Tensorflow 激活函数 activation function
激活函数 activation function
线性模型的局限性:只通过线性变换,任意层的全连接神经网络和单层神经网络的表达能力并没有任何区别,线性模型能解决的问题是有限的。
激活函数的目的是去线性化,如果将每一个神经元的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了,这个非线性函数就是激活函数。
评价某个激活函数是否有用时,需要考虑的因素有:
1)该函数应是单调的, 这样输出便会随着输入的增长而增长,从而使利用梯度下降法寻找局部极值点成为可能.
2)该函数应是可微分的,以保证该函数定义域内的任意一点上导数都存在,从而使得梯度下降法能够正常使用来自这类激活函数的输出.
-
ReLU函数
ReLU函数是个非常常用的激活函数,其公式为:
f(x) = max(0, x)
即,大于0的为其本身,否则为0.
tensorflow中,该激活函数为,
tf.nn.relu(
features,
name=None
)
计算修改线性:max(features, 0).
优点:1)使网络可以自行引入稀疏性,提高了训练速度;2)计算复杂度低,不需要指数运算,适合后向传播。
缺点:1)输出不是零均值,不会对数据做幅度压缩;2)容易造成神经元坏死现象,某些神经元可能永远不会被激活,导致相应参数永远不会更新。
卷积层后面通常用ReLUtf.nn.relu6(features, name=None)
以6为阈值的整流函数:min(max(features, 0), 6) -
Sigmoid函数
其公式为:
y = 1 / (1 + exp(-x))
其中,x的范围为正无穷大到负无穷大,y的范围为0到1.
它的曲线呈现S形,将变量映射到(0,1)这个值域范围上。它的导数 f’(x)=f(x)[1-f(x)]。
优点:1)输出范围有限,数据不会发散;2)求导简单。
缺点:1)激活函数计算量大,涉及指数和除法;2)反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。逻辑回归一般用sigmoid。
Sigmoid原函数及导数图形如下,由图可知,导数从0开始很快就又趋近于0了,易造成“梯度消失”现象。
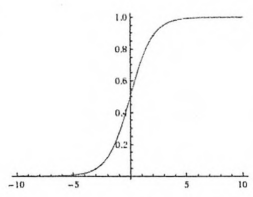
如上图所示,经过Sigmoid函数输出的函数都会在0~1区间里,但,可以看出,当x=10和x=1000其实输出的y差距并不大,所以可以看出,Sigmoid函数极限在x为-6到6之间,其中x在-3到3之间效果比较好。
tensorflow中,该激活函数为
tf.nn.sigmoid()
tf.sigmoid(
x,
name=None
) -
Tanh函数
tf.nn.tanh(
x,
name=None
)
其公式为:
y =(exp(x)-exp(-x))/(exp(x)+exp(-x)) = (1 - exp(-2x)) / (1 + exp(-2x))
导数:df(x)/dx=1-f(x)^2其中,x的范围为正无穷大到负无穷大,y的范围为-1到1.
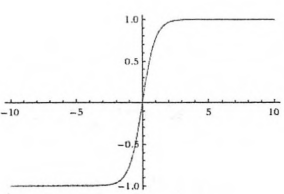
这个函数的作用是计算 x 的 tanh 函数。
tanh和tf.sigmoid非常接近,且与后者具有类似的优缺点,tf.sigmoid和tf.tanh的主要区别在于后者的值为[-1.0,1.0]
优点:输出范围[-1,1],解决了sigmoid非零均值的问题,在一些特定的网络架构中,能够输出负值的能力十分有用。
缺点:仍然存在梯度消失和幂运算的问题。
如果给Tanh的输入值很大,那在反向求梯度的时候就很小,不利于网络收敛。下图是Sigmoid和Tanh的对比:

(注意这里tanh和tan是不一样的,后者是正切函数,前者是双曲正切函数。) -
Swish函数
Swish激活函数的效果优于ReLU函数,公式如下:
y = x * sigmoid(βx)
其中,β为x的缩放参数,一般取1即可。

Tensorflow好像还没有定义该函数,但是我们可以用sigmoid函数自己定义,
def swish(x, b = 1):
return x * tf.nn.sigmoid(b * x) -
Softmax函数
Softmax函数主要用来处理分类问题,该函数将前向传播结果转为概率问题,所有概率之和为1。例如对(a, b, c)用softmax函数后为,
softmax=(exp(a)/(exp(a)+exp(b)+exp( c)), exp(b)/(exp(a)+exp(b)+exp( c)), exp( c)/(exp(a)+exp(b)+exp( c))).softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), axis)
在实际使用中,softmax函数的分类,一般都将分类标签转成one-hot编码,需要分成几类,就在这层放几个节点。例如前面说的MNIST数据集和CIFAR10数据集,最后一层的输出都是10个节点,因为这两个数据集都是十分类问题。
Tensorflow中,softmax函数为
tf.nn.softmax(
logits,
axis=None,
name=None,
dim=None
) -
tf.nn.dropout
tf.nn.dropout(
x,
keep_prob=None,
noise_shape=None,
seed=None,
name=None,
rate=None
)
解释:这个函数的作用是计算神经网络层的dropout。一个神经元将以概率keep_prob决定是否放电,如果不放电,那么该神经元的输出将是0,如果该神经元放电,那么该神经元的输出值将被放大到原来的1/keep_prob倍。这里的放大操作是为了保持神经元输出总个数不变。比如,神经元的值为[1, 2],keep_prob的值是0.5,并且是第一个神经元是放电的,第二个神经元不放电,那么神经元输出的结果是[2, 0],也就是相当于,第一个神经元被当做了1/keep_prob个输出,即2个。这样保证了总和2个神经元保持不变。默认情况下,每个神经元是否放电是相互独立的。但是,如果noise_shape被修改了,那么他对于变量x就是一个广播形式,而且当且仅当 noise_shape[i] == shape(x)[i] ,x中的元素是相互独立的。比如,如果 shape(x) = [k, l, m, n], noise_shape = [k, 1, 1, n] ,那么每个批和通道(channel component)都是相互独立的,但是每行和每列的数据都是关联的,即要不都为0,要不都还是原来的值。
import tensorflow as tf
a = tf.constant([[-1.0, 2.0, 3.0, 4.0],[-3.0, 4.0, 5.0, 6.0]])
print(a)
with tf.Session() as sess:
b = tf.nn.dropout(a, 0.5) # 第0维相互独立,第1维相互独立,0维是列,1维是行
print(sess.run(b))
b = tf.nn.dropout(a, 0.5, noise_shape=[2, 4]) # 第0维相互独立,第1维相互独立的
print(sess.run(b))
b = tf.nn.dropout(a, 0.5, noise_shape=[2, 1]) # 第0维相互独立,第1维不相互独立的
print(sess.run(b))
b = tf.nn.dropout(a, 0.5, noise_shape=[1, 4]) # 第0维不相互独立,第1维相互独立的
print(sess.run(b))
b = tf.nn.dropout(a, 0.5, noise_shape=[1, 1]) # 第0维不相互独立,第1维不相互独立的
print(sess.run(b))输出为:
Tensor(“Const_48:0”, shape=(2, 4), dtype=float32)
[[-0. 4. 0. 8.]
[-0. 0. 10. 12.]] // 第一个默认都是相互独立的
[[-2. 4. 0. 8.]
[-6. 0. 10. 0.]] // 第二个 noise_shape=[2, 4]=shape=(2, 4),所以也是都相互独立的
[[-0. 0. 0. 0.]
[-6. 8. 10. 12.]] //第三个 noise_sha 24000 pe=[2, 1],所以1维不相互独立,1维是行,所以要么整行全部都0,要不全部都乘以2
[[-0. 0. 6. 8.]
[-0. 0. 10. 12.]] // 第四个 noise_shape=[1, 4],第0维不相互独立,0维是列,所以6和10,8和12, 0和0这些是不独立的。
[[-0. 0. 0. 0.]
[-0. 0. 0. 0.]] // 第五个 noise_shape=[1, 1],第0维和1维都不独立,所以它要么全0,要么全部乘以2,只有两种可能。

- Tensorflow深度学习之五:激活函数
- 2卷积神经网络相关API详解-2.3/2.4TensorFlow之激活函数API详解(上/下)
- 话谈tensorflow神经网络的激活函数
- 8、TensorFlow 中的激活函数
- tensorflow自定义网络层、激活函数(self-defined layer)
- tensorflow-激活函数及tf.nn.dropout
- Tensorflow 激活函数
- TensorFlow - C++仿写TensorFlow的激活函数并以图表的形式展示
- Tensorflow中神经网络的激活函数
- [TensorFlow 学习笔记-06]激活函数(Activation Function)
- TensorFlow 基础练习 4 activation 激活函数
- class4---tensorflow:损失函数-激活函数、交叉熵、softmax函数
- tensorflow 学习笔记3 placeholder与激活函数
- tensorflow中的激活函数
- 感知机相关;利用tensorflow等工具定义简单的几层网络(激活函数sigmoid),递归使用链式法则来实现反向传播。
- Tensorflow--激活函数
- tensorflow: 激活函数(Activation_Functions) 探究
- TensorFlow(八)激活函数
- tensorflow学习-------激活函数(activation function)
- TensorFlow激活函数+归一化-函数