目标检测YOLO系列论文对比
yolo相对于R_CNN系列论文,创新之处在于不再需要候选区域,直接端到端,利用回归的思想,直接回归出边框和类别,大大加快了速度,同时精度也挺高。。
YOLO v1
主要思想
1、将图片划分为s×s的网格,待检测的目标中心点位于哪个网格中,就由哪个网格来负责检测他,论文中每个网格设定了2个框,也就是让2个框来同时拟合一个目标框,所以当网格中存在目标时,那么该网格中的预测框的目标值即为这个目标框的值(对比R_CNN系列论文,他们都是通过预测框与目标框的IOU来设定预测框的目标值);
2、所有的预测框由网络直接传播获得,每个网格预测5个框,每个框用5个预测值来表示,分别(x,y,w,h)和得分, x和y代 表 区域的中心点对于cell左上角 的偏移量,w 和h代表区域相对于全图的宽和高,它们都介于0 - 1之间。得分反映了区域内包含 一 个目标的置信度和预测区域的精确度,得分的计算方法为:
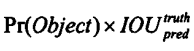
IOU表示预测框与真实框的交并比,如果网格中有目标,Pr就等于1,否则为0,
实际这个公式是为了求训练时得分的目标值,修正网络预测的得分值;
3、每个网格无论有多少个框,都值预测一个类别值(与yolo v2不同,v2中每个anchorbox预测一组类别值),所以正向传播预测结果为s×s×(5×2+20)
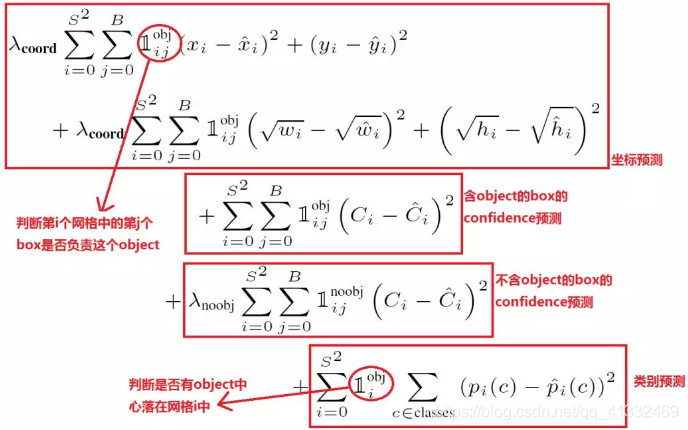
4、损失函数
注意:类别损失和坐标损失只计算有目标的网格中的预测框;
但是confidence损失有无目标都要计算。
训练过程
1、网络正向传播,得到s×s×2个预测框
2、计算预测框的目标值,然后计算损失函数,反向传播,更新参数
测试过程
1、网络正向传播,得到s×s×2个预测框
2、每个框的得分乘以所在网格的预测类别,取最大值,得到这个框的类别,并将这个值作为这个目标属于这一类的confidence
3、利用confidence和NMS过滤冗余边框,得到最终结果
YOLO v2
总体思路与一代相同,这里只说一下改进之处
1、联合训练算法
利用分类图像来学习分类,利用检测图像来学习定位
2、引入anchor box
相比较于一代yolo,一代yolo直接回归坐标,难度很大,引入anchor box,有了基准坐标,相对来说,预测难度降低;
但注意与faster R_CNN的区别,因为faster R_CNN是在feature map上,拿着anchor box进行滑动窗口的,实际就相当于一个框一个框的进行分类和回归,所以自然很容易检测到所有目标,但是yolo的类别和坐标都由回归产生,难度比faster-R-CNN要大:
(1)先验框的设置很重要。所以利用k-means来聚类,得到先验框的数量和大小(k=5),这样先验框更可靠
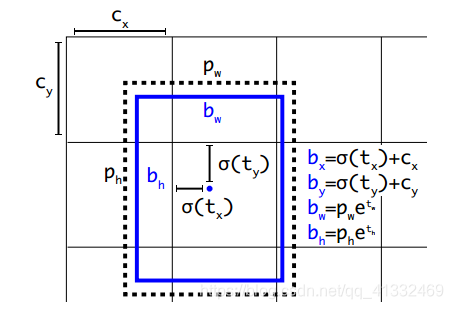
(2)直接预测相对于anchor box的偏移量,导致模型不稳定。所以不再预测偏移,而是预测相对于网格左上角的坐标
(3)如下,tx,ty,tw,th为网络预测值,所以在测试时,需要进一步计算获得预测边框,将相对于网格左上角坐标(tx,ty)转化为相对于图片左上角的坐标,宽度和高度需要依据anchor box的尺寸pw和ph来计算求得,具体公式如下,计算得到bx,by,bw,bh之后,在对他们进行过NMS。
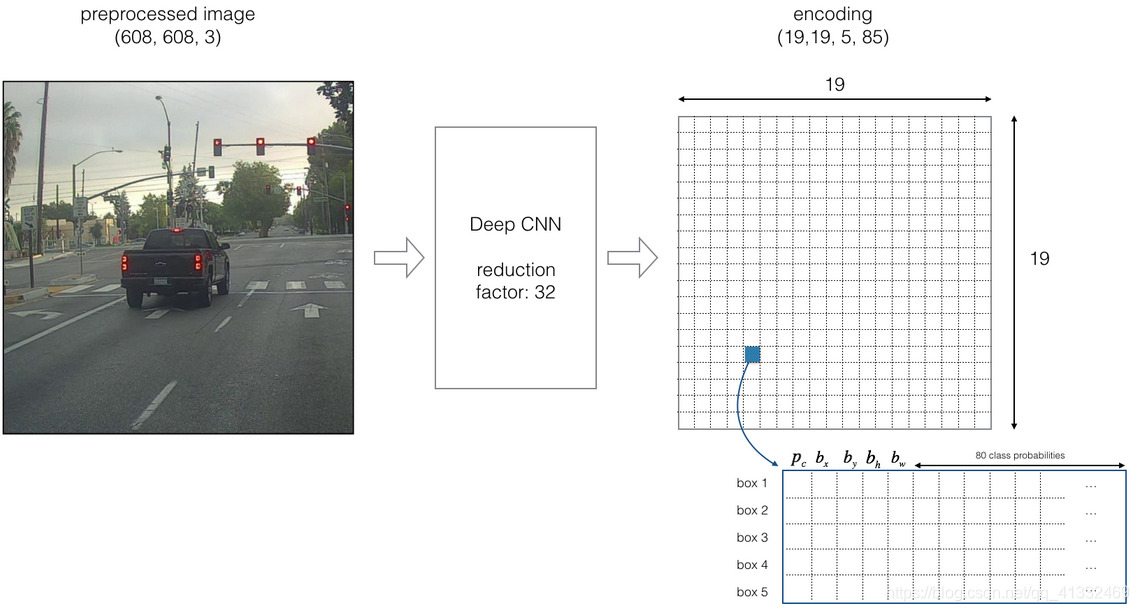
(3)引入anchor box之后,每一个anchor box都需要进行单独的类别预测(一代中每个cell只预测一个类别),例如数据集类别为80类,那么每个anchor box需要预测一个85维的向量,如果每个cell有5个anchor box,网格为19×19,网络预测输出为:
19×19×5×85.。。
YOLO v3
(1)多尺度预测
(2)用来更复杂的模型
相对于前两代改进不大,精确度提高了,但速度也慢了。。

- DL之Yolo系列:深度学习实现目标检测之Yolo系列的论文简介、概念理解、思路配图等详细攻略
- 【目标检测】[论文阅读][yolo] You Only Look Once: Unified, Real-Time Object Detection
- 深度学习目标检测(object detection)系列(八)YOLO2
- TensorFlow 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测论文精读(1)- YOLOv1
- 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测总结:YOLO系列(2)
- 目标检测系列学习笔记(RCNN系列+YOLO系列)
- 目标检测系列(六):YOLO v1
- 目标检测方法系列:R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 【深度学习:目标检测】深度学习检测方法梳理:R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列
- 目标检测系列(八):YOLO v2
- 目标检测系列(九):YOLO v3
- 论文 | YOLO(You Only Look Once)目标检测
- 目标检测方法系列:R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测之YOLO系列
- 目标检测总结:YOLO系列(1)
- (三论文)目标检测 - Tensorflow Object Detection API几种模型的对比
- 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- YOLO2:实时目标检测视频教程,视频演示, Android Demo ,开源教学项目,论文。