spark+python快速入门实战小例子(PySpark)
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013305783/article/details/86172654 </div> <link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-cd6c485e8b.css"> <div id="content_views" class="markdown_views prism-atom-one-dark"> <!-- flowchart 箭头图标 勿删 --> <svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <p><font size="4"> 由于目前很多spark程序资料都是用scala语言写的,但是现在需要用python来实现,于是在网上找了scala写的例子改为python实现</font></p>
1、集群测试实例
代码如下:
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.master("spark://mini1:7077") \
.getOrCreate()
spark.conf.set("spark.executor.memory", "500M")
sc = spark.sparkContext
a = sc.parallelize([1, 2, 3])
b = a.flatMap(lambda x: (x,x ** 2))
print(a.collect())
print(b.collect())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果:

2、从文件中读取
为了方便调试,这里采用本地模式进行测试
from py4j.compat import long
from pyspark.sql import SparkSession
def formatData(arr):
# arr = arr.split(",")
mb = (arr[0], arr[2])
flag = arr[3]
time = long(arr[1])
# time = arr[1]
if flag == "1":
time = -time
return (mb,time)if name == “main”:
spark = SparkSession
.builder
.appName(“PythonWordCount”)
.master(“local”)
.getOrCreate()
sc = spark.sparkContext
# sc = spark.sparkContext
line = sc.textFile("D:\\code\\hadoop\\data\\spark\\day1\\bs_log").map(lambda x: x.split(','))
count = line.map(lambda x: formatData(x))
rdd0 = count.reduceByKey(lambda agg, obj: agg + obj)
# print(count.collect())
line2 = sc.textFile("D:\\code\\hadoop\\data\\spark\\day1\\lac_info.txt").map(lambda x: x.split(','))
rdd = count.map(lambda arr: (arr[0][1], (arr[0][0], arr[1])))
rdd1 = line2.map(lambda arr: (arr[0], (arr[1], arr[2])))
rdd3 = rdd.join(rdd1)
rdd4 =rdd0.map(lambda arr: (arr[0][0], arr[0][1], arr[1]))
# .map(lambda arr: list(arr).sortBy(lambda arr1: arr1[2]).reverse)
rdd5 = rdd4.groupBy(lambda arr: arr[0]).values().map(lambda das: sorted(list(das), key=lambda x: x[2], reverse=True))
print(rdd5.collect())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
原文件数据:


结果如下:
[[('18688888888', '16030401EAFB68F1E3CDF819735E1C66', 87600), ('18688888888', '9F36407EAD0629FC166F14DDE7970F68', 51200), ('18688888888', 'CC0710CC94ECC657A8561DE549D940E0', 1300)], [('18611132889', '16030401EAFB68F1E3CDF819735E1C66', 97500), ('18611132889', '9F36407EAD0629FC166F14DDE7970F68', 54000), ('18611132889', 'CC0710CC94ECC657A8561DE549D940E0', 1900)]]- 1
3、读取文件并将结果保存至文件
from pyspark.sql import SparkSession from py4j.compat import long
def formatData(arr):
# arr = arr.split(",")
mb = (arr[0], arr[2])
flag = arr[3]
time = long(arr[1])
# time = arr[1]
if flag == “1”:
time = -time
return (mb,time)
if name == “main”:
spark = SparkSession
.builder
.appName(“PythonWordCount”)
.master(“local”)
.getOrCreate()
sc = spark.sparkContext
line = sc.textFile(“D:\code\hadoop\data\spark\day1\bs_log”).map(lambda x: x.split(’,’))
rdd0 = line.map(lambda x: formatData(x))
rdd1 = rdd0.reduceByKey(lambda agg, obj: agg + obj).map(lambda t: (t[0][1], (t[0][0], t[1])))
line2 = sc.textFile(“D:\code\hadoop\data\spark\day1\lac_info.txt”).map(lambda x: x.split(’,’))
rdd2 = line2.map(lambda x: (x[0], (x[1], x[2])))
rdd3 = rdd1.join(rdd2).map(lambda x: (x[1][0][0], x[0], x[1][0][1], x[1][1][0], x[1][1][1]))
rdd4 = rdd3.groupBy(lambda x: x[0])
rdd5 = rdd4.mapValues(lambda das: sorted(list(das), key=lambda x: x[2], reverse=True)[:2])
print(rdd1.join(rdd2).collect())
print(rdd5.collect())
rdd5.saveAsTextFile("D:\\code\\hadoop\\data\\spark\\day02\\out1")
sc.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
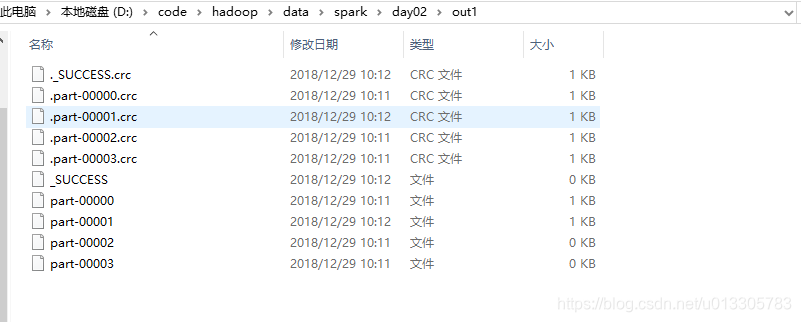
4、根据自定义规则匹配
import urllib from pyspark.sql import SparkSession def getUrls(urls): url = urls[0] parsed = urllib.parse.urlparse(url) return (parsed.netloc, url, urls[1])
if name == “main”:
spark = SparkSession
.builder
.appName(“PythonWordCount”)
.master(“local”)
.getOrCreate()
sc = spark.sparkContext
line = sc.textFile(“D:\code\hadoop\data\spark\day02\itcast.log”).map(lambda x: x.split(’\t’))
//从数据库中加载规则
arr = [“java.itcast.cn”, “php.itcast.cn”, “net.itcast.cn”]
rdd1 = line.map(lambda x: (x[1], 1))
rdd2 = rdd1.reduceByKey(lambda agg, obj: agg + obj)
rdd3 = rdd2.map(lambda x: getUrls(x))
for ins in arr: rdd = rdd3.filter(lambda x:x[0] == ins) result = rdd.sortBy(lambda x: x[2], ascending = False).take(2) print(result) spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25 26
结果如下:

5、自定义类排序
from operator import gt from pyspark.sql import SparkSession
class Girl:
def init(self, faceValue, age):
self.faceValue = faceValue
self.age = age
def __gt__(self, other): if other.faceValue == self.faceValue: return gt(self.age, other.age) else: return gt(self.faceValue, other.faceValue)
if name == “main”:
spark = SparkSession
.builder
.appName(“PythonWordCount”)
.master(“local”)
.getOrCreate()
sc = spark.sparkContext
rdd1 = sc.parallelize([(“yuihatano”, 90, 28, 1), (“angelababy”, 90, 27, 2), (“JuJingYi”, 95, 22, 3)])
rdd2 = rdd1.sortBy(lambda das: Girl(das[1], das[2]),False)
print(rdd2.collect())
sc.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
结果如下:

6、JDBC
from pyspark import SQLContext from pyspark.sql import SparkSession
if name == “main”:
spark = SparkSession
.builder
.appName(“PythonWordCount”)
.master(“local”)
.getOrCreate()
sc = spark.sparkContext
sqlContext = SQLContext(sc)
df = sqlContext.read.format(“jdbc”).options(url=“jdbc:mysql://localhost:3306/hellospark”,driver=“com.mysql.jdbc.Driver”,dbtable="(select * from actor) tmp",user=“root”,password=“123456”).load()
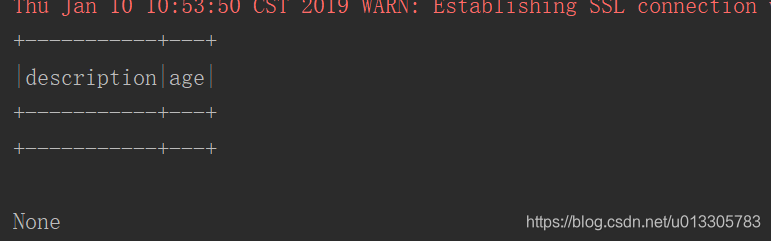
print(df.select(‘description’,‘age’).show(2))
# print(df.printSchema)
sc.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
结果如下:
</div> <link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-e44c3c0e64.css" rel="stylesheet"> </div>

- Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫)
- 转:Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫)
- 精选2个小例子,带你快速入门Python文件处理
- Python3网络爬虫快速入门实战解析
- python入门实战小例子(一朵花的绽放)(花が咲く)
- Python3网络爬虫快速入门实战解析
- Spark英中对照翻译(PySpark中文版新手快速入门-Quick Start)-中文指南,教程(Python版)-20161115
- 2019最新Python从入门到精通之30天快速学Python项目实战(完整)
- Python3网络爬虫快速入门实战解析
- flask框架实战—简单图片社交网站(一):Python语言快速入门
- Python3网络爬虫快速入门实战解析
- Python 爬虫---(7) Python3网络爬虫快速入门实战解析
- Python 学习(二)【快速入门】
- [转] Python快速入门
- 02 python3-第一次写python程序入门例子(调用turtle画图)
- 七步快速入门 Python机器学习
- Selenium with Python 002 - 快速入门
- python 快速入门
- Python语言十分钟快速入门
- Python pandas快速入门