声学模型(一) hmm声学训练流程
概况
1. Word-hmm
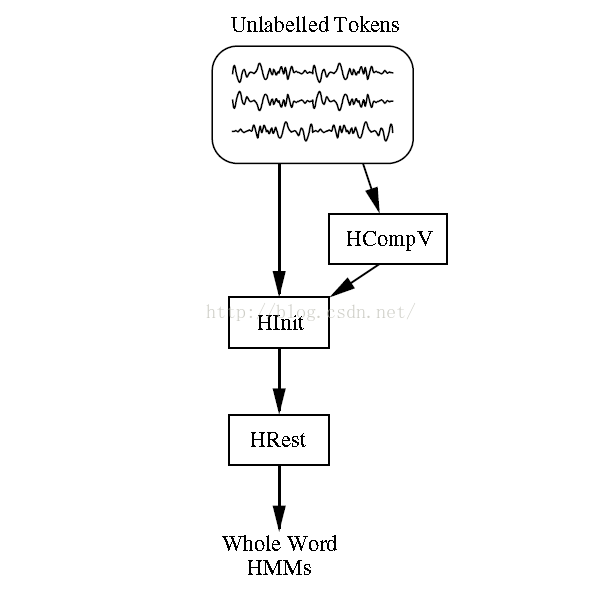
一个词对应一个hmm的情况,对应的训练数据如果删除了开始结尾的静音数据的话,无需标注既可以训练。常用训练流程:HInit->HRest对于训练数据较少而且需要较好的抗噪性,可以使用固定方差的模型。模型的方差可以使用HCompV进行估算,无需进行重估。
2. Sub-word hmm
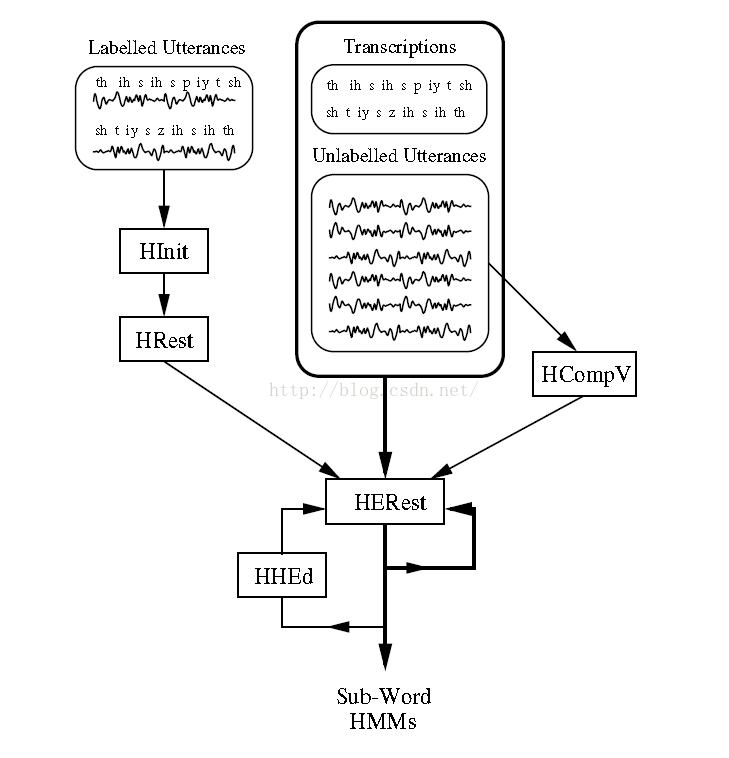
对于phone级别的hmm训练,需要额外引入HERest命令,根据训练数据的类型可以分为两类训练方式:
1. 对于labelled的训练数据HInit->HRest->HERest由于有分段音素级别的标注,可以使用word-hmm的初始化方式,使用HInit和HRest单独的初始化每一个单独的phone。2. 对于unlabelled的训练数据HCompv->HERest对于只有音素序列的标注,可以使用flat start的初始化方式,即HCompV将全局的均值方差初始化每一个phone的HMM,每一个训练语音都会被均分。
相关命令
HCompV:初始化高斯的均值和方差,使用训练语料的全局均值和方差
HInit:初始化高斯的均值和方差,使用viterbi估计
HRest:Baum-Welch重估高斯的均值和方差,isolated-unittraining
HERest:Baum-Welch重估高斯的均值和方差,embedded-unit training
HMMIRest:对HERest训练好的hmm进行区分度训练HInit和HRest用于训练word级别的hmm;HCompVHRestand HERest或者HInitHRest and HERest用于训练sub-word连续模型。
1. HInit
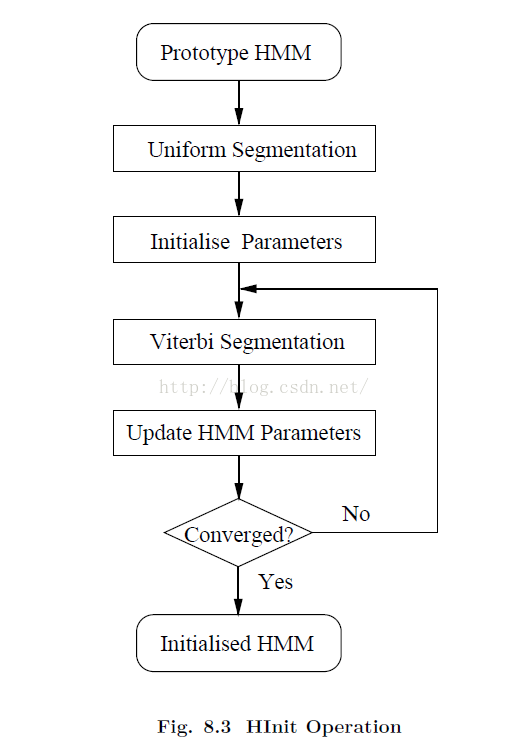
1. 初始化模型参数
对于每一条训练语音,按照标注平均分配对应的帧到hmm,由此可得到每个hmm对应的均值和方法以及对应的转移矩阵。
对于混合高斯:每一个特征vector对应于得分最高的的高斯模型,每个高斯模型对应的vector的个数作为该高斯模型的weight。Uniform segmentation的时候使用k-means算法将特征的vector归类到对应的state
2. Viterbi搜索迭代首先,使用viterbi算法找到每一条训练语句对应的状态序列,重估HMM的参数;使用viterbi对齐状态以后可以计算出训练数据的似然值,可以依次迭代运行下去,直到似然值不再增加。
2. HCompV
使用HInit初始化的的局限性在于需要提供labelled的训练数据。对于没有labelled的数据,HCompv可以使用全局的均值和方差来初始化hmm。所有的hmm的参数都一样,使用全局的模型参数。
3. HRest
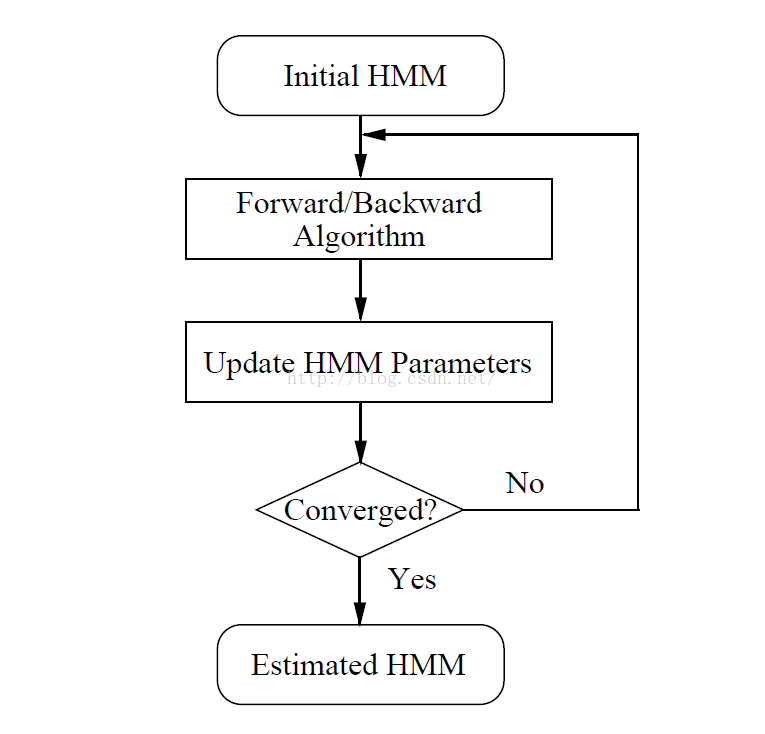
适用于对孤立单元的hmm进行重估,整体流程和HInit类似,不同之处在于:
1. 输入的HMM已经完成了初始化。
2. 使用前后向算法估算,而不是维特比。优势在于:
维特比搜索使用的是硬判决,每一帧严格对应于某一个state;前向后向算法使用的软判决,每一帧得出的是该帧对应于某一状态的概率。
4. HERest
用于embedded training,使用全集的训练数据同时更新所有的hmm。
首先将语音对应的标注进行hmm展开;然后利用前后向算法对参数进行更新。
一般需要2到5轮迭代
- 声学模型(一) hmm声学训练流程
- 声学模型GMM-HMM训练
- 【sphinx]声学模型训练流程学习
- 声学模型学习笔记(三) DNN-HMM hybrid system
- TensorFlow全流程样板代码:以ai challenger 场景分类和slim预训练模型为例
- 【sphinx】中文声学模型训练
- Kaldi 训练一个 DNN 声学模型
- 训练自已的中文语言模型与声学模型
- CMU sphinx训练命令控制声学模型问题
- 如何用 Kaldi 训练一个 DNN 声学模型
- [置顶] 深度学习模型训练流程
- 整理一波pytorch训练模型的流程
- 使用训练好的语言模型与声学模型
- Pocketsphinx语音识别--重新训练声学模型
- CMU sphinx学习(――训练自已的中文语言模型与声学模型)
- CNTK API文档翻译(23)——使用CTC标准训练声学模型
- 语音识别-声学模型(GMM-HMM)
- mhout in action : 13.4.1 阶段1(训练分类模型)的流程
- PocketSphinx语音识别系统----声学模型的训练与使用
- 从头开始编写基于隐含马尔可夫模型HMM的中文分词器之二 - 模型训练与使用