机器(深度学习)新手第一次在Kaggle上被虐的经历(经验)——泰坦尼克号生存预测:Titanic: Machine Learning from Disaster——(下)
两点废话
黑喂狗!这个下篇主要是进行,模型的改良,和更多的特征工程、如果你没有看过上篇,你可以点击在这里:
机器(深度学习)新手第一次在Kaggle上被虐的经历(经验)——泰坦尼克号生存预测:Titanic: Machine Learning from Disaster——(上)
温馨提示:按顺序看更可口哦!
一.划分交叉集
第一个模型已经建立了,但是有一个局限,就是kaggle上每天提交的次数是有限制的。所以我们现在就需要从从训练集里抽出一些数据来建立训练集。达叔的课程说过这方面的事情,我这里呢选择,拿出20%来进行交叉验证。
X_cross=X_train[712:891] X_train=X_train[0:712] Y_cross=Y_train[712:891] Y_train=Y_train[0:712] X_cross.shape,X_train.shape,Y_cross.shape,Y_train.shape
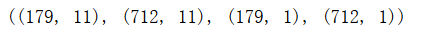
还是要确定维度,这个习惯特别的重要!
然后我们现在用新的训练集去进行训练模型:

正确率下降,正常,毕竟训练集少了20%,然后看下交叉集准确率:
#交叉集准确率
acc_cross = sess.run(accuracy,feed_dict={X: X_cross,Y: Y_cross})
acc_cross

这个挺意外啊,准确率居然那么高。
那就看看这个里面的预测错误的例子吧。
#所有预测的正确或错误列表
bed_case = sess.run(bed_case,feed_dict={X: X_cross,Y: Y_cross})
#找出交叉验证集的错误例子
bed=pd.DataFrame(columns=('PassengerId','Survived','Pclass','Name','Sex','Age','SibSp','Parch','Ticket','Fare','Cabin','Embarked'))
cross = pd.read_csv('train.csv') #读取文件
for i in range(0,len(bed_case),1):
if bed_case[i,0]==False:
bed=bed.append(cross[i:i+1])
bed
 emmm,截不了那么多图,看看结果 ,在看看交叉验证集的误差等等。。。我们可以开始达叔所说的机器学习循坏了 哈哈
emmm,截不了那么多图,看看结果 ,在看看交叉验证集的误差等等。。。我们可以开始达叔所说的机器学习循坏了 哈哈
二.偏差,方差分析。
如果给这个项目一个人的表现的话,应该是很低的,但是kaggle全部预测成功的比比皆是,所以就设为1就好,训练集的准确率为:67%,交叉集为:82%,很明显,有着高偏差,所以按着达叔教程的方法,1,搭建更深的模型。2.用其他优化方法,等等
所以咱们进行更深的模型的搭建。
三.更深的模型
为了搭建更深的模型,不止是要改变前向传播哪一点,在前面数据处理的时候也有要改变的地方。我改的不是很好,有点绕,能理解的尽量理解我各种转置的原因。下面只贴有修改的代码,其他没改动的就不在贴了:
X_cross=X_train[712:891].T
X_train=X_train[0:712].T
Y_cross=Y_train[712:891].T
Y_train=Y_train[0:712].T
X_cross.shape,X_train.shape,Y_cross.shape,Y_train.shape
#测试集的预处理
#data_test = pd.read_csv('test.csv')
data_test = data_test[['Pclass', 'Sex', 'Age', 'SibSp', 'Fare', 'Cabin', 'Embarked']]
#data_test['Age'] = data_test['Age'].fillna(data_test['Age'].mean())
data_test['Cabin'] = pd.factorize(data_test.Cabin)[0]#数值化
data_test.fillna(0,inplace = True)
data_test['Sex'] = [1 if x == 'male' else 0 for x in data_test.Sex]
data_test['p1'] = np.array(data_test['Pclass'] == 1).astype(np.int32)
data_test['p2'] = np.array(data_test['Pclass'] == 2).astype(np.int32)
data_test['p3'] = np.array(data_test['Pclass'] == 3).astype(np.int32)
data_test['e1'] = np.array(data_test['Embarked'] == 'S').astype(np.int32)
data_test['e2'] = np.array(data_test['Embarked'] == 'C').astype(np.int32)
data_test['e3'] = np.array(data_test['Embarked'] == 'Q').astype(np.int32)
del data_test['Pclass']
del data_test['Embarked']
X_test=data_test.T
#搭建网络
#创建占位符
X= tf.placeholder(dtype='float',shape=[11,None])
Y = tf.placeholder(dtype='float',shape=[None,1])
#前向传播过程
W1 = tf.Variable(tf.random_normal([16,11]))
B1 = tf.Variable(tf.random_normal([16,1]))
W2 = tf.Variable(tf.random_normal([16,16]))
B2 = tf.Variable(tf.random_normal([16,1]))
W3 = tf.Variable(tf.random_normal([16,16]))
B3 = tf.Variable(tf.random_normal([16,1]))
W4 = tf.Variable(tf.random_normal([1,16]))
B4 = tf.Variable(tf.random_normal([1,1]))
Z1 = tf.matmul(W1,X) + B1
A1 = tf.nn.relu(Z1)
Z2 = tf.matmul(W2,A1) + B2
A2 = tf.nn.relu(Z2)
Z3 = tf.matmul(W3,A1) + B3
A2 = tf.nn.relu(Z3)
Z4 = tf.matmul(W4,A2) + B4
pred = tf.cast(tf.sigmoid(Z4) > 0.5,tf.float32)#预测结果大于0.5值设为1,否则为0
logits=tf.transpose(Z4)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=Y,logits=logits))#交叉熵损失函数
train_step = tf.train.GradientDescentOptimizer(0.0003).minimize(loss)#梯度下降法训练
accuracy = tf.reduce_mean(tf.cast(tf.equal(pred,Y),tf.float32))
#开始训练
sess = tf.Session() #开启会话
sess.run(tf.global_variables_initializer())#初始化所有变量
loss_train = []
train_acc = []
for i in range(25000):
#index = np.random.permutation(len(data_target))#打乱数据顺序,防止过拟合
#data_train = data_train[index]
#data_target = data_target[index]
for n in range(len(Y_train.T)//100 + 1):
batch_xs = X_train.T[n*100:n*100+100]
batch_ys = Y_train.T[n*100:n*100+100]
sess.run(train_step,feed_dict={X: batch_xs.T,Y: batch_ys})
if i % 5000 ==0:
loss_temp = sess.run(loss,feed_dict={X: batch_xs.T,Y: batch_ys})
loss_train.append(loss_temp)
train_acc_temp = sess.run(accuracy,feed_dict={X: batch_xs.T,Y: batch_ys})
train_acc.append(train_acc_temp)
print(loss_temp,train_acc_temp)
结果可以自己去实验一下。但个人实验的,结果并不理想!!
四.进行特征工程!!
这一部分主要是给大家一些想法,让大家去可以选择自己去实现这些想法,然后这个过程中,有更多的想法,再去实现,等等,不断的去更新自己的正确率。
1.可以尝试,独立建立一个模型去预测年龄,然后填充。
2.可以尝试,把船舱号加进去,可以分为有船舱号,无船舱号。也可以分为船舱的区(船舱号前面的字母),船舱的房间号,和无船舱。
3.尝试将兄弟姐妹,和父母加起来,做成一个家人特征。
4.尝试把名字给加入进去。
。。。。
这些的代码我有,但是我就不那么整理好了,需要的我会放在我的GitHub里。自取~
五.模型融合
这可是竞赛的大杀器,有两种想法,一是将我们的若干模型的结果进行平均。二是将我们的数据去进行分组,分成几份去进行训练,分别用每种训练出来若干模型,分别预测测试集,再将几组结果进行平均,得出结果。这里也是说出想法。实现很简单,就利用切片就好。同样放在我的GitHub里。
六.结语
很高兴你能读到这里!非常希望这篇文章可以帮到你。这应该是我第一篇真正意义上的博客,希望我以后可以坚持下去,同样,在深度学习中也能坚持下去!同样的话,也送给正在努力的你们。
文章有些代码和想法来自
@快乐的佩奇
https://blog.csdn.net/qq_31805959/article/details/82944682
@寒小阳
https://blog.csdn.net/han_xiaoyang/article/details/49797143#t10
感谢你们!再次感谢你们读到这里!谢谢~~

- Kaggle比赛经验总结之Titanic: Machine Learning from Disaster
- 关于Kaggle-Titanic: Machine Learning from Disaster的机器学习报告(初稿)
- kaggle: Titanic: Machine Learning from Disaster 比赛
- Kaggle项目实战2—Titanic:Machine learning from disaster—排名Top20%
- 机器学习一小步:Kaggle上的练习Titanic: Machine Learning from Disaster(二)
- Titanic: Machine Learning from Disaster(Kaggle 数据挖掘竞赛)
- Kaggle:Titanic: Machine Learning from Disaster
- Kaggle | Titanic: Machine Learning from Disaster
- Kaggle之Titanic: Machine Learning from Disaster
- Kaggle Titanic: Machine Learning from Disaster
- Kaggle竞赛题目之——Titanic: Machine Learning from Disaster
- 【机器学习】Kaggle-Titanic:Machine Learning from Disaster
- kaggle Code : Titanic: Machine Learning from Disaster 分类
- kaggle: Titanic: Machine Learning from Disaster
- 【Kaggle练习赛】之Titanic: Machine Learning from Disaster
- Titanic: Machine Learning from Disaster
- Titanic: Machine Learning from Disaster
- kaggle competition 之 Titanic: Machine Learning from Disaster
- Titanic Machine Learning from Disaster
- kaggle竞赛——Titanic:Machine Learning from Disaster