Elasticsearch应用五:搜索详解(查询建议介绍、Suggester 介绍)
一、查询建议介绍
1. 查询建议是什么?
查询建议,为用户提供良好的使用体验。主要包括: 拼写检查; 自动建议查询词(自动补全)
拼写检查如图:
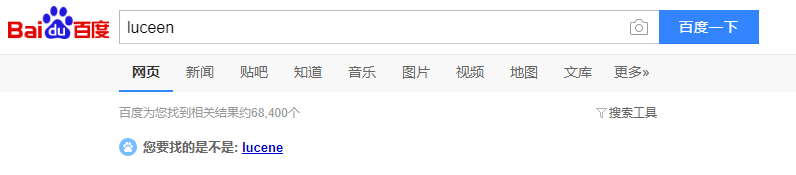
自动建议查询词(自动补全):
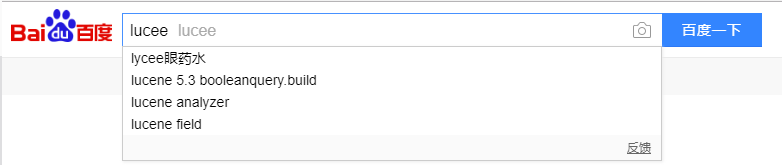
2. ES中查询建议的API
查询建议也是使用_search端点地址。在DSL中suggest节点来定义需要的建议查询
示例1:定义单个建议查询词
[code]POST twitter/_search
{
"query" : {
"match": {
"message": "tring out Elasticsearch"
}
},
"suggest" : { <!-- 定义建议查询 -->
"my-suggestion" : { <!-- 一个建议查询名 -->
"text" : "tring out Elasticsearch", <!-- 查询文本 -->
"term" : { <!-- 使用词项建议器 -->
"field" : "message" <!-- 指定在哪个字段上获取建议词 -->
}
}
}
}
示例2:定义多个建议查询词
[code]POST _search
{
"suggest": {
"my-suggest-1" : {
"text" : "tring out Elasticsearch",
"term" : {
"field" : "message"
}
},
"my-suggest-2" : {
"text" : "kmichy",
"term" : {
"field" : "user"
}
}
}
}
示例3:多个建议查询可以使用全局的查询文本
[code]POST _search
{
"suggest": {
"text" : "tring out Elasticsearch",
"my-suggest-1" : {
"term" : {
"field" : "message"
}
},
"my-suggest-2" : {
"term" : {
"field" : "user"
}
}
}
}
二、Suggester 介绍
1. Term suggester
term 词项建议器,对给入的文本进行分词,为每个词进行模糊查询提供词项建议。对于在索引中存在词默认不提供建议词,不存在的词则根据模糊查询结果进行排序后取一定数量的建议词。
常用的建议选项:
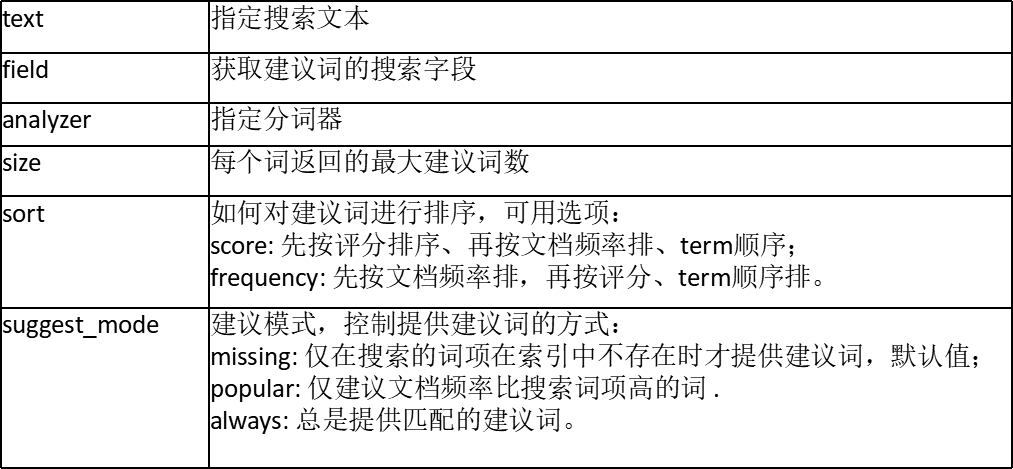
示例1:
[code]POST twitter/_search
{
"query" : {
"match": {
"message": "tring out Elasticsearch"
}
},
"suggest" : { <!-- 定义建议查询 -->
"my-suggestion" : { <!-- 一个建议查询名 -->
"text" : "tring out Elasticsearch", <!-- 查询文本 -->
"term" : { <!-- 使用词项建议器 -->
"field" : "message" <!-- 指定在哪个字段上获取建议词 -->
}
}
}
}
2. phrase suggester
phrase 短语建议,在term的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等
示例1:
[code]POST /ftq/_search
{
"query": {
"match_all": {}
},
"suggest" : {
"myss":{
"text": "java sprin boot",
"phrase": {
"field": "title"
}
}
}
}
结果1:
[code]{
"took": 177,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "2",
"_score": 1,
"_source": {
"title": "java spring boot",
"content": "lucene is writerd by java"
}
},
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
},
"suggest": {
"myss": [
{
"text": "java sprin boot",
"offset": 0,
"length": 15,
"options": [
{
"text": "java spring boot",
"score": 0.20745796
}
]
}
]
}
}
3. Completion suggester 自动补全
针对自动补全场景而设计的建议器。此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters-completion.html
为了使用自动补全,索引中用来提供补全建议的字段需特殊设计,字段类型为 completion。
[code]PUT music
{
"mappings": {
"_doc" : {
"properties" : {
"suggest" : { <!-- 用于自动补全的字段 -->
"type" : "completion"
},
"title" : {
"type": "keyword"
}
}
}
}
}
Input 指定输入词 Weight 指定排序值(可选)
[code]PUT music/_doc/1?refresh
{
"suggest" : {
"input": [ "Nevermind", "Nirvana" ],
"weight" : 34
}
}
指定不同的排序值:
[code]PUT music/_doc/1?refresh
{
"suggest" : [
{
"input": "Nevermind",
"weight" : 10
},
{
"input": "Nirvana",
"weight" : 3
}
]}
放入一条重复数据
[code]PUT music/_doc/2?refresh
{
"suggest" : {
"input": [ "Nevermind", "Nirvana" ],
"weight" : 20
}
}
示例1:查询建议根据前缀查询:
[code]POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nir",
"completion" : {
"field" : "suggest"
}
}
}
}
结果1:
[code]{
"took": 25,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"song-suggest": [
{
"text": "nir",
"offset": 0,
"length": 3,
"options": [
{
"text": "Nirvana",
"_index": "music",
"_type": "_doc",
"_id": "2",
"_score": 20,
"_source": {
"suggest": {
"input": [
"Nevermind",
"Nirvana"
],
"weight": 20
20000
}
}
},
{
"text": "Nirvana",
"_index": "music",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"suggest": [
"Nevermind",
"Nirvana"
]
}
}
]
}
]
}
}
示例2:对建议查询结果去重
[code]POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nir",
"completion" : {
"field" : "suggest",
"skip_duplicates": true
}
} }}
结果2:
[code]{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"song-suggest": [
{
"text": "nir",
"offset": 0,
"length": 3,
"options": [
{
"text": "Nirvana",
"_index": "music",
"_type": "_doc",
"_id": "2",
"_score": 20,
"_source": {
"suggest": {
"input": [
"Nevermind",
"Nirvana"
],
"weight": 20
}
}
}
]
}
]
}
}
示例3:查询建议文档存储短语
[code]PUT music/_doc/3?refresh
{
"suggest" : {
"input": [ "lucene solr", "lucene so cool","lucene elasticsearch" ],
"weight" : 20
}
}
PUT music/_doc/4?refresh
{
"suggest" : {
"input": ["lucene solr cool","lucene elasticsearch" ],
"weight" : 10
}
}
查询3:
[code]POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "lucene s",
"completion" : {
"field" : "suggest" ,
"skip_duplicates": true
}
}
}
}
结果3:
[code]{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"song-suggest": [
{
"text": "lucene s",
"offset": 0,
"length": 8,
"options": [
{
"text": "lucene so cool",
"_index": "music",
"_type": "_doc",
"_id": "3",
"_score": 20,
"_source": {
"suggest": {
"input": [
"lucene solr",
"lucene so cool",
"lucene elasticsearch"
],
"weight": 20
}
}
},
{
"text": "lucene solr cool",
"_index": "music",
"_type": "_doc",
"_id": "4",
"_score": 10,
"_source": {
"suggest": {
"input": [
"lucene solr cool",
"lucene elasticsearch"
],
"weight": 10
}
}
}
]
}
]
}
}

- elasticsearch系列五:搜索详解(查询建议介绍、Suggester 介绍)
- Solr系列六:solr搜索详解优化查询结果(分面搜索、搜索结果高亮、查询建议、折叠展开结果、结果分组、其他搜索特性介绍)
- 企业级搜索应用服务器Solr4.10.4部署开发详解(2)- Solr使用-创建集合表、存储、查询
- Solr系列五:solr搜索详解(solr搜索流程介绍、查询语法及解析器详解)
- [Elasticsearch] 全文搜索 (二) - 多词查询及查询的合并
- Linux rpm 命令参数使用详解[介绍和应用]
- [Elasticsearch] 多字段搜索 (五) - 以字段为中心的查询
- 企业级搜索elasticsearch应用03-前置处理器
- Linux rpm 命令参数使用详解[介绍和应用]
- JQGRID格式化/合并单元格/滚动条问题和多重子表介绍及datepicker参数使用详解(jqgrid表格中应用)
- [Elasticsearch] 全文搜索 (三) - match查询和bool查询的关系,提升查询子句
- elasticsearch(三) 之 elasticsearch目录介绍和配置文件详解
- 分布式搜索elasticsearch配置文件详解
- WMI技术介绍和应用——查询正在运行的进程信息
- [Elasticsearch] 多字段搜索 (一) - 多个及单个查询字符串
- elasticsearch的rest搜索--- 查询
- Linux rpm 命令参数使用详解[介绍和应用]
- ui-grid应用(调整了表格行高)+指定列模糊查询+联动搜索
- WMI技术介绍和应用——查询本地用户和组
- 企业级搜索应用服务器Solr4.10.4部署开发详解(3)- Solr使用-使用java客户端solrj进行增删改查开发