python爬虫爬取
2019-06-02 23:42
477 查看
版权声明:菜鸟学习,请多多指教. https://blog.csdn.net/weixin_43784462/article/details/90745454
Python爬虫
针对python爬虫这块,最近写了有大大小小三个项目,遇到几个难点,下篇总结出来,这里先写下我总结的爬虫爬取步骤.
静态文件:
针对静态文件的爬取,列如图片之类的,一般网站都保存在CDN上,需要先从网页上获取图片地址就好了,需要注意下保存的格式,有可能会导致图片无法打开的问题(一般保存为png格式内容).
数据:
爬虫解决打就是数据源的问题,是数据处理,数据分析之类的先行问题.所以更多的还是需要爬取数据的更多一些.
针对网页显示数据的问题,有些是直接放在网页源代码中,有的是由请求返回的json格式中(前后端分离开发的),还有的是js加密来的(解密的话,可能需要掉些头发).针对各种数据渲染方式,我们可以采用不同的爬取方式.
1.对于在html代码中的数据
有的网站的数据是放在网页源代码中,我们只需要采用python的requests模拟访问请求就可以获取到响应.得到的响应就是完整的html网页代码,这是我们只需要使用解析器解析提取数据就可以了.以下是三种常见的解析方法.
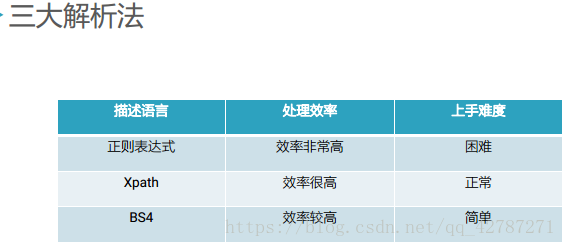
个人使用xpath较多,简单快捷.
以下四种解析器:
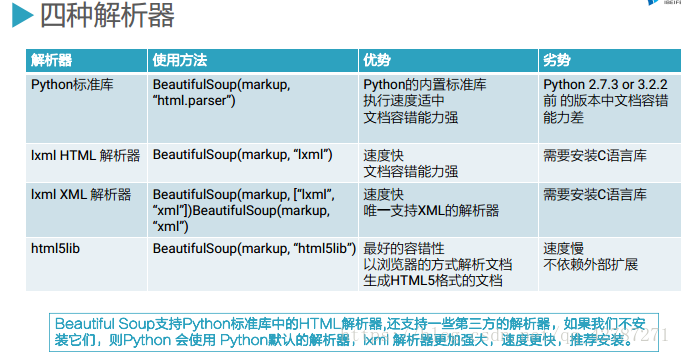
2.对于返回的json数据
现在很多网站是前后端分离开发(瀑布流网站,翻页之类的),我们可以采用抓包的方法,分析得到正确的请求地址和参数,然后模拟请求,得到json数据,再进行处理就好了.
3.js加密的数据
对于这类网站数据,可以破解其加密的方式来获取数据.但是不推荐,首先,破解很费时间,而且别人不定时更改加密方式,这样的话,不适用于长久爬取,你需要从新更改代码.相当麻烦.一般采用selenium模拟浏览器的行为完成数据采集,不过这样阻塞,代码执行效率低.
步骤:
- 一般遇到一个爬虫需求,我们可以先打开网站,查看下源代码,发现数据是否在源代码中,或者是某个请求的返回的json数据中.
- 在观察了网站后,我们可以获取到数据的请求地址,接下来我们可以先模拟一个requests请求,测试下是否有数据,或者是否有反爬措施.再进行针对反爬的响应措施(请求头,参数,ip代理之类的).
- 针对某些只能登陆后才能请求到的数据,那么我们需要先获取到cookie.这里可能会涉及到对验证码的处理,最近处理过苏宁,京东的滑块验证码和数字验证码,会在下一篇谈到
- 对于js加密的数据,可以简单分析下js加密的逻辑,如果太复杂,或是加密方式变化周期短,建议采用selenium,简单,粗暴,但是切记,不要一开始就使用selenium爬取,先测试下,不要动不动就上selenium
- 接下来,拿到数据就可以进行数据分析,pandas这个库可以很好满足大部分需求

相关文章推荐
- 爬虫入门:Python (问题集合)
- Python爬虫 爬取Google Play 100万个App的数据,并入库到数据库 scrapy框架
- 【Python3 爬虫】06_robots.txt查看网站爬取限制情况
- Python 轻量级爬虫
- python爬虫抓取链家租房数据
- 简单的Python爬虫抓数据
- python-网络爬虫初学四:cookie的存储与读取
- python与matlab爬虫百度图片首页的图片(urllib.request)
- Python 爬虫实践:浅谈数据分析岗位
- python实现简单爬虫抓取图片
- python实现网络爬虫
- 适合新手的Python爬虫小程序
- python爬虫淘宝比价
- 干货|18个Python爬虫实战案例(已开源)
- Python 爬虫:获取网页图片
- Python爬虫文件下载图文教程
- python爬虫——爬取知乎上自己关注的问题
- Java调用Python并传递参数(爬虫8)
- Python3图片爬虫
- Python 爬虫实战1.0