深入理解JVM——第六章 JVM调优和深入了解性能优化笔记
VM调优的本质:并不是显著的提高系统性能,不是说你调了,性能就能提升几倍或者上十倍,JVM调优,主要调的是稳定。如果你的系统出现了频繁的垃圾回收,这个时候系统是不稳定的,所以需要我们来进行JVM调优,调整垃圾回收的频次。
一、GC调优原则
调优的原则:
- 大多数的java应用不需要GC调优
- 大部分需要GC调优的的,不是参数问题,是代码问题
- 在实际使用中,分析GC情况优化代码比优化GC参数要多得多;
- GC调优是最后的手段
目的:
GC的时间够小,GC的次数够少。
发生Full GC的周期足够的长,时间合理,最好是不发生。
注意:
如果满足下面的指标,则一般不需要进行GC:
- Minor GC执行时间不到50ms;
- Minor GC执行不频繁,约10秒一次;
- Full GC执行时间不到1s;
- Full GC执行频率不算频繁,不低于10分钟1次;
1、调优步骤
1.1、日志分析
1)监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化。
2)分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化;如果GC时间超过1-3秒,或者频繁GC,则必须优化;
3)调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择;
4)不断的分析和调整
通过不断的试验和试错,分析并找到最合适的参数
5)全面应用参数
如果找到了最合适的参数,则将这些参数应用到所有服务器,并进行后续跟踪。
1.2、阅读GC日志
主要关注MinorGC和FullGC 的回收效率(回收前大小和回收比较)、回收的时间。
-XX:+UseSerialGC方式:
以参数-Xms5m -Xmx5m -XX:+PrintGCDetails -XX:+UseSerialGC为例:
[DefNew: 1855K->1855K(1856K), 0.0000148 secs][Tenured: 2815K->4095K(4096K), 0.0134819 secs] 4671K
DefNew指明了收集器类型,而且说明了收集发生在新生代;1855K->1855K(1856K)表示回收前新生代占用1855K,回收后占用1855K,新生代大小1856K;0.0000148 secs表明新生代回收耗时;Tenured表明收集发生在老年代,2815K->4095K(4096K), 0.0134819 secs:含义同新生代,最后的4671K指明堆的大小。
-XX:+UseParNewGC方式:
收集器参数变为-XX:+UseParNewGC,日志变为:
[ParNew: 1856K->1856K(1856K), 0.0000107 secs][Tenured: 2890K->4095K(4096K), 0.0121148 secs]
收集器参数变为-XX:+ UseParallelGC或UseParallelOldGC,日志变为:
[PSYoungGen: 1024K->1022K(1536K)] [ParOldGen: 3783K->3782K(4096K)] 4807K->4804K(5632K),
-XX:+UseConcMarkSweepGC方式:
CMS收集器和G1收集器会有明显的相关字样
-XX:+UseG1GC方式:
2、GC调优实战
2.1、项目启动GC优化
开启日志分析 -XX:+PrintGCDetails 发现有多次GC包括FullGC
第一步:调整Metadata空间 -XX:MetaspaceSize=64m:
PSYoungGen出现了4次,FullGC消失。
第二步:减少Minor gc次数,增加参数 -Xms500m
GC减少至2次,FullGC消失。
第三步:减少Minor gc次数,调整参数 -Xms1000m
GC减少至2次,FullGC消失(说明增加堆空间已经不起作用)。
第四步:增加新生代比重,增加参数 -Xmn900m
GC减少至1次。
第五步:加大新生代,调整参数 -Xms2000m -Xmn1800m
GC减少至0次。
备注:如果继续增大内存空间,还是避免不了GC,没有必要调整这么大。
2.2、项目运行GC优化
使用jmeter同时访问三个接口,index、time、noblemetal
使用40个线程,循环250次进行压力测试,观察并发的变化
备注:JMeter性能测试可以参考下面文档
https://blog.csdn.net/u012111923/article/details/80705141

2.3、线程组参数详解:
1. 线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
2. Ramp-Up Period(in seconds)准备时长:设置的虚拟用户数需要多长时间全部启动。如果线程数为10,准备时长为2,那么需要2秒钟启动10个线程,也就是每秒钟启动5个线程。
3. 循环次数:每个线程发送请求的次数。如果线程数为10,循环次数为100,那么每个线程发送100次请求。总请求数为10*100=1000。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
4. Delay Thread creation until needed:直到需要时延迟线程的创建。
5. 调度器:设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为永远)
持续时间(秒):测试持续时间,会覆盖结束时间
启动延迟(秒):测试延迟启动时间,会覆盖启动时间
启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
结束时间:测试结束时间,持续时间会覆盖它。
因为接口调试需要,我们暂时均使用默认设置,待后面真正执行性能测试时再回来配置。
2.4、聚合报告参数详解:
- Label:每个JMeter的element(例如 HTTP Request)都有一个Name属性,这里显示的就是Name属性的值 。
- #Samples:请求数——表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100 。
- Average:平均响应时间——默认情况下是单个Request的平均响应时间,当使用了Transaction Controller 时,以Transaction为单位显示平均响应时间 。
- Median:中位数,也就是50%用户的响应时间 。
- 90% Line:90%用户的响应时间 。
- Min:最小响应时间 。
- Max:最大响应时间 。
- Error%:错误率——错误请求数/请求总数 。
- Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了Transaction Controller时,也可以表示类似LoadRunner的Transaction per Second数 。
- KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec。
一般而言,性能测试中我们需要重点关注的数据有: #Samples 请求数,Average 平均响应时间,Min 最小响应时间,Max 最大响应时间,Error% 错误率及Throughput 吞吐量。
方式一:使用单线程GC
-XX:+UseSerialGC
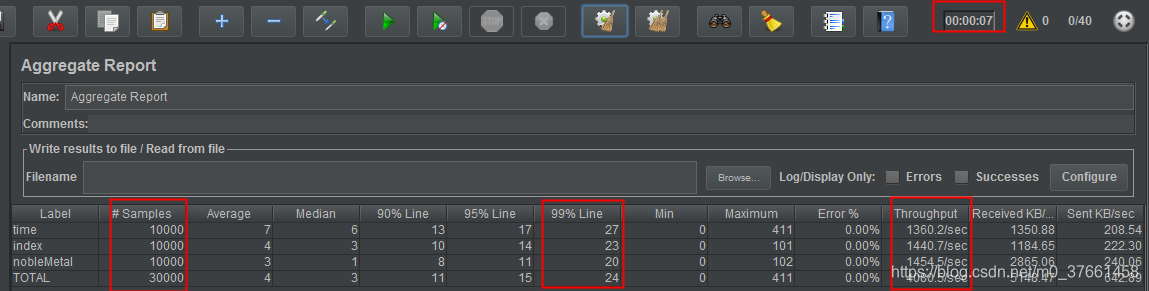
分析:总共执行30000次请求,耗时7秒,吞吐量为4080.52/秒
方式二:使用多线程GC:
-XX:+UseParNewGC

分析:总共执行30000次请求,耗时5秒,吞吐量为4287.55/秒
方式三:使用CMS:
-XX:+UseConcMarkSweepGC

分析:总共执行30000次请求,耗时7秒,吞吐量为4205.8/秒
方式四:使用G1
-XX:+UseG1GC

分析:总共执行30000次请求,耗时7秒,吞吐量为4291.23/秒
方式五:代码问题影响GC结果
一行代码导致频繁GC,吞吐量下降很快(同样适用:-XX:+UseG1GC)
[code]@Service
public class FillMemory extends Thread{
private static Logger logger = LoggerFactory.getLogger(FillMemory.class);
private List<byte[]> listByte = new LinkedList<>();
@Override
public void run() {
while(!Thread.currentThread().isInterrupted()) {
listByte.clear();
logger.info("开始填充..........");
for(int i=0;i<500;i++) {
byte[] bytes = new byte[1*1024*1024];
listByte.add(bytes);
}
logger.info("..........填充完毕");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
}
}
@PostConstruct
public void init() {
this.start();
}
}
执行结果:

分析:总共执行30000次请求,耗时8秒,吞吐量为3455.4/秒。
3、推荐策略
3.1、新生代大小选择
- 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择),在此种情况下,新生代收集发生的频率也是最小的,同时减少到达老年代的对象。
- 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度,因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
- 避免设置过小:当新生代设置过小时会导致:1)YGC次数更加频繁 2)可能导致YGC对象直接进入旧生代,如果此时旧生代满了,会触发FullGC。
3.2、老年代大小选择
响应时间优先的应用:老年代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片,高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:并发垃圾收集信息、持久代并发收集次数、传统GC信息、花在新生代和老年代回收上的时间比例。
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的新生代和一个较小的老年代。原因是这样可以尽可能回收掉大部分短期对象,减少中期的对象,而老年代尽存放长期存活对象。
调优是个很复杂、很细致的过程,要根据实际情况调整,不同的机器、不同的应用、不同的性能要求调优的手段都是不同的,即使是jvm参数也是如此,比如说性能有关的操作系统工具,和操作系统本身相关的所谓大页机制,都需要平时去积累,去观察,去实践。
4、逃逸分析
是JVM所做的最激进的优化,最好不要调整相关的参数。
牵涉到的JVM参数:
-XX:+DoEscapeAnalysis:启用逃逸分析(默认打开)
-XX:+EliminateAllocations:标量替换(默认打开)
-XX:+UseTLAB 本地线程分配缓冲(默认打开)
如果是逃逸分析出来的对象可以在栈上分配的话,那么该对象的生命周期就跟随线程了,就不需要垃圾回收,如果是频繁的调用此方法则可以得到很大的性能提高。
5、常用的性能评价/测试指标
一个web应用不是一个孤立的个体,它是一个系统的部分,系统中每一部分都会影响整个系统的性能
5.1、响应时间
提交请求和返回该请求的响应之间使用的时间,一般比较关注平均响应时间。
常用操作的响应时间列表:
|
操作 |
响应时间 |
|
打开一个站点 |
几秒 |
|
数据库查询一条记录(有索引) |
十几毫秒 |
|
机械磁盘一次寻址定位 |
4毫秒 |
|
从机械磁盘顺序读取1M数据 |
2毫秒 |
|
从SSD磁盘顺序读取1M数据 |
0.3毫秒 |
|
从远程分布式换成Redis读取一个数据 |
0.5毫秒 |
|
从内存读取1M数据 |
十几微妙 |
|
Java程序本地方法调用 |
几微妙 |
|
网络传输2Kb数据 |
1微妙 |
5.2、并发数
同一时刻,对服务器有实际交互的请求数。
和网站在线用户数的关联:1000个同时在线用户数,可以估计并发数在5%到15%之间,也就是同时并发数在50~150之间。
5.3、吞吐量 1f9fe
对单位时间内完成的工作量(请求)的量度
5.4、关系
系统吞吐量和系统并发数以及响应时间的关系:
理解为高速公路的通行状况:
吞吐量是每天通过收费站的车辆数目(可以换算成收费站收取的高速费),
并发数是高速公路上的正在行驶的车辆数目,
响应时间是车速。
车辆很少时,车速很快。但是收到的高速费也相应较少;随着高速公路上车辆数目的增多,车速略受影响,但是收到的高速费增加很快;
随着车辆的继续增加,车速变得越来越慢,高速公路越来越堵,收费不增反降;
如果车流量继续增加,超过某个极限后,任务偶然因素都会导致高速全部瘫痪,车走不动,当然后也收不着,而高速公路成了停车场(资源耗尽)。
二、常用的性能优化手段
避免过早优化:不应该把大量的时间耗费在小的性能改进上,过早考虑优化是所有噩梦的根源。
所以,我们应该编写清晰,直接,易读和易理解的代码,真正的优化应该留到以后,等到性能分析表明优化措施有巨大的收益时再进行。过早优化,不表示我们就可以随便写代码,还是需要注重编写高效优雅的代码。
进行系统性能测试:
所有的性能调优,都有应该建立在性能测试的基础上,直觉很重要,但是要用数据说话,可以推测,但是要通过测试求证;寻找系统瓶颈,分而治之,逐步优化。
性能测试后,对整个请求经历的各个环节进行分析,排查出现性能瓶颈的地方,定位问题,分析影响性能的的主要因素是什么?内存、磁盘IO、网络、CPU,还是代码问题?架构设计不足?或者确实是系统资源不足?
1、前端优化常用手段
1.1、浏览器/App
- 减少请求数
- 合并CSS,Js,图片,
- 生产服务器提供的all的js文件
- http中的keep-alive(http1.1中默认开启)包括nginx
1)使用客户端缓冲:
静态资源文件(css、图标等)缓存在浏览器中,有关的属性Cache-Control(相对时间)和Expires
如果文件发生了变化,需要更新,则通过改变文件名来解决。
2)启用压缩
浏览器(zip),压缩率80%以上。
减少网络传输量,但会给浏览器和服务器带来性能的压力,需要权衡使用。
3)资源文件加载顺序
css放在页面最上面,js放在最下面。这样页面的体验才会比较好。
浏览器会加载完CSS才会对页面进行渲染。
JS只要加载后就会立刻执行(有些JS可能执行时间比较长)。
4)减少Cookie传输
cookie包含在每次的请求和响应中,因此哪些数据写入cookie需要慎重考虑(静态资源不需要放入cookie)
5)友好的提示(非技术手段)
有时候在前端给用户一个提示,就能收到良好的效果。毕竟用户需要的是不要不理他。
1.2、CDN加速
CDN,又称内容分发网络,本质是一个缓存,而且是将数据缓存在用户最近的地方。无法自行实现CDN的时候,可以根据经济实力考虑商用CDN服务。
1.3、反向代理缓存
将静态资源文件缓存在反向代理服务器上,一般是Nginx。
1.4、WEB组件分离
将js,css和图片文件放在不同的域名下。可以提高浏览器在下载web组件的并发数。因为浏览器在下载同一个域名的的数据存在并发数限制。
2、应用服务性能优化
2.1、缓存
网站性能优化第一定律:优先考虑使用缓存优化性能
优先原则:缓存离用户越近越好
2.2、缓存的基本原理和本质
缓存是将数据存在访问速度较高的介质中。可以减少数据访问的时间,同时避免重复计算。
2.3、合理使用缓存的准则
频繁修改的数据,尽量不要缓存,读写比2:1以上才有缓存的价值。
缓存一定是热点数据。
应用需要容忍一定时间的数据不一致。
缓存可用性问题,一般通过热备或者集群来解决。
2.3、分布式缓存与一致性哈希
以集群的方式提供缓存服务,有两种实现;
1)需要更新同步的分布式缓存,所有的服务器保存相同的缓存数据,带来的问题就是,缓存的数据量受限制,其次,数据要在所有的机器上同步,代价很大。
2)每台机器只缓存一部分数据,然后通过一定的算法选择缓存服务器。常见的余数hash算法存在当有服务器上下线的时候,大量缓存数据重建的问题。所以提出了一致性哈希算法。
一致性哈希:
- 首先求出服务器(节点)的哈希值,并将其配置到0~2的32次方的圆(continuum)上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台服务器上。
一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
数据倾斜:
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题,此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
3、集群
可以很好的将用户的请求分配到多个机器处理,对总体性能有很大的提升
3.1、异步
同步和异步,阻塞和非阻塞:
同步和异步关注的是结果消息的通信机制
同步:同步的意思就是调用方需要主动等待结果的返回
异步:异步的意思就是不需要主动等待结果的返回,而是通过其他手段比如,状态通知,回调函数等。
阻塞和非阻塞主要关注的是等待结果返回调用方的状态
阻塞:是指结果返回之前,当前线程被挂起,不做任何事
非阻塞:是指结果在返回之前,线程可以做一些其他事,不会被挂起。
1)同步阻塞:同步阻塞基本也是编程中最常见的模型,打个比方你去商店买衣服,你去了之后发现衣服卖完了,那你就在店里面一直等,期间不做任何事(包括看手机),等着商家进货,直到有货为止,这个效率很低,jdk里的BIO就属于 同步阻塞。
2)同步非阻塞:同步非阻塞在编程中可以抽象为一个轮询模式,你去了商店之后,发现衣服卖完了,这个时候不需要傻傻的等着,你可以去其他地方比如奶茶店,买杯水,但是你还是需要时不时的去商店问老板新衣服到了吗。jdk里的NIO就属于 同步非阻塞
3)异步阻塞:异步阻塞这个编程里面用的较少,有点类似你写了个线程池,submit然后马上future.get(),这样线程其实还是挂起的。有点像你去商店买衣服,这个时候发现衣服没有了,这个时候你就给老板留给电话,说衣服到了就给我打电话,然后你就守着这个电话,一直等着他响什么事也不做。这样感觉的确有点傻,所以这个模式用得比较少。
4)异步非阻塞:好比你去商店买衣服,衣服没了,你只需要给老板说这是我的电话,衣服到了就打。然后你就随心所欲的去玩,也不用操心衣服什么时候到,衣服一到,电话一响就可以去买衣服了。jdk里的AIO就属于异步。
3.2、常见异步的手段
- Servlet异步:servlet3中才有,支持的web容器在tomcat7和jetty8以后。
- 多线程
- 消息队列
4、程序级别
4.1、代码级别
一个应用的性能归根结底取决于代码是如何编写的。
选择合适的数据结构
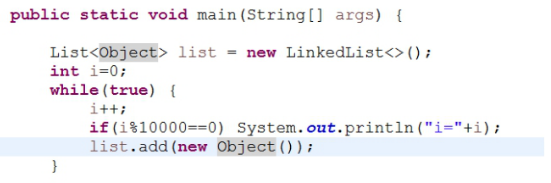
选择ArrayList和LinkedList对我们的程序性能影响很大,为什么?因为ArrayList内部是数组实现,存在着不停的扩容和数据复制。
4.2、选择更优的算法
举个例子,如何判断一个数是否为n的多少次方
[code]//如何判断一个数是否为2的多少次方
public static void main(String[] args) throws Exception{
int n =2;
Scanner scanner=new Scanner(System.in);
System.out.println("请输入需要计算的数:");
while(scanner.hasNext()){//控制台输入
int input =scanner.nextInt();
while (true){ //循环 求余数
if(input ==n){
System.out.println("是("+n+")的次方");
break;
}
if(input%n !=0){
System.out.println("不是("+n+")的次方");
break;
}else{
input = input/2;
}
}
if((input&(input-1)) ==0){
System.out.println("是("+n+")的次方");
}else{
System.out.println("不是("+n+")的次方");
}
}
}
4.3、编写更少的代码
同样正确的程序,小程序比大程序要快,这点无关乎编程语言。
4.4、并发编程
4.5、资源的复用
目的是减少开销很大的系统资源的创建和销毁,比如数据库连接,网络通信连接,线程资源等等。
- 单例模式
- 池化技术
三、存储性能优化
1、尽量使用SSD
2、定时清理数据或者按数据的性质分开存放
3、结果集处理
4、用setFetchSize控制jdbc每次从数据库中返回多少数据。
四、总结
调优是个很复杂、很细致的过程,要根据实际情况调整,不同的机器、不同的应用、不同的性能要求调优的手段都是不同的。也没有一个放之四海而皆准的配置或者公式。即使是jvm参数也是如此,再比如说性能有关的操作系统工具,和操作系统本身相关的所谓大页机制,都需要平时去积累,去观察,去实践。

- 《深入理解jvm》笔记---第六章
- 深入理解JVM笔记四-虚拟机性能监控与故障处理工具
- 【深入理解JVM】第10~13章 编译期优化、线程安全、锁优化 笔记
- 深入理解JVM笔记五-调优案例分析与实战
- 深入理解JVM笔记五-调优案例分析与实战
- 深入理解JVM虚拟机学习笔记(四)虚拟机性能监控和故障处理工具
- 深入理解计算机系统阅读笔记-优化程序性能
- 笔记:深入理解JVM 第四部分 程序编译及代码优化 (第10、11章)
- 深入理解JVM性能调优
- 笔记:深入理解JVM 第5章 调优案例分析与实战
- 深入理解JVM学习笔记——第十三章 线程安全与锁优化
- 深入理解JVM性能调优
- 5、深入理解计算机系统笔记:优化程序性能
- 笔记:Java 性能优化权威指南 第7章 JVM调优入门
- 深入理解JVM虚拟机 第二章笔记 Java内存区域与内存溢出异常
- 《深入理解jvm》笔记---第二章
- 【技术分享】开Oracle调优鹰眼,深入理解AWR性能报告
- 深入理解JVM虚拟机笔记五
- 深入理解JVM(4)——如何优化Java GC「译」
- MySql学习(七) —— 查询性能优化 深入理解MySql如何执行查询