transductive Unbiased Embedding for Zero-Shot Learning (2018_CVPR)
- 论文笔记:Prototypical Networks for Few-shot Learning
- Learning Convolutional Neural Networks for Graphs 论文笔记
- Learning Entity and Relation Embeddings for Knowledge Graph Completion (TransR)论文翻译
- 图割论文阅读笔记:Interactive Graph Cuts for Optimal Boundary & Region Segmentation of Objects in N-D Images
- Deep Neural Networks for Learning Graph Representations论文笔记
- 《Efficient Batch Processing for Multiple Keyword Queries on Graph Data》——论文笔记
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
- 论文笔记之Learning Deep Representations for Graph Clustering
- TAO: Facebook's Distributed Data Store for the Social Graph论文阅读笔记
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
- 【论文笔记】An End-to-End Model for QA over KBs with Cross-Attention Combining Global Knowledge
- 【聚类论文笔记】Cluster Ensembles – A Knowledge Reuse Framework for Combining Multiple Partitions
- 论文笔记:Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
- 论文笔记-Augmented Lagrange Multiplier Method for Recovery of Low-Rank Matrices
- 论文笔记:Research and Implementation of a Multi-label Learning Algorithm for Chinese Text Classification
- 论文笔记 |What makes for effective detection proposals?
- 论文笔记:目标追踪-CVPR2014-Adaptive Color Attributes for Real-time Visual Tracking
- 论文笔记 《What makes for effective detection proposals?》
- [论文笔记] Reputation Propagation in Composite Services (ICWS, 2009)