爬虫Scrapy框架学习(五)-东莞阳光热线问政平台爬取案例
2019-03-31 20:39
513 查看
本案例通过典型的scrapy框架Spider类展现了一个模板式的爬虫过程,请读者细细体会,此案例为必会项目,按照本博客配置,完美通过.本文还对item做了限制,编写item文件的主要作用是防止爬取数据存入子字典中的键值命名错误.
1.项目框架展示

2.爬取页面展示

3.yg.py文件
# -*- coding: utf-8 -*-
import scrapy
from yangguang.items import YangguangItem
class YgSpider(scrapy.Spider):
name = 'yg'
allowed_domains = ['sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
def parse(self, response):
#分组
tr_list = response.xpath("//div[@class='greyframe']/table[2]/tr/td/table/tr")
for tr in tr_list:
item = YangguangItem() #实例化爬取的数据限制(防止命名错误)
item["title"] = tr.xpath("./td[2]/a[@class='news14']/@title").extract_first()
item["href"] = tr.xpath("./td[2]/a[@class='news14']/@href").extract_first()
item["publish_date"] = tr.xpath("./td[last()]/text()").extract_first()
#进去详情页
yield scrapy.Request(
item["href"],
callback = self.parse_detail,
meta = {"item":item},
)
#翻页
next_url = response.xpath("//a[text() = '>']/@href").extract_first()
if next_url is not None:#判断是否有下一页
yield scrapy.Request(
next_url,
callback = self.parse
)
def parse_detail(self, response):
"""处理详情页"""
item = response.meta["item"]
item["content"] = response.xpath("//td[@class = 'txt16_3']//text()").extract_first() #选取多个选项
item["content_img"] = response.xpath("//div[@class = 'c1 text14_2']//img/@src").extract()
item["content_img"] = ["http://wz.sun0769.com/" + i for i in item["content_img"]] #列表推导式添加图片前面缺失的域名
# print(item)
yield item #输出到pipeline
4.item.py文件
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class YangguangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() href = scrapy.Field() publish_date = scrapy.Field() content_img = scrapy.Field() content = scrapy.Field()
5.pipeline.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to th
20000
e ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import re
class YangguangPipeline(object):
def open_spider(self, response): #在爬虫开始时打开一次和关闭时打开一次,而且只执行一次
pass
def close_spider(self, response):#但是如果在结束中统一保存文件,如果在程序中间出错了就不会保存已经爬取的数据了。
pass
def process_item(self, item, spider):
item["content"] = self.process_content(item["content"])
print(item)
return item
def process_content(self, content):#处理content内容,去除无关信息
# contnet = [re.sub(r"\xa0|\s","",i) for i in content] #content为列表的情况
# contnet = re.sub(r"\xa0","",content)
# content = [i for i in content if len(i) > 0]#去除列表中的空字符串
# print(content)
content = re.sub("\xa0", "", content)#content为字符串
return content
6.settings.py文件
# -*- coding: utf-8 -*-
# Scrapy settings for yangguang project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'yangguang'
SPIDER_MODULES = ['yangguang.spiders'] #爬虫位置
NEWSPIDER_MODULE = 'yangguang.spiders' #新建爬虫的放置位置
LOG_LEVEL = "WARNING"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True #默认情况下是否遵守robot协议
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 #设置最大并发请求(默认是16个)
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3 #下载延迟(使整个爬虫慢一些,防止反爬虫)
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16 #每一个域名的最大并发请求数(几乎不会用到)
#CONCURRENT_REQUESTS_PER_IP = 16 #每一个id的最大并发请求数(几乎不会用到)
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False #cookie是否开启(默认是开启的)
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers: #默认请求头
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = { #爬虫中间件
# 'yangguang.middlewares.YangguangSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = { #下载中间件
# 'yangguang.middlewares.YangguangDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'yangguang.pipelines.YangguangPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default) #自动限速(一般不需要)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default) #http缓存
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
7.结果展示
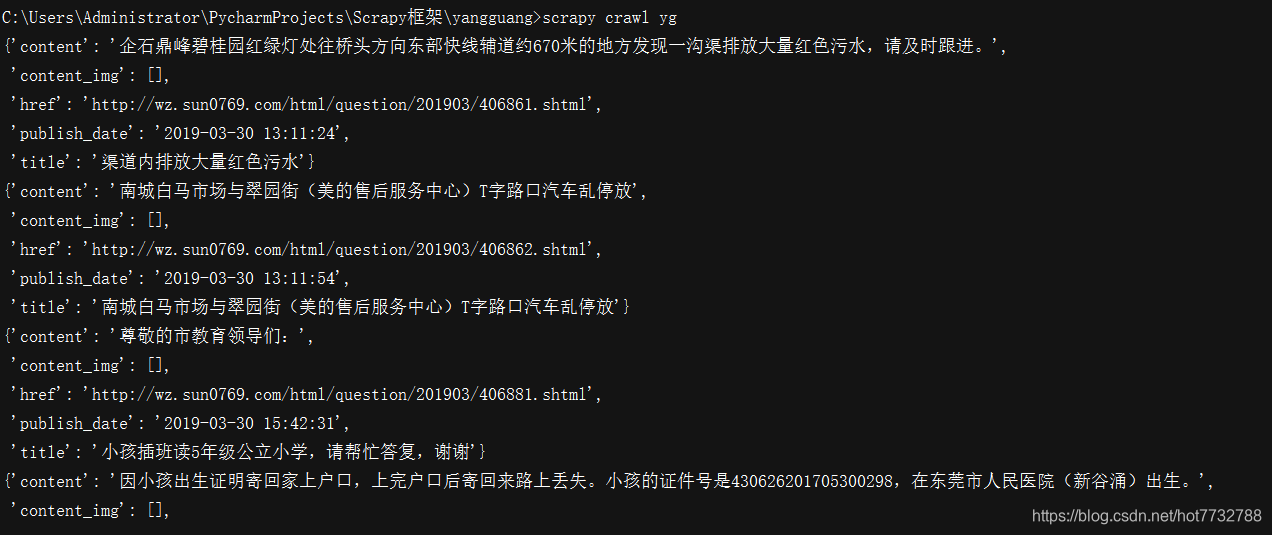
- content_img为空是因为在详情页并没有配图,有配图便可以爬取到,请读者自行查看网页源代码进行核验。

相关文章推荐
- scrapy爬虫框架实现简单案例:爬取阳光平台内容
- Scrapy框架学习(三)----基于Scrapy框架实现的简单爬虫案例
- 爬虫 scrapy 框架学习 2. Scrapy框架业务逻辑的理解 + 爬虫案例 下载指定网站所有图片
- 爬虫 scrapy 框架学习 1. Scrapy框架业务逻辑的理解 + 简单爬虫案例示范
- Python的爬虫程序编写框架Scrapy入门学习教程
- 爬虫框架--Scrapy学习笔记一
- python爬虫 scrapy框架学习
- 爬虫框架Scrapy学习记录II--Selector学习
- Python 3网络爬虫开发实战+精通Python爬虫框架Scrapy学习资料
- Python网络爬虫框架scrapy的学习
- 爬虫学习之scrapy框架入门
- Python爬虫框架Scrapy学习三记—让虫子爬
- Scrapy框架的学习(5.scarpy实现翻页爬虫,以及scrapy.Request的相关参数介绍)
- Python爬虫框架Scrapy 学习笔记 7------- scrapy.Item源码剖析
- python 爬虫 学习笔记(一)Scrapy框架入门
- Python爬虫框架Scrapy 学习笔记 4 ------- 第二个Scrapy项目
- 【Python学习系列五】Python网络爬虫框架Scrapy环境搭建
- 基于scrapy框架爬虫学习小结
- Python爬虫框架Scrapy 学习笔记 8----Spider
- 爬虫Scrapy框架学习(七)-传统scrapy框架模拟登陆实现(精品)