Detection of Malicious Code Variants Based on Deep Learning--论文
本人初看论文,由于小组要求,需要把对论文的理解写成博客(其实表面了解写不出深刻的多西,更多的也就是翻译的转化),难免会有许多不足(例如没有公式和公式的解说,抱歉,那些知识还未接触)。
Abstract–
由于目前的恶意代码识别方法检测精度差,检测速度慢。此论文提出了一种新的利用数据学习来改进恶意软件变体检测的方法。
在以往的研究中,深度学习在图像识别方面表现出了良好的性能,为了实现前面提出的检测方法,可将恶意代码转换为灰度图像,然后,1使用卷积神经网络(简写为CNN,是一种深度学习的算法)对图像进行识别和分类,该网络可以自动提取恶意软件图像的特征。此外,2还利用BAT算法(批量处理)来解决不同恶意软件家族之间的数据不平衡(样本比例失衡)问题。
INTRODUCTION –
作为安全保护的一个关键部分,“发现恶意代码变体”尤其重要,恶意软件检测方法主要包括两种方法:静态检测和动态检测。静态检测通过分解硬件代码并分析其执行逻辑来工作。动态检测通过在安全的虚拟环境或沙盒中执行代码来分析恶意代码的行为 。这两种检测方法都是基于特征的检测方法,首先提取恶意代码的文本或行为特征,然后通过分析这些提取的特征对恶意代码进行检测或分类。但这两种基于特征分析的方法经常被破坏。将恶意软件二进制文件转换为自压缩或唯一结构的二进制文件的模糊技术会阻碍静态特征分析的有效性。动态特征分析经常受到许多为产生不可靠结果而制定的对策的挑战。此外,由于执行环境不符合规则,动态分析可能会忽略某些类型的恶意代码。于是,提出了一种基于图像处理技术的新方法 “恶意软件可视化 ”,而不是专注于恶意软件分类的不可见功能。
这项工作将压缩二进制样本的结构转换为二维灰度图像。然后,将图像特征用于分类。
挑战:1.找到有效和自动提取功能的方法。2.建立一个通用的检测模型,可以处理大量的变体
恶意代码的特征(如静态特征和动态特征)的恶意检测方法。基于各种机器学习技术的更强大的检测方法还使用这些功能来发现恶意代码或其变体。但是,当检测恶意代码变体或未知恶意软件时,这些方法的效率会降低。恶意软件可视化方法可以处理代码模糊问题,但复杂的图像纹理特征提取(如gist和glcm)所需的时间成本较高。此外,这些特征提取方法在暴露于大数据集时也显示出低效率。所以,建立恶意软件检测模型的挑战在于“找到有效和自动提取功能的方法”。此外,数据不平衡问题还带来了另一个挑战。在每年生成的大量恶意软件中,很大一部分包括属于现有恶意代码系列或组的变体。通常,不同代码系列之间的恶意代码变体数量差异很大。所以挑战就是要建立一个通用的检测模型,可以处理大量的变体,使它可以在恶意软件家族中很好地工作。
Contributions–
1.介绍了一种将恶意软件二进制文件转换为图像的技术,从而将恶意软件检测转换为图像分类问题
2.提出了一种基于卷积神经网络(CNN)的恶意软件变异检测方法。
3.针对不同恶意软件家族之间的数据不平衡问题,设计了一种基于BAT算法的有效数据均衡方法。
相关调查和工作–
1.Malware Detection Based on Feature Analysis (基于特征分析的恶意软件检测)
如前所述,恶意软件检测的特征分析技术主要有两类:静态分析和动态分析。
在静态分析方面,通过对代码的分析,提出了几种方法。
例如,开发了一个使用内核行为分析的检测系统,该系统在检测未知应用程序的恶意行为方面表现良好。
但静态方法容易被模糊技术所欺骗。于是又提出了一种新的恶意软件检测算法,
该算法利用跟踪语义来描述恶意软件的行为(本人理解:语义是建立在图像特征上对图像属性的抽象描述,而模糊技术无法或很难改变图像根本的属性,故跟踪语义能有效描述图像特征)。
事实证明,这种方法可以有效地防止指令的混淆(例如,指令的重新排列、垃圾代码的插入和寄存器的重新分配)。然而,这种方法仅限于在指令级别上进行特征提取和分析。此外,模式匹配也很复杂。
动态分析基于对行为的评估(如访问私有数据和使用受限API调用)来监视和分析应用程序(应用程序)的运行时的特征。
根据这些信息,我们建立了一个行为模型来检测恶意代码。这些技术取得了改进的检测性能,但它们仍然受到为产生不可靠结果而制定的各种对策的挑战。
此外,由于计算开销很大,动态分析非常耗时,因此在暴露于大型数据集时效率较低。
2.Malicious Code Visualization (恶意代码可视化 )
yoo 等人使用自组织地图来可视化计算机病毒。
Trinius等人使用两种可视化技术 树图和线程图来检测和分类恶意软件
Goodalletal将不同恶意软件分析工具的结果聚合到一个可视环境中,而不是单个检测结果,从而增加了单个恶意软件工具检测覆盖的脆弱性。
上述研究主要集中于恶意软件行为的可视化,但软件源代码可能意味着更有意义的模式。
Nataraj等人[19]提出了一种新的基于二值纹理分析的恶意软件检测可视化方法。首先,他们将恶意软件可执行文件转换为灰度图像。然后,他们根据这些图像的纹理特征识别恶意软件。与动态分析方法相比,它们的方法产生了等效的结果。
Hen等人将恶意软件二进制信息转换为彩色图像矩阵,并使用图像处理方法对恶意软件族进行分类
3.Image Processing Techniques for Malware Detection (恶意软件检测的图像处理技术 )
Nataraj等人使用GIST(搜索树算法)提取恶意软件图像的特征。然而,GIST算法过于耗时。
Daniel等人开发了一种仿生并行实现,用于确定二进制二维图像中同系物群的代表性几何对象。
Miao等人提出了一种基于剪切算法和遗传算法的图像融合算法。但复杂图像纹理特征提取所需的时间成本高。
4 Malware Detection Based on Deep Learning (基于深度学习的恶意软件检测 )
yuan等人利用深度学习技术,设计并实现了一个在线恶意软件检测原型系统,名为Droid Sec。他们的模型通过学习从Android应用程序的静态分析和动态分析中提取的特征来获得高精度。
David等人提出了一种类似但更具说服力的方法,不需要恶意软件行为的类型。
他们的工作基于一个深度信任网络(DBN),用于自动生成恶意软件签名和分类。
基于CNN(卷积神经网络)的恶意软件检测 –
本节介绍了一种改进的基于CNN的恶意代码变异检测方法,包括:
1)将恶意代码映射为灰度图像;
2)CNN设计用于灰度图像检测。
下图概述了这两个过程:
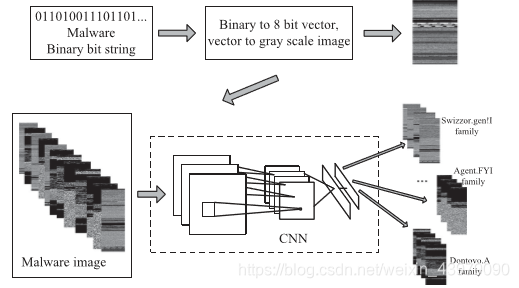
1.将二进制恶意软件转为灰色图像
一个恶意软件
3ff7
二进制位字符串可以拆分为多个子字符串,这些子字符串的长度为8位。这些子串中的每一个子串都可以看作一个像素,因为8位可以被解释为0-255范围内的无符号整数。
例如,如果位串为0110000010101100,则进程为0110000010101100→0110000010101100→96172。
二进制转换后,二进制恶意软件位串被转换成一个一维的十进制数字矢量。
根据指定的宽度,这个一维数组可以被视为具有一定宽度的二维矩阵。最后,恶意代码矩阵被解释为灰度图像。下图给出了基于经验观察的各种尺寸的推荐图像宽度:
!
在这里插入图片描述
图3显示了来自不同家庭的恶意软件图像示例[19]。
正如我们所看到的,同一恶意软件家族的图像在视觉上是相似的,它们与属于另一个家族的图像明显不同。
下图显示了称为agent.fyi家族的恶意软件代理的四个变体。每个成员的大小是不同的,但他们仍然有相似之处,因为新的恶意软件往往是由旧软件创建的。此外,当族相似时,图像可以清楚地显示它们的差异。

Malware Image Classification Based on CNN(基于CNN的恶意软件图像分类 )
本文中,开发了一个CNN来对恶意软件进行分类。用于灰度图像识别的CNN结构由几个部分组成,如下图:
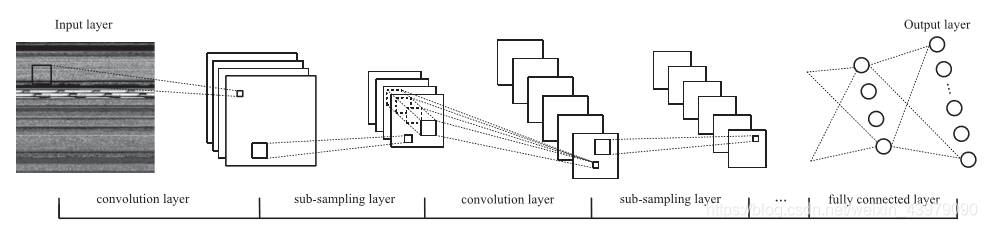
首先是输入层,将训练图像引入神经网络。接下来是卷积和次采样层。
前一层可以增强信号特性,降低噪声。后者可以减少数据处理量,同时保留有用的信息。然后,有几个完全连接的层,它们将二维特征转换为符合分类标准的一维特征。最后,分类识别并根据恶意软件图像的特点将其分类为不同的系列。
MALWARE IMAGE DATA EQUILIBRIUM (恶意软件图像数据均衡 )
适当的数据增强方法有效地避免了模型中的过拟合问题,提高了模型的鲁棒性。
图像的数据增强技术有很多种,例如旋转/反射、翻转、缩放、移位、缩放、对比度、噪声和颜色转换。图6显示了一些由恶意软件swizzor.gen!E家族的数据扩充生成的图像。显然,大多数新生成的图像保留了原始纹理特征。然而,一些图像由于不适当的转换(即过度旋转)而丢失了一些信息。在左下角查看的图像缺少swizzor.gen!E家族的纹理特征(底部的黑点)。

Data Equalization Based on a Bat Algorithm (基于BAT算法的数据均衡 )
在本文中,恶意软件图像数据非常不均匀,如图7所示。最大比例约为36:1
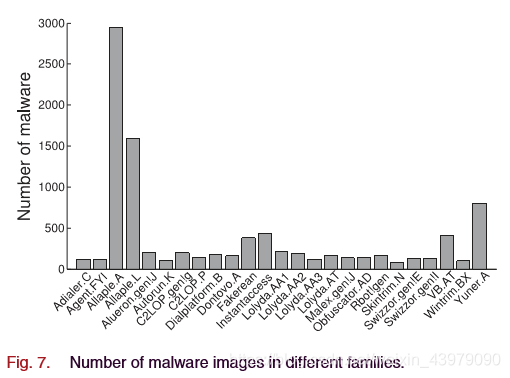
例如,Allaple.A 家庭有2949张照片,而skintrim.n家庭有80张。这种差异对CNN在图像分类方面的表现有很大影响。根据这两个族的数据训练的分类模型,当skintrim.n族中的所有样本都未被识别时,其精度可达到97%。但是,这不是一个合理的分类,因为它只能识别某些数据。
在分类中,重采样是一种处理不平衡训练集的简单方法。重采样方法通过处理训练集将不平衡数据集转换为平衡数据集。
它由两个实现组成:过采样和欠采样。过采样用于制作子集的多个副本。
欠采样用于从样本集中删除一些样本(即仅选择一些样本)。
例如,以Allaple.a族(2949张图像)和Skintrim.n族(80张图像)为例。
如果前者的训练集包含1000个样本,我们可以从中选择500个。
对于后者,由于数据不充分,我们必须重复采样,直到训练样本达到500。

- Automatic Feature Learning for Glaucoma Detection Based on Deep Learning论文理解
- 论文阅读笔记:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
- 论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
- 【论文阅读笔记】CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
- 【医学+深度论文:F11】2018 A deep learning model for the detection of both advanced and early glaucoma using
- MMSEG: A Word Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum M
- 论文Recent Trends in Deep Learning Based Natural Language Processing
- Transferred Deep Learning-Based Change Detection in Remote Sensing Images
- Deep Region and Multi-label Learning for Facial Action Unit Detection简要论文笔记
- CVPR 论文阅读与翻译2:图像检索、哈希编码学习、深度哈希:Deep Learning of Binary Hash Codes for Fast Image Retrieval-2015
- 【论文阅读笔记】Deep Learning based Recommender System: A Survey and New Perspectives
- We're on the cusp of deep learning for the masses. You can thank Google later
- 【医学+深度论文:F08】2018 Performance of Deep Learning Architectures and Transfer Learning for Detecting
- Jury Meeting Codeforces Round #433 (Div. 2, based on Olympiad of Metropolises)(贪心,预处理?)
- Face Detection using Deep Learning: An Improved Faster RCNN Approach论文解读
- Survey of single-target visual tracking methods based on online learning 翻译
- Deep Learning for Content-Based Image Retrival:A Comprehensive Study 论文笔记
- (论文笔记)Deep Learning Strong Parts for Pedestrian Detection
- 论文阅读(2)-Toward Real-Time Pedestrain Detection Based on a Deformable Template Model