(二)urllib和urllib3+爬虫一般开发流程?python+scrapy爬虫5小时入门
2019-06-13 22:09
218 查看
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/weixin_40771510/article/details/91900971
urllib和urllib3+爬虫一般开发流程
urllib
urllib 是一个用来处理网络请求的python标准库,它包含4个模块。 urllib.requests => 请求模块,用于发起网络请求 urllib.parse => 解析模块,用于解析URL urllib.error => 异常处理模块,用于处理request引起的异常 urllib.robotparse => 用于解析robots.txt文件
urllib.request模块:
request模块主要负责构造和发起网络请求,并在其中添加Headers,Proxy等。利用它可以模拟浏览器的请求发起过程。 1.发起网络请求 3.操作cookie 2.添加Headers 4.使用代理
urlopen方法:
urlopen是一个简单发送网络请求的方法。它接收一个字符串格式的url,它会向传入的url发送网络请求,然后返回结果。 from urllib import request respone = request.urlopen(url="http://httpbin.org/get") urlopen默认会发送get请求,当传入data参数时,则会发起POST请求。data参数是字节类型、者类文件对象或可迭代对象。 response = request.urlopen(url='http://httpbin.org/get',data=b'username=xinlan&password=123456') 还才可以设置超时,如果请求超过设置时间,则抛出异常。timeout没有指定则用系统默认设置,timeout只对,http,https以及ftp连接起作用。它以秒为单位,比如可以设置timeout=0.1 超时时间为0.1秒。 response = request.urlopen(url='http://httpbin.org/get',timeout=0.1)
Request对象
利用urlopen可以发起最基本的请求,但这几个简单的参数不足以构建一个完整的请求,可以利用更强大的Request对象来构建更加完整的请求。
req = request.Request('http://httpbin.org/get')
response = request.urlopen(req)
请求头添加
通过urllib发送的请求会有一个默认的Headers: “User-Agent”:“Python-urllib/3.6”,指明请求是由urllib发送的。所以遇到一些验证User-Agent的网站时,需要我们自定义Headers把自己伪装起来。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "}
print(headers)
url = 'http://httpbin.org/get'
req = request.Request('http://www.baidu.com',headers=headers)
2. 操作cookie
在开发爬虫过程中,对cookie的处理非常重要,urllib的cookie的处理如下案例:
from urllib import request
from import cookiejar
创建一个cookie对象
cookie = cookiejar。Cookiejar()
创建一个cookie处理器
cookies = request.HTTPCookieProcessor(cookie)
以它为参数,创建Openner对象
opener = request.build_opener(cookies)
使用这个opener来发送请求
res = opener.open('http://www.baidu.com')
print(cookies.cookiejar)
3. 设置代理
运行爬虫的时候,经常会出现被封IP的情况,这时我们就需要使用ip代理来处理,urllib的IP代理的设置如下:
from urllib import request
url = 'http://httpbin.org/get'
代理地址
proxy = {'http':'192.168.251.66:3128'}
代理处理器
proxies = request.ProxyHandler(proxy)
创建opener对象
opener = request.buid_opener(proxies)
res = opener.open(url)
print(res.read().decode())
Response对象
urlib库中的类或或者方法,在发送网络请求后,都会返回一个urllib.response的对象。它包含了请求回来的数据结果。它包含了一些属性和方法,供我们处理返回的结果。 - read() 获取响应返回的数据,只能用一次 Response.read() - readline() 读取一行 - info() 获取响应头信息 - geturl() 获取访问的url - getcode() 返回状态码
urllib.parse模块
parse模块是一个工具模块,提供了需要对url处理的方法,用于解析url。
parse.quote()
url中只能包含ascii字符,在实际操作过程中,get请求通过url传递的参数中会有大量的特殊字符,例如汉字,那么就需要进行url编码。
例如https://baike.baidu.com/item/URL编码/3703727?fr=aladdin
我们需要将编码进行url编码
url = "http://httpbin.org/get?aaa={}".format(parse.quote('小民'))
利用parse.unquote()可以反编码回来。
parse.urlencode()
在发送请求的时候,往往会需要传递很多的参数,如果用字符串方法去拼接会比较麻烦,parse.urlencode()方法就是用来拼接url参数的。
params = {'wd': '测试','code':'1', 'height':'188'}
res = param.urlencode(params)
结果: wd=%E6%B5%E8%95&code=1&height=188
也可以通过parse.parse_qs()方法将它转回字典
print(parse.parse_qs('wd=%E6%B5%E8%95&code=1&height=188'))
结果:{'wd': '测试','code':'1', 'height':'188'}
urllib.error模块
error模块主要负责处理异常,如果请求出现错误,我们可以用error模块进行处理主要包含URLError和HTTPError 1.URLError:是error异常模块的基类,由request模块产生的异常都可以用这个类来处理 2.HTTPError:是URLError的子类,主要包含三个属性: code:请求的状态码 reason:错误的原因 headers:响应的报头
urllib.robotparse模块
robotparse模块主要负责处理爬虫协议文件,robots.txt.的解析。https://docs.python.org/3/library/urllib.robotparser.html https://www.baidu.com/robots.txt Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它 [1] 。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
urllib3
urllib3 是一个基于python3的功能强大,友好的http客户端。越来越多的python应用开始采用urllib3.它提供了很多python标准库里没有的重要功能。
urllib3通过pip来安装:pip install urllib3
urllib3功能强大使用简单:
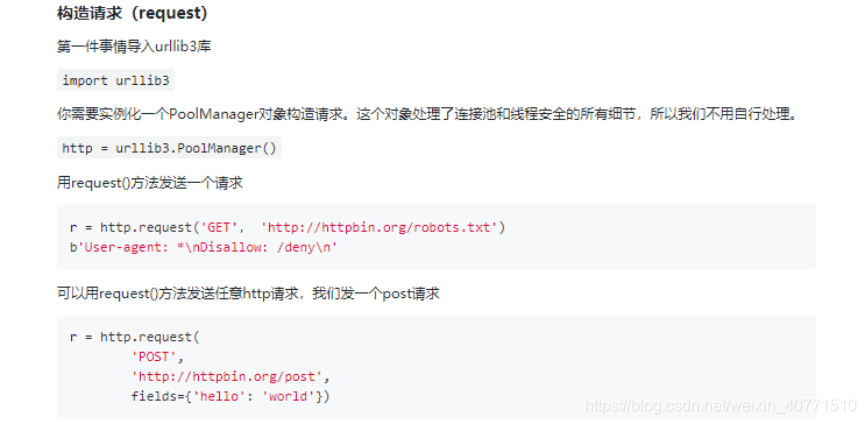
import urllib3
http = urllib3.PoolManager()
r = http.request('GET','http://www.baidu.com')
print(r.status)
print(r.data)
构造请求(request)
Response content
http响应对象提供status, data,和header等属性。
http = urllib3.PoolManager()
r = http.request('GET','http://httpbin.org/ip')
print(r.status)
print(r.data)
print(r.headers)
运行结果:
JSON content
返回的json格式数据可以通过json模块,load为字典数据类型。
import urllib3
import json
http = urllib3.PoolManager()
r = http.request('GET','http://httpbin.org/ip')
print(json.loads(r.data.decode('utf-8')))
运行结果:
{'origin':'110.53.182.23'}
Binary content
响应返回的数据都是字节类型,对于大量的数据我们通过stream来处理更好:
http = urllib3.PoolManager()
r = http.request('GET','http://httpbin.org/bytes/1024',preload_content=Fales)
for chunk in r.stream(32):
print(chunk)
也可以当作一个文件对象来处理
http = urllib3.PoolManager()
r = http.request('GET','http://httpbin.org/bytes/1024',preload_content=Fales)
for line in r:
print(line)
Proxies
可以利用ProxyManager进行http代理操作
proxy = urllib3.ProxyManager('http://180.76.111.69:3128')
res = proxy.request('get','http://httpbin.org/ip')
print(res.data)
Request data
Headers
request方法中添加字典格式的headers参数去指定请求头
http = urllib3.ProxyManager()
r = http.request('get','http://httpbin.org/headers',headers={'key':'value'})
print(json.loads(r.data.decode('utf-8')))
Query parameters
get,head,delete请求,可以通过提供字典类型的参数fields来添加查询参数。
http = urllib3.ProxyManager()
r = http.request('get','http://httpbin.org/get',fields={'arg':'value'})
print(json.loads(r.data.decode('utf-8'))['args'])
对于post和put请求,如果需要查询参数,需要通过url编码将参数编码成正确格式然后拼接到url中
import urllib3
import json
from urllib.parse import urlencode
http = urllib3.ProxyManager()
encoded_args = urlencode({'arg':'value'})
url = 'http://httpbin.org/post?' + encoded_args
r = http.request('POST',url)
print(json.loads(r.data.decode('utf-8'))['args'])
Request data
Form data
对于put和post请求,需要提供字典类型的参数field来传递form表单数据。
r = http.request('POST','http://httpbin.org/post',fields={'field':'value'})
print(json.loads(r.data.decode('utf-8'))['form'])
JSON
当我们需要发送json数据时,我们需要在request中传入编码后的二进制数据类型的body参数,并制定Content-Type的请求头
http = urllib3.ProxyManager()
data = {'arg':'value'}
encoded_data = json.dumps(data).encode('utf-8')
url = ?' + encoded_args
r = http.request('POST','http://httpbin.org/post',body=encoded_data,headers={'Content-Type':'application/json'})
print(json.loads(r.data.decode('utf-8'))['json'])
Files & binary data
对于文件上传,我们可以模仿浏览器表单的方式
with open('example.txt') as fp:
file_data = fp.read()
r = http.request('POST','http://httpbin.org/post',fields={'filefield':('example.txt', file_data),})
print(json.loads(r.data.decode('utf-8'))['files'])
对于二进制的数据上传,我们用指定body的方式,并设置Content-Type的请求头
http = urllib3.ProxyManager()
with open('example.jpg','rb') as fp:
binary_data = fp.read()
r = http.request('POST','http://httpbin.org/post',body=binary_data,headers={'Content-Type':'image/jpeg'})
print(json.loads(r.data.decode('utf-8')))
爬虫一般开发流程
开发一个爬虫可以简单的分为一下5个步骤 1.找到目标数据 2.分析请求流程 3.构造http请求 4.提取清洗数据 5.数据持久化 [存储或者写入数据库]
作业
1.利用urllib3 下载 http://desk.zol.com.cn/pc/首页所有封面图片, 只需要下载封面(一共15张),保存到当前文件夹下的imgs文件夹.

相关文章推荐
- (六)Scrapy框架(一) ?python+scrapy爬虫5小时入门
- Python爬虫 scrapy框架 原理,scrapy开发流程
- (三)Requests库的使用?python+scrapy爬虫5小时入门
- (四)fiddler之filters python+scrapy爬虫5小时入门
- (五)网页解析-提取结构化数据-BeautifulSoup+Xpath python+scrapy爬虫5小时入门
- (六)Scrapy框架(一) ?python+scrapy爬虫5小时入门
- (七)Scrapy框架(二) ?python+scrapy爬虫5小时入门
- Python爬虫框架Scrapy教程(1)—入门
- Python爬虫入门-利用scrapy爬取淘女郎照片
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
- python爬虫入门笔记:用scrapy爬豆瓣
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- Python 爬虫入门 1 了解爬虫Scrapy
- python爬虫入门笔记:用scrapy爬豆瓣
- python爬虫开发(6)—爬虫入门--Requests爬虫(cookie)
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
- Python爬虫入门四之Urllib库的高级用法
- Python爬虫入门教程 31-100 36氪(36kr)数据抓取 scrapy
- [爬虫入门]Python中使用scrapy框架实现图片爬取