大话注意力机制(Attention Mechanism)

当我们人类在看东西时,一般会将注意力集中注视着某个地方,而不会关注全部所有信息。例如当我们一看到下面这张猫的图片时,主要会将目光停留在猫的脸部,以及留意猫的躯干,而后面的草地则会被当成背景忽略掉,也就是说我们在每一处空间位置上的注意力分布是不一样的。

通过这种方式,人类在需要重点关注的目标区域,会投入更多的注意力资源,以获取更多的细节信息,而抑制其它区域信息,这样使人类能够利用有限的注意力资源从大量信息中快速获取到高价值的信息,极大地提升了大脑处理信息的效率。
那么人类的这种“注意力机制”是否可用在AI中呢?
我们来看一下,图片描述(Image Caption)中引入了“注意力机制”后的效果。“图片描述”是深度学习的一个典型应用,即输入一张图片,AI系统根据图片上的内容输出一句描述文字出来。下面看一下“图片描述”的效果,左边是输入原图,下边的句子是AI系统自动生成的描述文字,右边是当AI系统生成划横线单词的时候,对应图片中聚焦的位置区域,如下图:

可以看到,当输出frisbee(飞碟)、dog(狗)等单词时,AI系统会将注意力更多地分配给图片中飞碟、狗的对应位置,以获得更加准确地输出,是不是很神奇呢,这又是如何实现的呢?
1、什么是“注意力机制”
深度学习中的注意力机制(Attention Mechanism)和人类视觉的注意力机制类似,就是在众多信息中把注意力集中放在重要的点上,选出关键信息,而忽略其他不重要的信息。
2、Encoder-Decoder框架(编码-解码框架)
目前大多数的注意力模型附着在Encoder-Decoder框架下,所以我们先来了解下这个框架。Encoder-Decoder框架可以看作是一种文本处理领域的研究模式,该框架的抽象表示如下图:

给定输入X,通过Encoder-Decoder框架生成目标Y。其中,Encoder(编码器)就是对输入X进行编码,通过非线性变换转化为中间语义表示C;Decoder(解码器),根据输入X的语义表示C和之前已生成的历史信息生成目标信息。
Encoder-Decoder框架是个通用框架,有很多的场景,在文本处理、图像处理、语音识别等各领域经常使用,Encoder、Decoder可使用各种模型组合,例如CNN/RNN/BiRNN/LSTM等。例如对于自动问答,X是一个问句,Y是答案;对于机器翻译,X是一种语言,Y是另外一种语言;对于自动摘要,X是一篇文章,Y是摘要;对于图片描述,X是一张图片,Y是图片的文字描述内容……
3、注意力模型
本文开头讲到的人类视觉注意力机制,它在处理信息时注意力的分布是不一样的。而Encoder-Decoder框架将输入X都编码转化为语义表示C,这样就会导致所有输入的处理权重都一样,没有体现出注意力集中,因此,也可看成是“分心模型”。
为了能体现注意力机制,将语义表示C进行扩展,用不同的C来表示不同注意力的集中程度,每个C的权重不一样。那么扩展后的Encoder-Decoder框架变为:

下面通过一个英文翻译中文的例子来说明“注意力模型”。
例如输入的英文句子是:Tom chase Jerry,目标的翻译结果是“汤姆追逐杰瑞”。那么在语言翻译中,Tom, chase, Jerry这三个词对翻译结果的影响程度是不同的,其中,Tom, Jerry是主语、宾语,是两个人名,chase是谓语,是动作,那么这三个词的影响程度大小顺序分别是Jerry>Tom>chase,例如(Tom,0.3)(Chase,0.2) (Jerry,0.5),不同的影响程度代表AI模型在翻译时分配给不同单词的注意力大小,即分配的概率大小。
使用上图扩展了Ci的Encoder-Decoder框架,则翻译Tom chase Jerry的过程如下。
生成目标句子单词的过程如下面的形式:
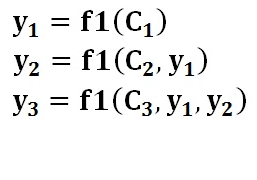
其中,f1是Decoder(解码)的非线性变换函数
每个Ci对应着不同的源单词的注意力分配概率分布,计算如下面的形式:

其中,f2函数表示Encoder(编码)节点中对输入英文单词的转换函数,g函数代表Encoder(编码)表示合成整个句子中间语义表示的变换函数,一般采用加权求和的方式,如下式:

其中aij表示权重,hj表示Encoder的转换函数,即h1=f2(“Tom”),h2=f2(“Chase”),h3=f2(“Jerry”),Tx表示输入句子的长度
当i是“汤姆”时,则注意力模型权重aij分别是0.6, 0.2, 0.2。那么这个权重是如何得到的呢?
aij可以看做是一个概率,反映了hj对ci的重要性,可使用softmax来表示:
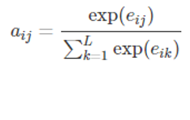
其中,
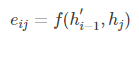
这里的f表示一个匹配度的打分函数,可以是一个简单的相似度计算,也可以是一个复杂的神经网络计算结果。在这里,由于在计算ci时还没有h’i,因此使用最接近的h’i-1代替。当匹配度越高,则aij的概率越大。
因此,得出aij的过程如下图:
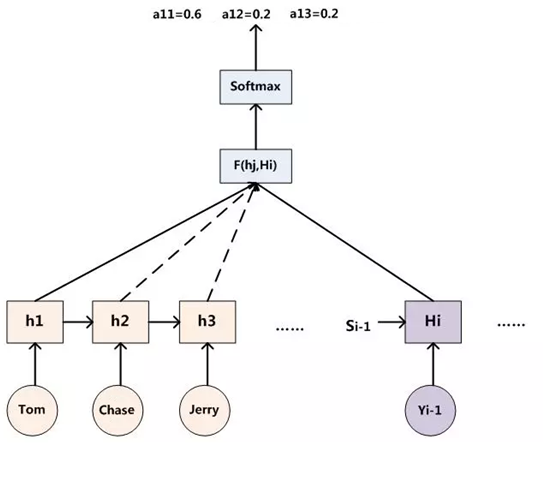
其中,hi表示Encoder转换函数,F(hj,Hi)表示预测与目标的匹配打分函数
将以上过程串起来,则注意力模型的结构如下图所示:
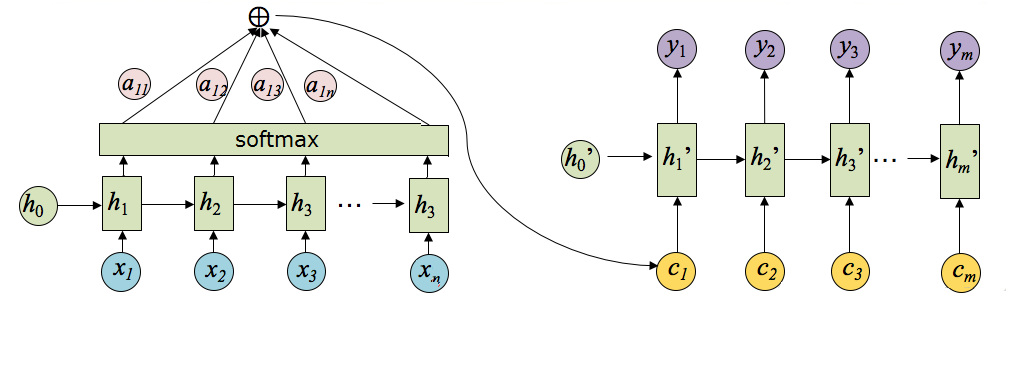
其中,hi表示Encoder阶段的转换函数,ci表示语义编码,h’i表示Decoder阶段的转换函数。
以上介绍的就是经典的Soft-Attention模型,而注意力模型按不同维度还有其它很多分类。
4、注意力模型的分类
按注意力的可微性,可分为:
- Hard-Attention,就是0/1问题,某个区域要么被关注,要么不关注,这是一个不可微的注意力;
- Soft-Attention,[0,1]间连续分布问题,用0到1的不同分值表示每个区域被关注的程度高低,这是一个可微的注意力。
按注意力的关注域,可分为:
- 空间域(spatial domain)
- 通道域(channel domain)
- 层域(layer domain)
- 混合域(mixed domain)
- 时间域(time domain)
推荐相关阅读
1、AI 实战系列
- 【AI实战】手把手教你文字识别(文字检测篇:MSER、CTPN、SegLink、EAST 等)
- 【AI实战】手把手教你文字识别(入门篇:验证码识别)
- 【AI实战】快速掌握TensorFlow(一):基本操作
- 【AI实战】快速掌握TensorFlow(二):计算图、会话
- 【AI实战】快速掌握TensorFlow(三):激励函数
- 【AI实战】快速掌握TensorFlow(四):损失函数
- 【AI实战】搭建基础环境
- 【AI实战】训练第一个模型
- 【AI实战】编写人脸识别程序
- 【AI实战】动手训练目标检测模型(SSD篇)
- 【AI实战】动手训练目标检测模型(YOLO篇)
2、大话深度学习系列
- 【精华整理】CNN进化史
- 大话文本识别经典模型(CRNN)
- 大话文本检测经典模型(CTPN)
- 大话文本检测经典模型(SegLink)
- 大话文本检测经典模型(EAST)
- 大话文本检测经典模型(PixelLink)
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 大话CNN经典模型:AlexNet
- 大话CNN经典模型:VGGNet
- 大话CNN经典模型:GoogLeNet
- 大话目标检测经典模型:RCNN、Fast RCNN、Faster RCNN
- 大话目标检测经典模型:Mask R-CNN
- 大话注意力机制
3、图解 AI 系列
4、AI 杂谈
5、大数据超详细系列
(adsbygoogle = window.adsbygoogle || []).push({});
- 北哥大话Yii2缓存机制 - DbCache
- NLP系列(9)_深入理解BERT Transformer ,不仅仅是注意力机制
- 大话Android Touch事件传递机制
- 神经网络注意力机制--Attention in Neural Networks
- 北哥大话Yii2缓存机制 - 缓存依赖
- Attention注意力机制--原理与应用
- 注意力机制(Attention Mechanism)
- 大话微服务」深入聊聊SpringCloud之客户端负载均衡机制
- 常见的两种注意力机制
- 注意力机制
- 关于深度学习中的注意力机制
- 基于自注意力机制的下一项推荐
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
- 深度学习中的注意力机制
- 关于深度学习中的注意力机制,这篇文章从实例到原理都帮你参透了
- 5.3.1 时序模型和注意力机制
- 三种还是四种NLP的注意力机制的总结
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
- 吴恩达《深度学习-序列模型》3 -- 序列模型和注意力机制