部署hadoop-2.6.0-cdh5.7.0 HA
2019-04-07 15:50
204 查看
集群运行服务规划

环境准备
准备三台虚拟机
192.168.247.210 hadoop001
192.168.247.220 hadoop002
192.168.247.230 hadoop003
并创建hadoop用户
su - hadoop mkdir app 将以下三个安装包上传到app目录 hadoop-2.6.0-cdh5.7.0.tar.gz jdk-8u45-linux-x64.gz zookeeper-3.4.6.tar.gz
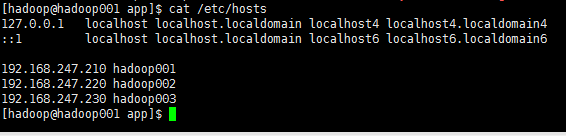
1、配置hosts文件
三台机器分别配置hosts文件
2、配置三台ssh信任关系
1)、在三台机器分别执行以下命令:
ssh-keygen -t rsa
执行该命令后连摁三下回车
2)、拷贝公钥到同一台机器,三台机器执行
ssh-copy-id node01.hadoop.com
3)、复制第一台机器的认证到其他机器
scp /home/hadoop/.ssh/authorized_keys hadoop002:/home/hadoop/.ssh
scp /home/hadoop/.ssh/authorized_keys hadoop003:/home/hadoop/.ssh
3、配置jdk
mkdir -p /usr/java/ tar -zxvf /home/hadoop/app/jdk-8u45-linux-x64.gz -C /usr/java
4、关闭防火墙
iptables off
iptables -L 查看防火墙规则
-F 清空
部署zookeeper
1、三台解压zookeeper*
2、创建软连接
ln -s /home/hadoop/app/zookeeper-3.4.6 /home/hadoop/app/zookeeper
3、配置dataDir(文件存储目录)
vi /home/hadoop/app/zookeeper/conf/zoo.cfg

4、配置ID号
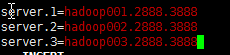
5、将配置文件发送到其他两台机器
scp conf/zoo.cfg hadoop002:/home/hadoop/app/zookeeper/conf/zoo.cfg scp conf/zoo.cfg hadoop003:/home/hadoop/app/zookeeper/conf/zoo.cfg
6、每台机器配置myid文件
echo 1 >/home/hadoop/app/zookeeper/data/myid ##hadoop001 echo 2 >/home/hadoop/app/zookeeper/data/myid ## hadoop002 echo 3 >/home/hadoop/app/zookeeper/data/myid ## hadoop003
7、zkServer.sh start
配置环境变量
vi ~/.bash_profile

配置hdfs&yarn HA
1、解压hadoop并创建软连接
ln -s /home/hadoop/app/hadoop-2.6.0-cdh5.7.0 /home/hadoop/app/hadoop
2、修改配置文件
配置文件较长:这里就不贴出来了。
hdfs-dfs.xml
core-site.xml
mapred-site.xml
yarn-site.xml
slaves
3、建目录
## namenode 存放name table(fsimage)本地目录 mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/name ## 临时目录 mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/tmp ## datanode存放 block块本地目录 mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/data ##JournalNode存放数据地址 mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/jn
4、修改hadoop-env.sh

5、启动jn
hadoop-daemon.sh start journalnode
6、格式化namenode
hadoop namenode -format
7、同步 NameNode 元数据
scp -r /home/hadoop/app/hadoop/data hadoop002:/home/hadoop/app/hadoop
8、初始化ZKFC
hdfs zkfc -formatZK
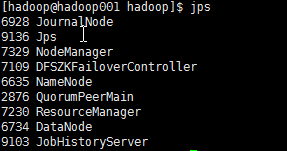
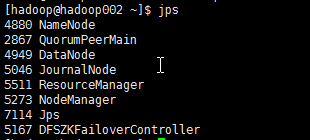
启动集群
start-dfs.sh start-yarn.sh 备用机启动RM: yarn-daemon.sh start resourcemanager 启动jobhistory: mr-jobhistory-daemon.sh start historyserver

相关文章推荐
- hadoop-2.6.0+zookeeper-3.4.6+hbase-1.0.0+hive-1.1.0完全分布式集群HA部署
- Hadoop 2.6.0(HA)部署启动
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置
- Hadoop大数据框架研究(3)——Spark的HA高可用性集群环境部署
- 【4】搭建HA高可用hadoop-2.3(部署配置HBase)
- hadoop HA部署(NFS方案)
- 源码编译Spark,Hadoop 2.6.0-cdh5.7.0 版本
- 【Hadoop】Hadoop HA 部署 详细过程(架构、机器规划、配置文件、部署步骤)
- Hadoop2.6.0自动化部署脚本(一)
- 大数据Hadoop的HA高可用架构集群部署
- HBase+ZooKeeper+Hadoop2.6.0的ResourceManager HA集群高可用配置
- 我的Hadoop安装——使用Cloudera部署,管理Hadoop集群(离线安装CDH5.7.0)
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
- 搭建hadoop2.6.0 HA及YARN HA
- Win7 64bit hadoop-2.6.0源码编译部署包
- hadoop2.6.0汇总:新增功能最新编译 32位、64位安装、源码包、API下载及部署文档
- 64位Linux上部署hadoop2.6.0的HDFS
- hadoopHA部署
- Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
- 编译hadoop2.6.0-cdh5.7.0 native支持snappy & 编译中遇到的坑及解决办法