POST实例详解 scrapy
cqupthub 任务三记录
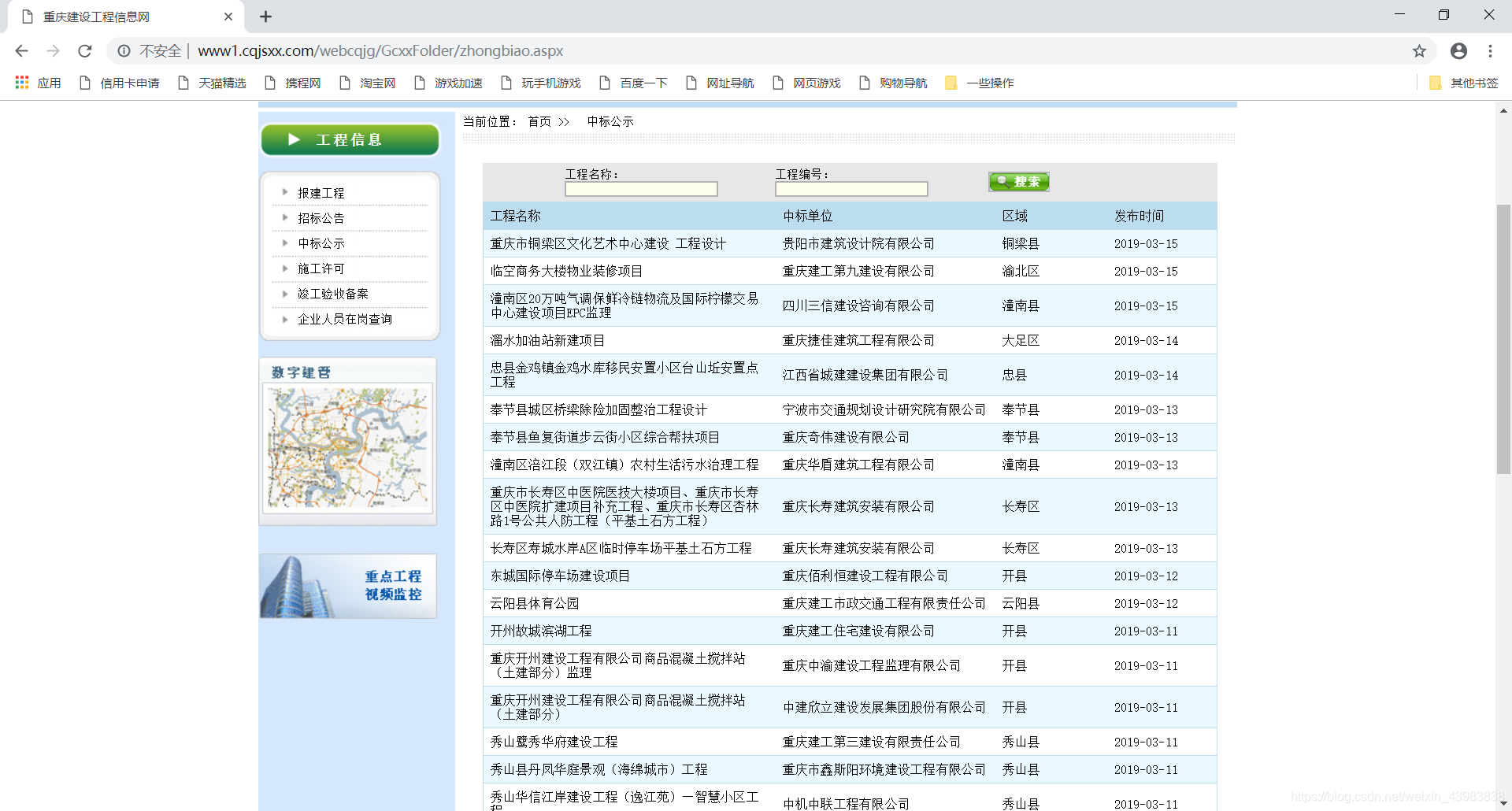
爬取网站:http://www1.cqjsxx.com/webcqjg/GcxxFolder/zhongbiao.aspx
爬取目标:从列表页,进入每一个详情页,爬取每个项目的编号,名称……
文章目录
重点
1、学会了用post
2、用meta传参数
用POST
- post是一种与服务器交互的方法
大概就是,我们POST一个表单给服务器,于是服务器会返回一些有用的东西给我们。我们再对返回的信息处理。
HTTP中的GET,POST,PUT,DELETE就对应着对这个资源的查,改,增,删4个操作。到这里,大家应该有个大概的了解了,GET一般用于获取/查询资源信息,而POST一般用于更新资源信息
- 首先,我们用scrapy.FormRequest来提交表单。
表单在网页中主要负责数据采集功能(包含表单标签、表单域、表单按钮)
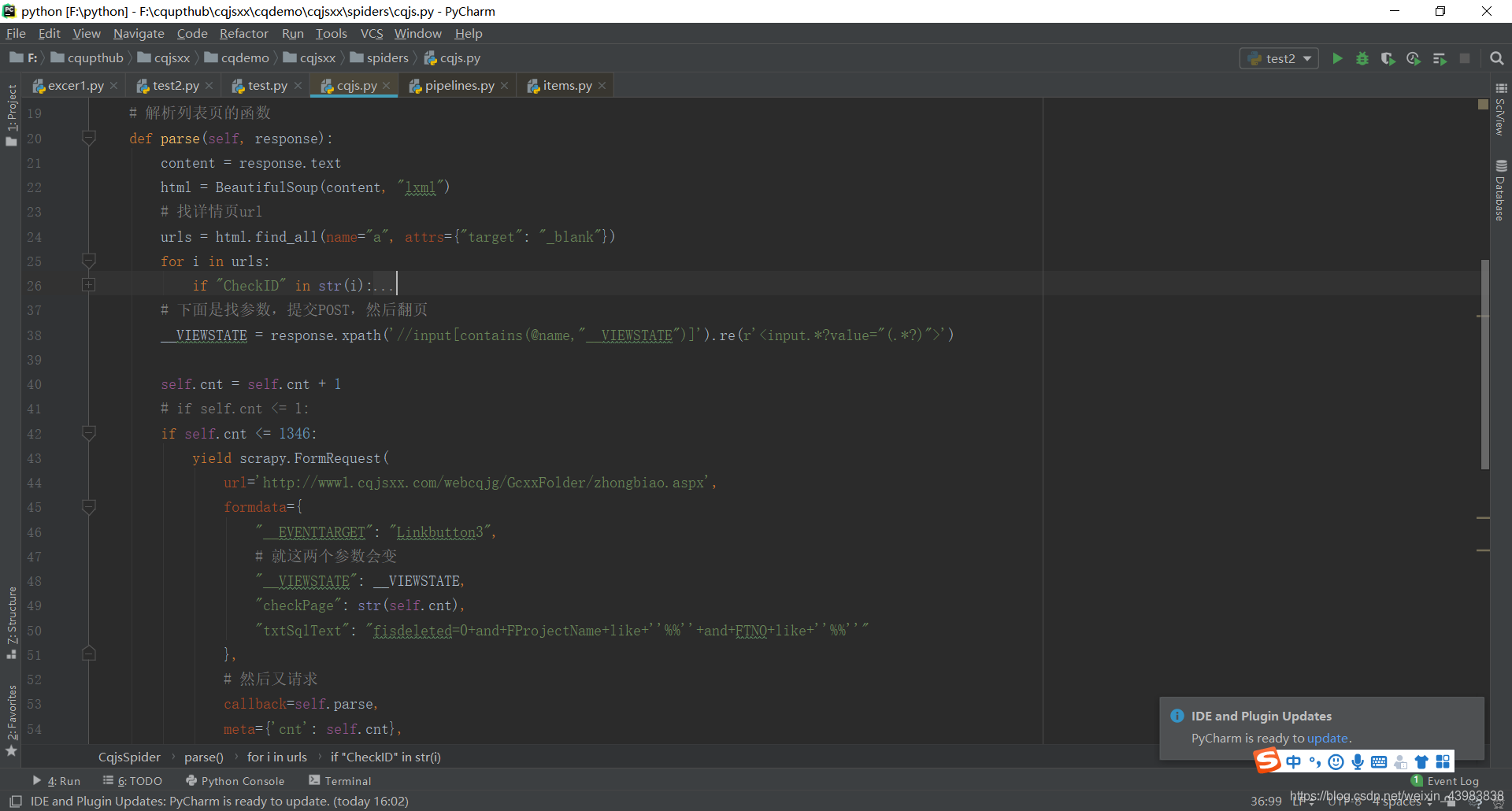
然后我们先爬取第一个列表页的内容
line 30 是得到详情页的url
line 33 是运用 Item类,infoDict 是我用来储存信息的字典
关于Item 爬取的主要目的就是从非结构性的数据源提取结构性数据。Scrapy提供Item类来满足这样的需求。Item对象是种简单的容器,保存了爬取到的数据,于是数据就从spider 通过 Item 传到了pipeline。其提供了类似于字典的API以及用于声明可用字段的简单语法。
line 37 这里我们通过 yield 来发起一个请求。并通过 callback 参数为这个请求添加回调函数,在请求完成之后会将响应作为参数传递给回调函数。通过 meta 传递含有url的字典。
关于yield 这种语法叫做生成器,所用到的函数就是 yield (迭代器和生成器,之后有时间再写一篇)。这里的yield 是到解析详情页的函数去
关于callback callback 是一个函数,在发生某一个事件后,会调用该函数。这里就是request之后,就会调用callback这里的函数
关于 meta meta是一个字典,它的主要作用是用来传递数据的,meta = {‘key1’:value1},如果想在下一个函数中取出value1, 只需得到上一个函数的meta[‘key1’]即可, 因为meta是随着Request产生时传递的,下一个函数得到的Response对象中就会有meta,即response.meta
line 40 这里是在response中找到 _VIEWSTATE 的参数值,用于请求下一页
line 42 cnt是我用来计页数的,在后面的POST中也会用到
line 47 提交表单,返回下一页的列表页
这里的 formdata 是包括需要提交的表单内容,用到了前面的_VIEWSTATE 和 cnt。
然后 callback 到 parse 函数(没错,就是它所在的函数,因为下一页也需要对列表页分析,得到详情页的url,和再下一页的post参数)
58行的 meta 用于传递页码
line 69 接受从meta传来的字典
line 71 用xpath找我们需要的内容
line 86 yield字典,给pipeline
csv写入时的一些问题
writerow中,只能有一项这里报错,显示 writerow() takes exactly one argument
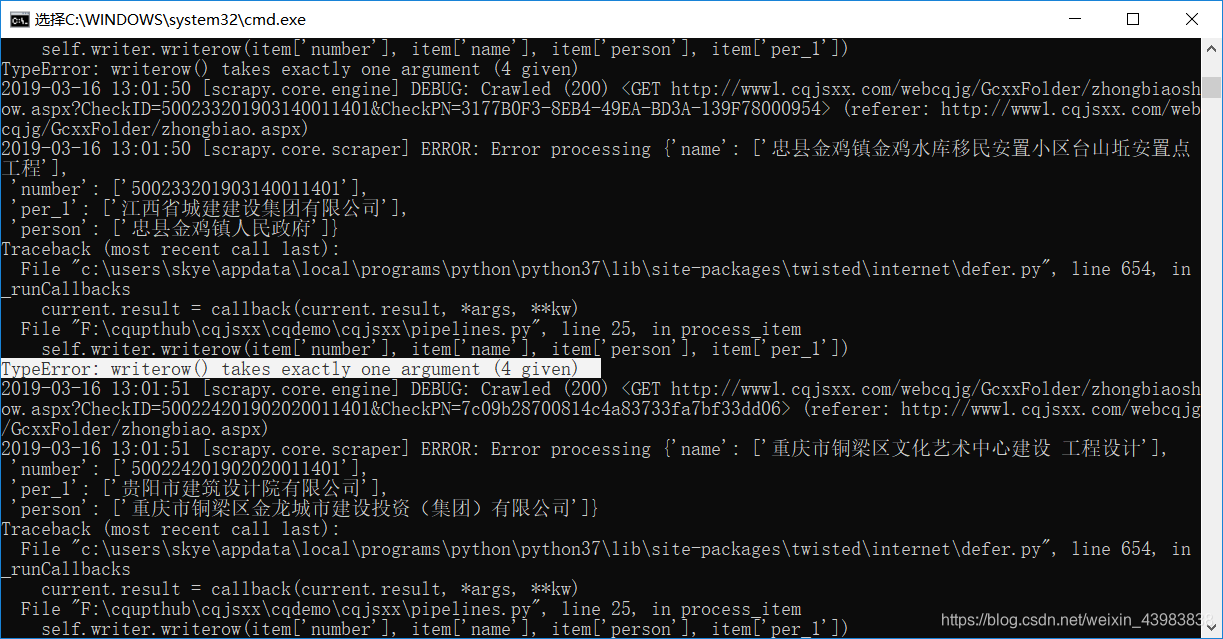
所以 writerow 这里还要加一个括号,像下面这样

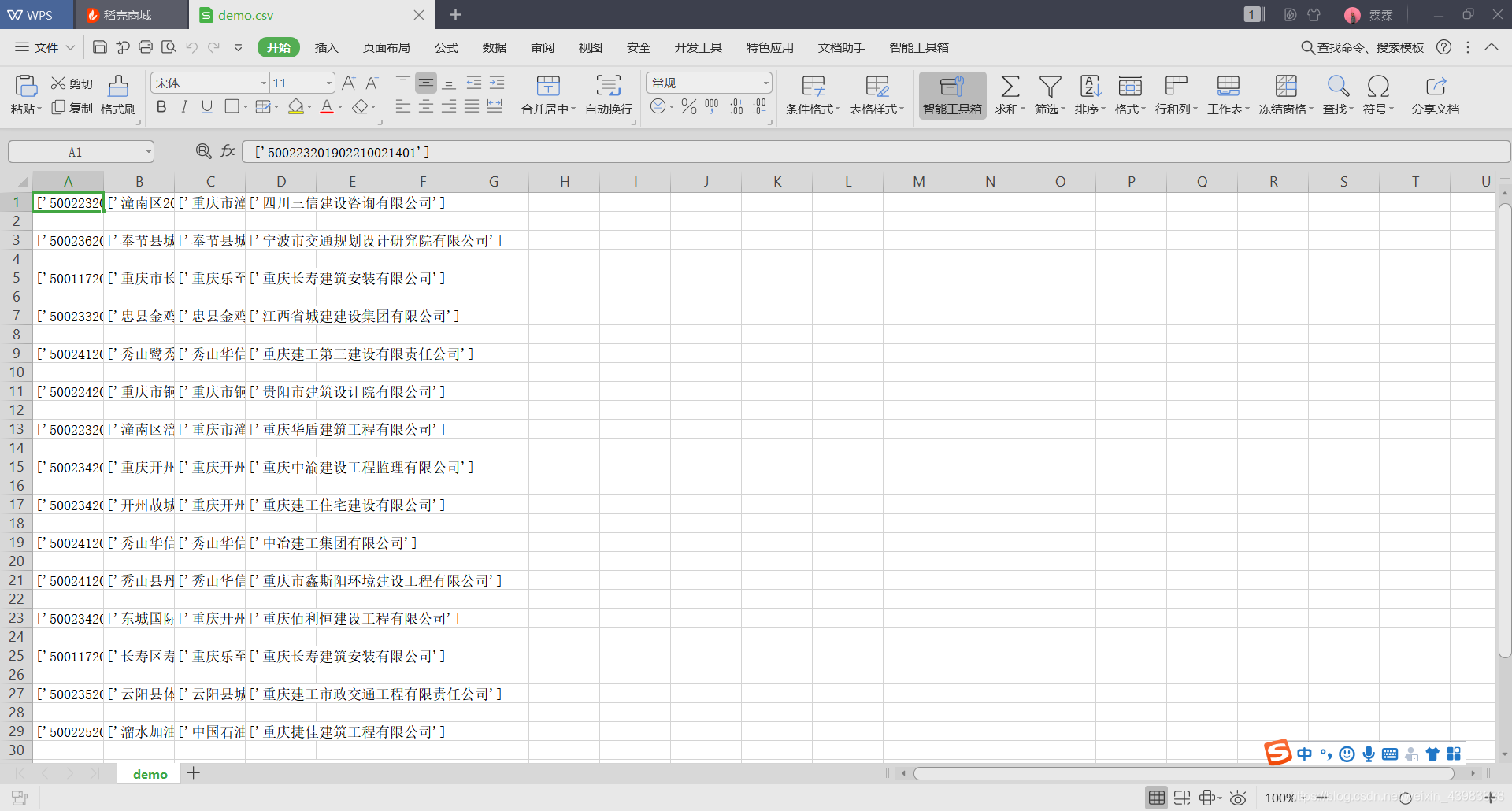
已经有写入了,但是我想,能不能去掉[’’]
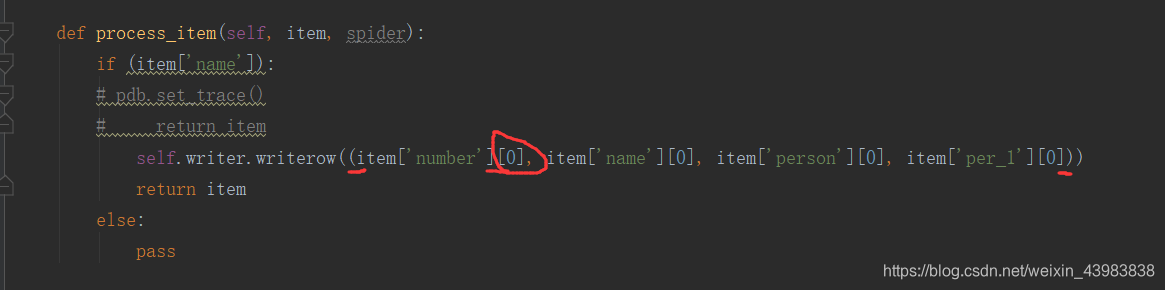
这样就可以去掉了,但是,数字又不对了
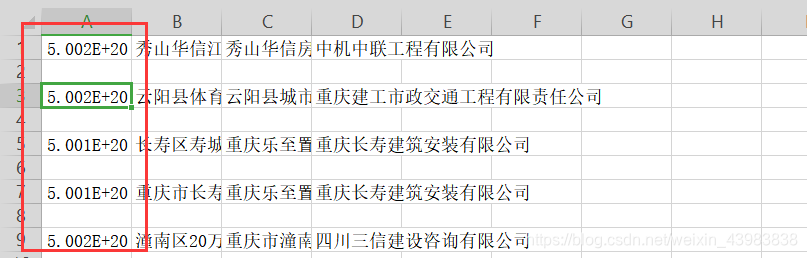
然后我加了个encode,然后csv中就会出现b‘’这样的前缀
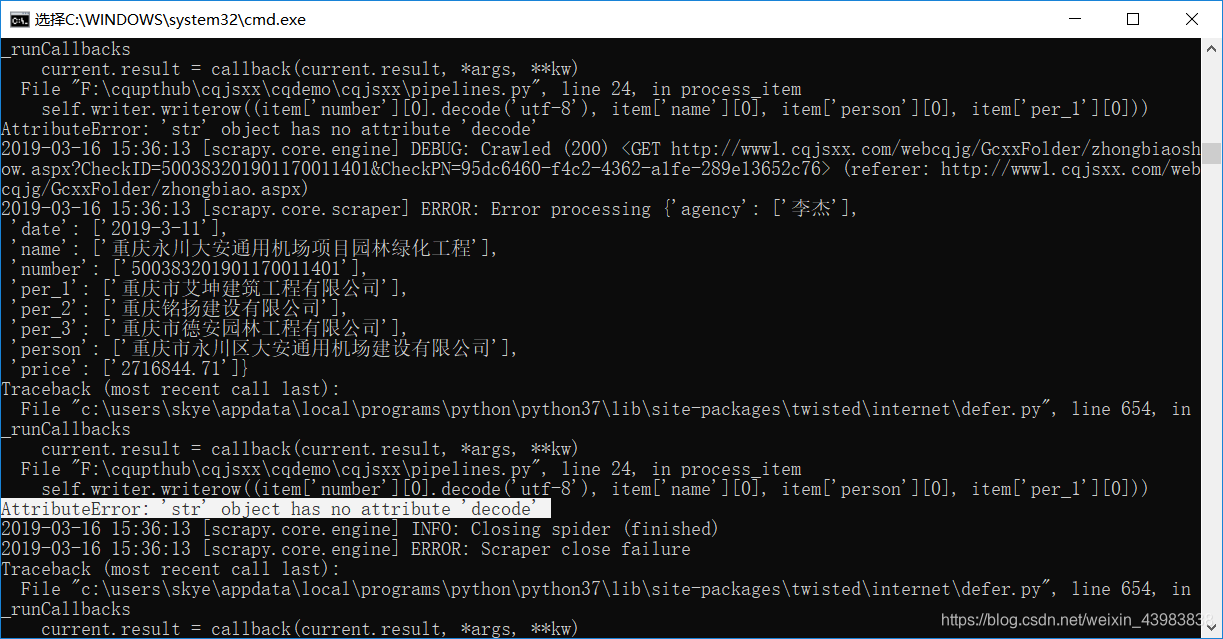
于是我又改成decode,就会有‘str’ object has no attribute ‘decode’
然后我就改成 encode(‘utf-8’).decode(‘utf-8’) 它又变成科学计数了
说明这里是字符串类型
最后,我手动在csv中取消科学计数法,就实现了。
csv空行问题,命令行执行写入csv空行问题,网上有人说:在scrapy的源代码中,加入newline = “”
但是我的源码中是有这个的,为什么还是有空行呢
发现这里有个 windows needs this
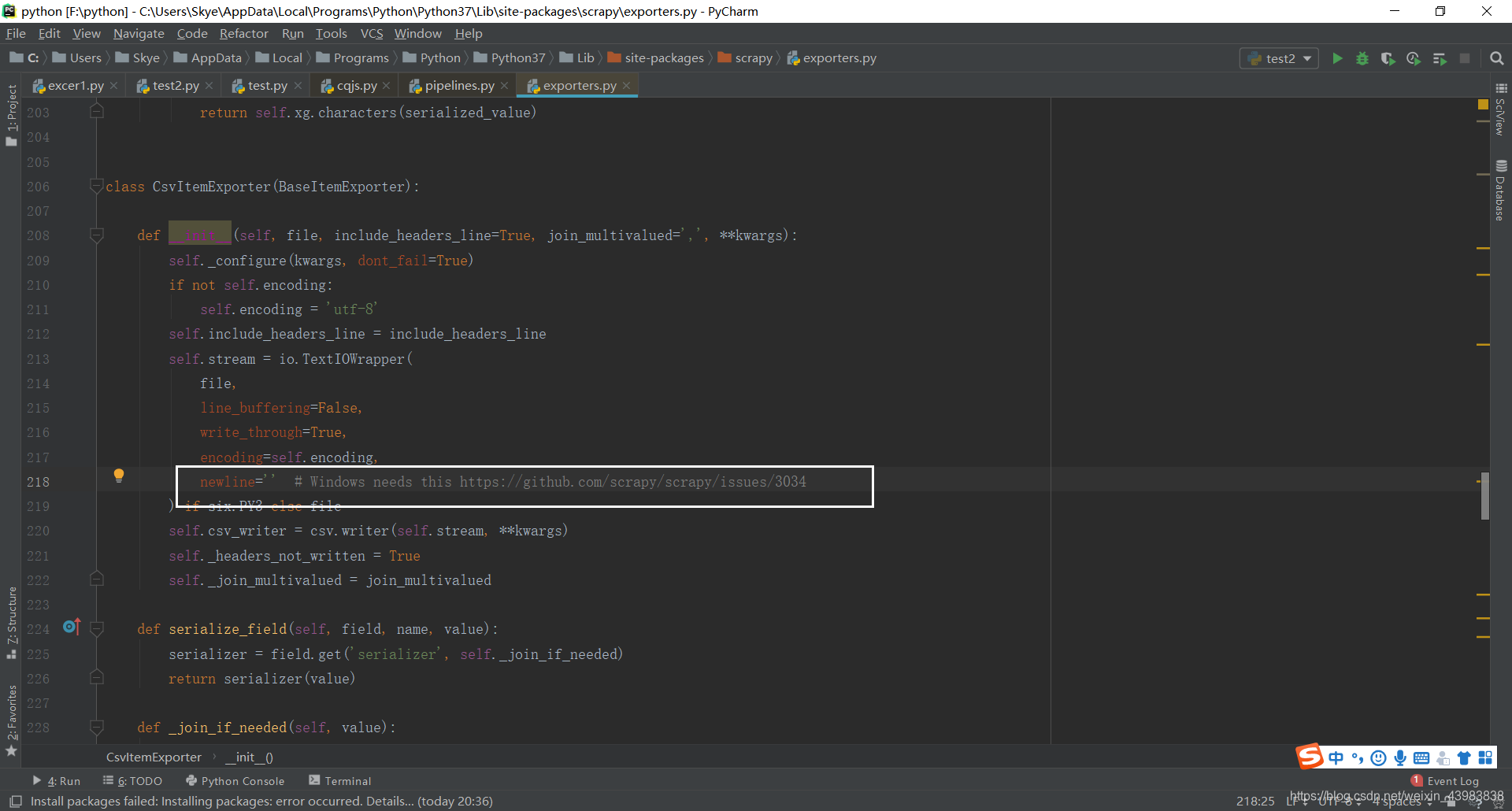
打开网页,嗯,并没有看懂
于是我就换了一种方式写入csv,把pipeline中的,都注释掉,直接pass
然后在命令行中执行写入csv文件,就没有空行问题了
用: scrapy crawl xxx(爬虫名字) -o xxx.csv(你要写入的文件名字) -t csv
吃个饭回来看爬取情况,居然到一万多条就停了。
然后准备重新爬
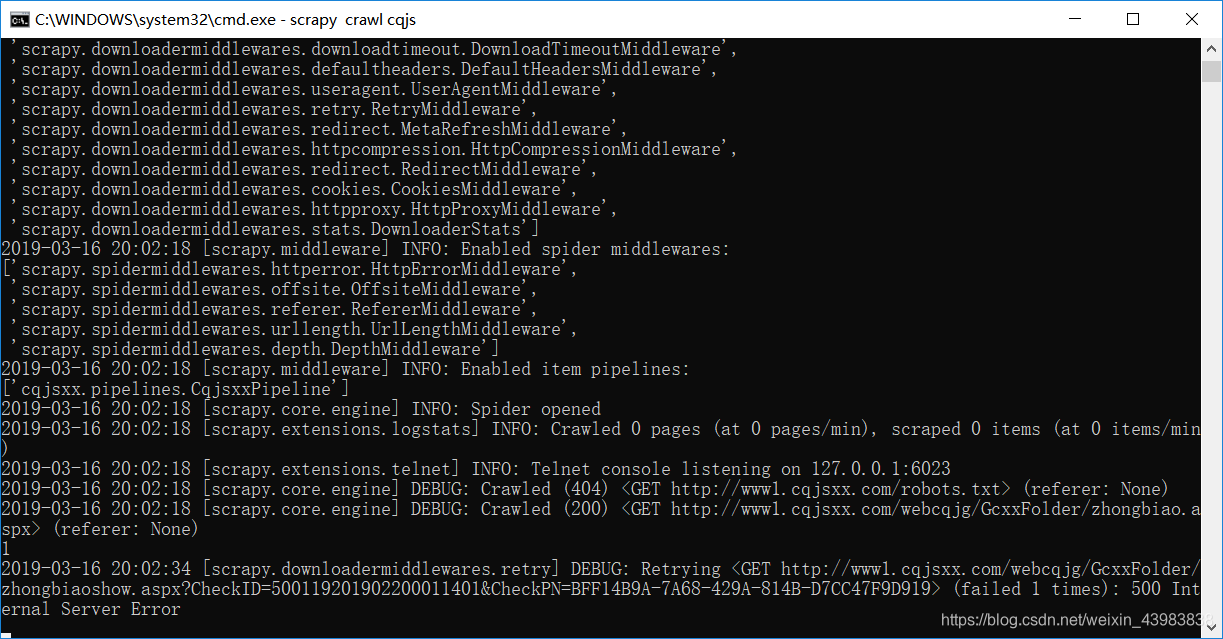
最后一行 显示 Internal Sever Error

然后网页打开也加载不了了
枯了,为什么我的IP又被封了
我找到表格中的最后一个项目,打算查找。
我的天,这网站找不到
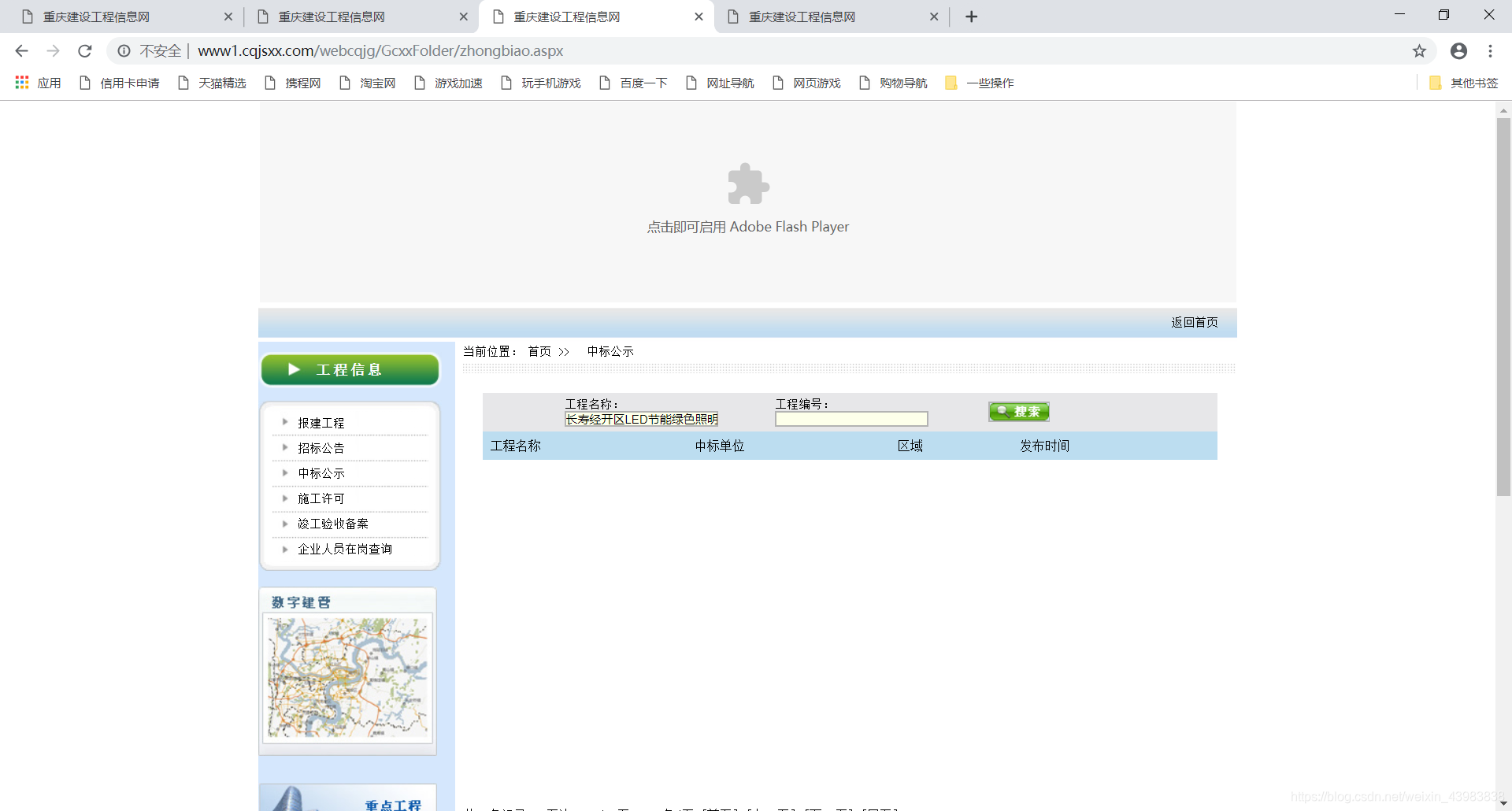
再看底下的翻页
不能直接跳转,只能上一页,下一页。
我真的要吐血了
后来换IP重新爬
附上代码
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
import re
from scrapy.http import Request
from cqjsxx.items import CqjsxxItem
import pdb
class CqjsSpider(scrapy.Spider):
name = 'cqjs'
cnt = 0 # 用来计翻页
def start_requests(self):
url = "http://www1.cqjsxx.com/webcqjg/GcxxFolder/zhongbiao.aspx"
yield Request(url, callback=self.parse)
# 解析列表页的函数
def parse(self, response):
content = response.text
html = BeautifulSoup(content, "lxml") # 用BeautifulSoup煲成一锅汤
# 找详情页url
urls = html.find_all(name="a", attrs={"target": "_blank"})
for i in urls:
# 有很多符合的 a 标签,这里找到含有 checkid 的标签,就是我们要找的目标标签
if "CheckID" in str(i):
# 详情页的url的后面一段
url_left = i["href"]
target_url = "http://www1.cqjsxx.com/webcqjg/GcxxFolder/" + url_left
# infoDict 在这里(而不是在解析详情页的函数里),是为了把url也放到字典里
infoDict = CqjsxxItem()
infoDict['url'] = target_url
# 用meta把字典传过去
yield Request(target_url, meta={'infoDict': infoDict}, callback=self.parse_detail)
# 下面是找参数,提交POST,然后翻页
__VIEWSTATE = response.xpath('//input[contains(@name,"__VIEWSTATE")]').re(r'<input.*?value="(.*?)">')
self.cnt = self.cnt + 1
print(self.cnt)
# if self.cnt <= 1:
if self.cnt <= 1346:
yield scrapy.FormRequest(
url='http://www1.cqjsxx.com/webcqjg/GcxxFolder/zhongbiao.aspx',
formdata={
"__EVENTTARGET": "Linkbutton3",
# 只有这两个参数会变
"__VIEWSTATE": __VIEWSTATE,
"checkPage": str(self.cnt),
"txtSqlText": "fisdeleted=0+and+FProjectName+like+''%%''+and+FTNO+like+''%%''"
},
# 然后又请求
callback=self.parse,
meta={'cnt': self.cnt},
dont_filter=True
)
else:
pass
# 解析详情页的函数
def parse_detail(self, response):
# 这次任务三用的xpath,在都匹配的情况下,比之前用的正则方便多了,耶~
# 接受meta传来的字典
infoDict = response.meta['infoDict']
infoDict['number'] = response.xpath('//*[@id="FTNO"]').re('>(.*?)<')
infoDict['name'] = response.xpath('//*[@id="FProjectName"]').re('>(.*?)<')
infoDict['person'] = response.xpath('//*[@id="FEmployer"]').re('>(.*?)<')
infoDict['per_1'] = response.xpath('//*[@id="FAwardOrgan"]').re('>(.*?)<')
# pdb.set_trace()
infoDict['per_2'] = response.xpath('//*[@id="FSecondAwardOrgan"]').re('>(.*?)<')
infoDict['per_3'] = response.xpath('//*[@id="FThirdAwardOrgan"]').re('>(.*?)<')
infoDict['agency'] = response.xpath('//*[@id="FHead"]').re('>(.*?)<')
infoDict['price'] = response.xpath('//*[@id="FAwardPrice"]').re('>(.*?)<')
infoDict['date'] = response.xpath('//*[@id="Gsjssj"]').re('>(.*?)<')
# pdb.set_trace()
yield infoDict

- JS与Ajax Get和Post在使用上的区别实例详解
- scrapy框架爬取知乎信息实例详解(详细)
- python爬虫框架scrapy实例详解
- AngularJS封装$http.post()实例详解
- python爬虫框架scrapy实例详解
- jQuery Ajax 实例详解 ($.ajax、$.post、$.get)
- jQuery中ajax的load()与post()方法实例详解
- python爬虫框架scrapy实例详解
- HttpClient详解与实例介绍(post方式与get方式)
- jQuery Ajax 实例详解 ($.ajax、$.post、$.get)
- JSP之表单提交get和post的区别详解及实例
- 微信小程序 POST请求(网络请求)详解及实例代码
- php获取POST数据的三种方法实例详解
- 微信小程序 POST请求的实例详解
- PHP 以POST方式提交XML、获取XML,解析XML详解及实例
- 微信小程序 POST请求(网络请求)详解及实例代码
- vue axios数据请求get、post方法及实例详解
- Android OkHttp Post上传文件并且携带参数实例详解
- get post jsonp三种数据交互形式实例详解
- python爬虫框架scrapy实例详解