Python+OpenCV图像处理与识别 Step by Step

我们理解图像识别,总体上分三步:
- 图像的采集
- 图像的处理
- 图像的识别
其中,图像采集和处理是相辅相成的,如果图像的采集能够保证明暗色彩等要素的稳定和统一,那么在处理图像时成功率会提升很多;反之如果图像处理的算法足够强大,对图像采集的要求就会相对的降低。
而只有正确的进行了图像的处理后,图像才能够被识别。
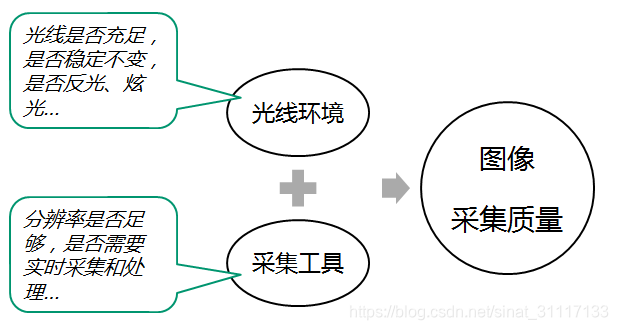
图像的采集
图像采集需尽可能的保证图像的一致性,即图像的明暗程度、角度一致,这样能够为图像处理和识别提供很大的便利,提升成功率。
图像的处理
目的:
图像处理的最终目的是:截取便于识别的图像区域。
例:识别出图中温度计上的数字。

原理:
图像是由若干像素点构成,每个像素点的颜色都是由光的三原色(红、绿、蓝)组合而成。因此每个像素点都可以用一个元组(R,G,B)表示。其中R、G、B为0-255范围的数字, R即red,G即green,B即blue。(0,0,0)即黑色,(255,255,255)即白色,(255,0,0)即红色,(255,255,0)即黄色…图片其实就是一个二维数组,数组中的每个元素都是(R,G,B)元组。对图像的处理实际上就是对这个二维数组的处理。分辨率就是Image[m]
这个数组的m和n。

Step1——压缩与灰度图
照相机采集到的图像,分辨率可能很大,在处理图片前,先根据实际需要对图片进行压缩,我们把它压缩到800*600:
image = cv.resize(image, (800, 600), interpolation=cv.INTER_AREA)
图像处理第一步通常是把彩色的图像变成灰度图:
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
灰度图其实是利用了人类心理对于不同色彩的亮度的认知,经典转换公式:
Gray=(R*0.299+G*0.587+B*0.114)
效果如下图,这样每个像素点的描述就从(R,G,B)三个向量变成了一个亮度的数值Gray(0-255)。这是进行后续算法的基础。

Step2——二值化
灰度图中每个像素点都是用0-255中的一个数字表示的,而二值化的意思是设置一个阈值,按照阈值把灰度变成黑白,阈值之上都是255,阈值之下都是0。由于此图中数字是黑色的,所以我们需要反转黑白,让数字显示为白色:
(_, thresh) = cv.threshold(gray, 55, 255, cv.THRESH_BINARY_INV)
效果如下图,需要注意的是,这个阈值的设置是与图像采集重要相关的。可以采用参考系来选定阈值。
另外,我们可以看到图像中除了数字外还有很多白色或黑色的无用噪点。接下来应对噪点进行处理。

Step3——腐蚀和膨胀
为了去掉二值图中除了数字之外的白颜色的“噪声”,我们使用的方法是,先腐蚀,然后再膨胀。
腐蚀的意思是,扩展图像中黑色的部分。由于图像中白色的噪声与数字相比要细小,所以腐蚀后白色噪声会消失,而数字会变细变小。
膨胀的意思是,扩展图像中白色的部分。这样可以去掉黑色的噪点,数字变细后,再膨胀,把数字部分适当的扩大。
erode = cv.erode(thresh, None, iterations=5)
pic = cv.dilate(erode, None, iterations=15)
效果如下图,代码中进行了5次腐蚀,之后进行了15次膨胀,这样图像中数字的范围会比真实的数字略大,保证切割出的数字范围内包括了数字的全体。

Step4——横向模糊
为划定数字的范围,需要把Step3图中白色数字框起来。由于数字间依然存在黑色的缝隙和孔洞,所以我们要进行模糊,用白色填充上这些缝隙。我们想把两行数字分开划分区域,因此只做横向的模糊:
rectkernel = cv.getStructuringElement(cv.MORPH_RECT, (100, 1))
closed = cv.morphologyEx(pic, cv.MORPH_CLOSE, rectkernel)
效果如右图,这里用的是闭运算方法,本质上也是先膨胀后腐蚀。横向上做大范围的闭运算,纵向上基本忽略。

Step5——获取矩形轮廓
利用OpenCV提供的API,获取Step4图中白色区域的矩形轮廓,并对轮廓的大小做出限定(宽度小于400像素)。
(cnts, _) = cv.findContours(closed.copy(), cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
image_parts = []
for cnt in cnts:
x, y, w, h = cv.boundingRect(cnt)
if w < 400:
cv.rectangle(image,(x,y),(x+w,y+h),(0,255,0),3)
image_parts.append(gray[y:y + h, x:x + w])
这样就可以获得到数字的范围了。
把Step1中的灰度图按照Step5得到的数字范围截取下来,就可以进行下一步的处理了。

Step6——数字图像部分处理
为了进行后续的图像识别算法,要把图像部分进行再次的二值化、去噪处理,这样就得到了我们目标的图像:
(_, thresh) = cv.threshold(gray_image, THRESHOLD, 255, cv.THRESH_BINARY)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (1, 1))
dilate = cv.dilate(thresh, kernel)
pic = cv.erode(dilate, kernel)
效果如右图,图像处理部分就结束了。
下面开始识别切割下的数字的图像中的内容。


图像的识别
OCR(Optical Character Recognition,光学字符识别)
电子设备检查纸上或图像中的字符,通过检测暗亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字
数字识别采用的步骤如下:
- 分割为单个数字
- 对每个数字采集特征值
- 把特征值与数据库中数字的特征值比较,
得到结果

其中,分割成单个数字是指把26.3分割成2 6 . 3四个部分,然后再进一步的识别每个部分。
采集特征值,由于0-9包括小数点每个数字的特征都比较明显,为提升执行速度,我们用了相对简单的算法采集特征。
数据库是指特征值数据库,这个数据库是用户通过训练建立的。
Step1——分割为单个数字

数字图片边缘存在黑边(图片采集时的阴影)。边缘阴影特点是越靠近边缘越宽(长)。图片此时实际上是以数组的数组形式保存的,每一行像素都是个数组,像素值是0(白)或1(黑)。可以通过遍历边缘向内侵蚀的方法把与边缘接壤的1全部变成0。
把数组中上下左右全部为0的边缘部分切掉。
在切掉边缘后,找数组中黑色部分的起始和终止点,可以得知单个数字的个数和单个数字的范围。
在获取单个数字范围后,切割下每个数字,后续识别特征值。
Step2——采集特征值

特征值采集我们采用的算法是把数字分割成四份,每份中黑色部分占整体的比例保存成一个值,设为a。整个数字中黑色占整体的比例保存成一个值,设为A。这样就有一个5维的向量: (a1,a2,a3,a4,A)
这个向量就是这个数字的特征值。
在进行特征值比较前,我们需要对所有的数字(0-9,.)进行特征值的采集,并保存到数据库中。这个过程叫做训练。由于图像采集的结果,每个数字可能存在微小的差异,我们训练采集到的特征值越多,最后特征比较的结果就越准确。
Step3——特征值识别
比较两个向量,向量最接近的就是最相似的。

效果:


- Python-OpenCV 处理图像(六):对象识别
- 基于OpenCV及Python的数独问题识别与求解(一)图像预处理
- opencv-python人眼识别图像处理基础
- Python-OpenCV 处理图像(六)(七)(八):对象识别 图像灰度化处理 图像二值化处理
- opencv for python 之 图像处理 阀值转换 侵蚀
- OpenCV图像处理和图像识别常用函数
- Python3与OpenCV3.3 图像处理(十五)--图像二值化
- Python-OpenCV学习(四):基本图像处理
- Python OpenCV学习笔记之:图像梯度处理:Laplacian,Sobel算子
- 图像处理和图像识别中常用的OpenCV函数
- Python-Opencv 图像处理基本操作(一)
- 【图像处理】Ubuntu安装OpenCV 3.0以及Python接口
- Python3与OpenCV3.3 图像处理(十二)--图像直方图应用
- Python-OpenCV 处理图像(一):基本操作 cv2
- 基于opencv的Python图像处理
- Opencv3.0-python的那些事儿:(一)、Opencv的图像和视频处理基本用法
- python for OpenCV图像处理之模板匹配以及分水岭算法
- python 使用OpenCV库实现图像处理
- Python OpenCV处理图像之滤镜和图像运算
- Python3与OpenCV3.3 图像处理(二十五)--开闭操作(补充)