文本预处理挖掘之TF-IDF附使用互信息进行特征挑选的过程(任务二)
文本数据预处理之TF-IDF
我们知道词频矩阵是将n-gram词的频率转成向量(频数放置相应维度),但我们可以很明显的发现问题,一些在很多文本中频繁出现的常用词(有些时候我们会将其当做停用词删掉)其权重会比较高,但是其实因为它几乎在每句话都会出现,故而其重要性也许并不如词频矩阵所表现的那样。
TF-IDF概述(词频-逆文本频率)
TF也就是我们所说的词频,而IDF指的是逆文本频率,IDF反映了一个词在所有文本中出现的频率,如果一个词在很多的文本出现,那么他的IDF值应该很低。
IDF(x)=log((N+1)/(N(x)+1))+1
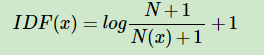
其中N代表语料库中文本的总数(样本数),而N(x)代表语料库中有多少文本包含词x。 至于图片中分子分母包括取对数后加的1都是为了使IDF平滑(类似于加载分母上的eplcsion)
这时,我们的TF-IDF值就呼之欲出了:TF-IDF(x) = TF(x) * IDF(x)
TF-IDF的sklearn调用
from sklearn.feature_extraction.text import TfidfVectorizer corpus = ["I come to China to travel", "This is a car polupar in China", "I love tea and Apple ", "The work is to write some papers in science"] res = TfidfVectorizer().fit_transform(corpus) print(res)

参数介绍
可以发现sklearn中的tfidf使用十分简单,但是其功能却十分强大,接下来我们介绍几个常用的参数:
1、input:[‘file’,‘filename’,‘content’],默认为content也就是认为你的输入是一堆现成的句子(corpus),若是将其设置为file则是输入一个file对象,filename的话则是由sklearn后台读取文本再将其转化。
2、encoding and decoder_error:前者在输入为文件或是二进制文本时使用,也就是sklearn需要对输入进行解码的格式, 而后者是其搭配的参数,负责控制解码错误时的操作(默认为strict也就是错误时会报错,单个人一般设置为ignore,因为一般做的都是英文分类所以在ascii码之外的字符也是我不需要考虑的字符)
3、preprocessor: 这是一个函数输入口,我们可以将需要对文本做的预处理写成func然后放在这里,这样sklearn就会后台帮我们调用并对所有文本执行(很方便的说)
4、analyzer: [‘word’,‘char’,‘char_wb’] 控制我们是以字符级还是词级来提取n-gram特征,word为默认值,我们来讲讲char时的表现,sklearn会将一段英文拆分为一个个字母,然后根据设置的n-gram对其提取特征,至于char_wb则是对每个二进制字符提取特征(做代码分类时也许粒度最细的char_wb会有奇效哦)
5、stop_words:[{‘englist’}, None] 默认为None, 可以使用englist来删除英文中的常见停用词,也可以使用自定义的停用词库
6、max_features: int值,根据tf-idf值排序,取前max_features作为特征
特征挑选之 Filters篇
在我们刚开始学机器学习时曾以为数据越多越好,特征越多表达越多,性能自然就越好。但当我们里机器学习入门的门槛更近一点时我们尴尬的发现有时候特征一多性能就会下降,或是遇到机器学习中最可怕的一种情况:过拟合。
为什么特征一多就会发生这种情况呢,比如说我们现有一堆家庭收入数据,其中有爸爸的工资,爸爸的税收,妈妈的工资,妈妈的税收。我们知道税收和收入是程正相关的,属于非常强的一种关联,在学习器学到两种或多种非常相似的特征时可能会导致学习器过拟合(就好比你吃了一个苹果,又吃了一个蛇果,最后还吃了一个平安果,从此你对这类水果产生了偏执或是厌恶)。 还有就是特征中可能会初夏一些对模型继承毫无帮助的特征,更甚至还有些特征存在噪声导致模型不能很好的收敛。
这时候我们就需要使用一些特征筛选的方法了,这里我们需要介绍的是第一大类Filters,也是最简单的一类,我们可能根据一些相关性方法(卡方检验,互信息,皮尔逊等)来给特征与目标做相关性检测,每个特征都能得到分数,我们就可以设置一个阈值(或取前多少)来做特征挑选。
互信息
Filters中最常用的相关性方法之一:互信息(mutaul),一个既可用于分类又可用于回归的相关性方法(像卡方检验就只能用于分类了),其公式如下:
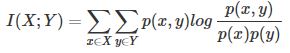
其衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。所谓的随机变量,即随机试验结果的量的表示,可以简单理解为按照一个概率分布取值的变量,比如随机抽查的一个人的身高就是一个随机变量。
## 数据集来源: https://www.figure-eight.com/data-for-everyone/
## 该网站有很多关于cv和nlp的小数据集,十分适合练手使用
## 本数据集为推特文本分类是否为天气变暖数据集,第一列为推特文本,第二列为其类别(是关于天气变暖,否,未知,空)
## 第三列为类别的置信度
import pandas as pd
from sklearn.feature_selection import mutual_info_classif
datas = pd.read_csv('data/global_warming.csv',sep = None, error_bad_lines=False)
print(datas.info())
datas.head()

这里我们看出这个数据集的大概内容,因为我们这里只是简单的做一个文本分类,所以我们直接删除所有类别为空的数据集(其实我们可以将其作为一个单独特征出现,比如类别为空的为1,不为空的为0,因为空值本身就代表了一些信息),之后我们会对其做文本tf-idf提取(因为是英文所以我们不需要分词,只需要选用英文的停用词特征即可),之后用lightgbm做个简单分类,最后我们会对其做特征挑选最后在分类一波看是否有明显提升。
from lightgbm import LGBMClassifier
from sklearn.model_selection import *
from sklearn.feature_extraction.text import *
from sklearn.preprocessing import *
import numpy as np
# 删除类为空的样本
datas = datas.dropna()
# 转化文本为tfidf矩阵
tfTor = TfidfVectorizer(stop_words={'english'}, ngram_range=(2,3), max_features=10000, )
texts = tfTor.fit_transform(datas['tweet'].values).toarray()
labels = LabelEncoder().fit_transform(datas['existence'])
# 实例化分类器(用默认参数)
lgb_clf = LGBMClassifier(random_state = 10086, n_jobs=-1)
scores = cross_val_score(lgb_clf, texts, labels, cv = 3, n_jobs = -1)
print('未进行特征挑选前,得分为{}'.format(np.average(scores)))
未进行特征挑选前,得分为0.649948113495569
看样子得分很低啊, 我们尝试下进行特征挑选是否能使其性能变好一些。
from sklearn.feature_selection import mutual_info_classif
mutual_values = mutual_info_classif(texts, labels)
print('mean of mutual score', np.median(m
1fff8
utual_values))
print('numbers of mutual score euqal zero ',sum(mutual_values == 0))
texts = tfTor.fit_transform(datas['tweet'].values).toarray()
labels = LabelEncoder().fit_transform(datas['existence'])
idx = [i for i, value in enumerate(mutual_values) if value > 0]
texts = texts[:,idx]

scores = cross_val_score(lgb_clf, texts, labels, cv = 3, n_jobs = -1)
print('进行特征挑选后,得分为{}'.format(np.average(scores)))
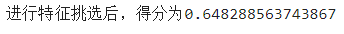
哇,装逼失败,看样子删除的mutual为0 的特征中其实有有价值的特征,但是互信息并没有发现,不过大概操作步骤就是这样。一般在实际挑选中,个人喜欢特征间做相关性检测,然后将相关性高的lightgbm(feature_importance)低的删除。

- 分别使用CountVectorizer与TfidfVectorizer, 并且去掉停用词的条件下,对文本特征进行量化的朴素贝叶斯分类性能测试
- 使用TfidfVectorizer并且不去掉停用词的条件下,对文本特征进行量化的朴素贝叶斯分类性能测试
- 使用LIBSVM对原始文本语料进行文本分类(二)——特征选择(信息增益方法)
- 文本挖掘预处理之TF-IDF
- 使用python进行文本预处理和提取特征的实例
- (6)文本挖掘(三)——文本特征TFIDF权重计算及文本向量空间VSM表示
- 使用sklearn进行文本TF-IDF处理
- Python 文本挖掘:使用机器学习方法进行情感分析(一、特征提取和选择)
- (6)文本挖掘(三)——文本特征TFIDF权重计算及文本向量空间VSM表示
- python中对不CountVectorizer与TfidfVectorizer,去停用词,对文本特征量化结合Bayes算法进行分类,可视化分析
- 【python】 文本挖掘预处理之TF-IDF
- 使用Weka进行数据挖掘(Weka教程五)Weka数据预处理之Filter使用
- 文本挖掘过程的特征提取
- Python 文本挖掘:使用gensim进行文本相似度计算
- 文本挖掘——基于TF-IDF的KNN分类算法实现
- Python 文本挖掘:使用gensim进行文本相似度计算
- Python 文本挖掘:使用gensim进行文本相似度计算
- 特征提升之特征提取-基于文本数据的DictVectorizer,TfidfVectorizer在去掉停用词和不去停用词条件下的分析
- 文本分类程序的实现过程(C++语言)——特征选择的预处理
- 词语相似度计算:4、提取文本tf、tfidf特征