存储系统“数据之眼”的设计--数据探查服务
文章目录
前言
在大规模量级的分布式存储系统中,很多时候管理员以及用户都有特定条件的查询需求:比如用户哪个目录文件数据量是最多的?还有对于管理员的需求:哪个节点上存储的文件数量最多,又或者是否存在损坏数据块文件类似种种的问题。因此在大型分布式存储系统中,我们需要有一个能够快速透视,探查里面数据的工具。当然它的功能要远远大于目前文件系统提供的fsck这样的工具命令。对于这种工具,我们可以怎样对其进行设计呢?本文,笔者结合Hadoop Ozone Recon服务,来聊聊里面的一些相关设计思想。
数据探查服务的初始点:元数据的同步
这里需要大家明白一个关键的点,数据探查服务并不是要针对所有的物理数据进行一个个的扫描统计,而只是需要对中心控制节点的核心元数据进行探查分析即可。比如HDFS,那我们专门分析的对象就是FSImage文件。
为了避免对实际生产系统造成影响,我们一般的做法是会从一个Standby的元数据文件进行定期同步,然后对这个同步而来的文件再进行二次分析。当然,有时我们可以做的更高级一些,只有首次同步时进行元数据文件的同步,后面只同步WAL的更新操作,相当于这是Standby的Follower。因为数据探查服务不会对元数据文件进行写操作,所以我们可以让这个文件变为read-only模式的。
对于数据探查的定位,在这里它是一个服务,所以上述的行为应该被纳入到这个服务当中。
数据探查服务的分析:索引结构的重新构建
有时候,针对不同的查询分析需求,如果按照原来元数据文件内的索引构建方式,会导致非常低的效率(比如遍历完全统计),此时我们可以在服务中进行一定结构的转换。比如一种常见的方式:倒排索引的构建,或者带上前缀匹配的支持。或者构建出不同Key对应的不同Value的含义,只要Value是我们所需要的就行。
这里的索引结构的重构建可以和上面元数据的定期同步行为的速率保持一致,以达到准实时更新的效果。
数据探查服务的结果:汇聚表DB的存储
上述各个索引结构都构建完成后,我们可以做一些常规的汇总统计的操作,然后将这些结果存储到一张汇聚表中。然后用户可以通过这张汇聚表的数据来进行他们希望的查询请求。
比如举个例子,我们存储了一张Container–>Blocks数的表数据,定义如下:
CREATE TABLE `num_blocks_per_container` ( `container_id` BIGINT, `num_blocks` INT, PRIMARY KEY (`container_id`) );
和上述的步骤类似,这里的汇聚结果表也是需要被定期更新的,这样的话,用户就能够查询到近实时的结果。
数据探查服务的额外功能:节点级别的统计
数据探查服务不仅支持细粒度层面的元数据分析,当然它也应该包含节点层面的统计,诸如以下类似指标:
- 节点磁盘使用空间
- 节点总blocks数量
- …
这些节点层面的统计需要由数据探查服务定期对这些节点做一次查询操作,然后也将结果保存到上面的汇聚表中。这类结果数据对于系统管理员来说将会相当有用,比如说利用这些数据我们可以知道节点使用空间的趋势变化情况等等。
数据探查服务的外部展现:用户控制台
数据探查服务作为一项完整的数据分析服务,它不应该直接暴露给使用者。对于使用者来说,我们需要给他们提供一个Console的东西,用户看到的可以是直接提供好的用户命令,不同身份的用户能够使用的执行命令也是有所区分的。而Console里面的Console Server是数据探查服务的一个代理。
在这个Console Server的服务里,我们可以进一步完善Security的功能,加入一些authentication,或者更方便用户进行查询使用的一些Feature,比如浏览器直接浏览查询功能。
以上所有的设计参考自Hadoop Ozone Recon服务的设计,此服务的设计结构图如下,大家可以参考上面描述的进行比较。
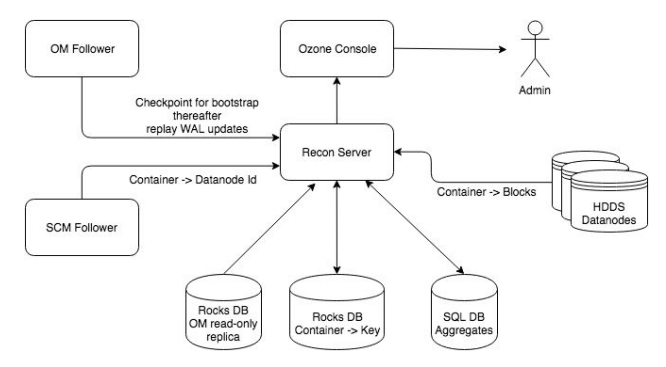
引用
[1].https://issues.apache.org/jira/browse/HDDS-1084. Ozone Recon Service

- 数据结构课程设计-通讯录管理系统c++版(顺序表存储,折半查找,递增排序)
- 面向数据可靠性存储系统设计思想探讨
- 分布式爬虫系统设计、实现与实战:爬取京东、苏宁易购全网手机商品数据+MySQL、HBase存储
- 面向数据可靠性存储系统设计思想探讨
- BigTable是Google设计的分布式数据存储系统
- 业务系统设计要考虑的问题(一)分散式数据存储设计
- 基于SST25VF020的数据存储系统设计
- 数据结构课程设计之银行活期存储系统(设计报告)
- 微服务架构下的监控系统设计(一)——指标数据的采集展示
- 一种NVMe SSD友好的数据存储系统设计 推荐
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 一种NVMe SSD友好的数据存储系统设计
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 分布式爬虫系统设计、实现与实战:爬取京东、苏宁易购全网手机商品数据+MySQL、HBase存储
- 跨国际链路的数据服务系统架构设计的一种实现思路
- 分布式爬虫系统设计、实现与实战:爬取京东、苏宁易购全网手机商品数据+MySQL、HBase存储...
- Hay Day系统设计沉思录——数据存储
- 百亿数据毫秒响应级交易系统读写分离存储数据设计
- 了解如何设计和开发基于Http请求的数据接口服务系统
- 股票数据存储系统(Key-Value存储)设计与实现