Python几行代码,简单爬取豆瓣出版社信息,并保存输出txt文件
2019-04-02 11:28
489 查看
Python简单爬取豆瓣出版社信息,并打印输出TXT文件
之前自己跟着崔大神教程学习,都是从一些基础插件的安装,再到安装是否成功,及其测试使用,有点枯燥,现在换了其他教程学习,边实战边学习,每节课不长,还算可以。
如图所示:
1.Python 脚本
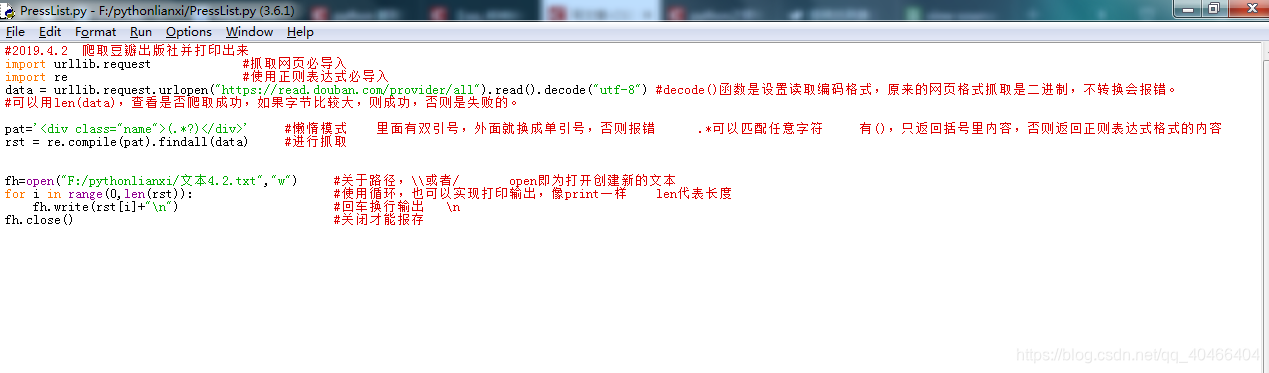

2.结果图

3.以下代码是自己用Python直接编写,脚本运行的实例
豆瓣出版社:https://read.douban.com/provider/all
#2019.4.2 爬取豆瓣出版社并打印出来
import urllib.request #抓取网页必导入
import re #使用正则表达式必导入
data = urllib.request.urlopen("https://read.douban.com/provider/all").read().decode("utf-8") #decode()函数是设置读取编码格式,原来的网页格式抓取是二进制,不转换会报错。
#可以用len(data),查看是否爬取成功,如果字节比较大,则成功,否则是失败的。
pat='<div class="name">(.*?)</div>' #懒惰模式 里面有双引号,外面就换成单引号,否则报错 .*可以匹配任意字符 有(),只返回括号里内容,否则返回正则表达式格式的内容
rst = re.compile(pat).findall(data) #进行抓取
fh=open("F:/pythonlianxi/文本4.2.txt","w") #关于路径,\\或者/ open即为打开创建新的文本
for i in range(0,len(rst)): #使用循环,也可以实现打印输出,像print一样 len代表长度
fh.write(rst[i]+"\n") #回车换行输出 \n
fh.close() #关闭才能报存

相关文章推荐
- Python实现读取txt文件并画三维图简单代码示例
- Python实现读取目录所有文件的文件名并保存到txt文件代码
- Python实现读取目录所有文件的文件名并保存到txt文件代码
- Python实现读取目录所有文件的文件名并保存到txt文件代码
- Python实现读取目录所有文件的文件名并保存到txt文件代码
- 用Python将gml文件中边的信息输出为csv(或者txt)格式
- Python实现读取目录所有文件的文件名并保存到txt文件代码
- python筛选特定文件的信息按照格式输出到txt
- 【python】读取指定文件夹下的所有图片路径,并保存到列表再输出到txt文件中
- 几行Python代码生成饭店营业额模拟数据并保存为CSV文件
- .Net写txt文件-简单的记录执行日志信息代码
- python 将print输出的内容保存到txt文件中
- 简单打开和保存txt文件
- Python读取多个txt文件并进行保存
- 简单几行代码就可以解析PE文件
- python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码
- 【转载】matlab中将数据输出保存为txt格式文件的方法
- python读取读取配置文件信息操作代码
- Linux系统应用程序输出结果保存成txt文件
- 调用DOS实现窗口隐藏并且把DOS控制台下输出信息写入文件中保存 笔记.