Differentiable Learning of Logical Rules for Knowledge Base Reasoning
Differentiable Learning of Logical Rules for Knowledge Base Reasoning
来源
2017 Nips
Fan Yang Zhilin Yang William W. Cohen
School of Computer Science
Carnegie Mellon University
{fanyang1,zhiliny,wcohen}@cs.cmu.edu
背景
在人工智能和机器学习领域,学习由一阶逻辑规则组成的集合是一个重要的问题,由于它的可解释性,逻辑规则表示在知识图谱推理任务中非常有用。一个新的事实加入到知识图谱中,规则在不再训的情况下依然保持准确性。通常的底层逻辑是概率逻辑,使用概率逻辑的好处是可以丰富逻辑规则,可以处理更复杂和具有噪声的数据。学习这样概率逻辑规则是非常困难的,不仅要求学习离散空间中的规则结构,还需要学习连续空间中的参数(规则的置信度)。
结构化embedding 方法是知识图谱推理中非常流行的方法,这些方法通常是将实体以及关系表示为潜在语义空间中向量或者张量,基于embedding的方法解释性较差,并且当有新的事实加入到知识图谱中时,可能会导致一些结果的不准确。
Motivation
本文讲探索一个可微的系统可以学习由一阶逻辑规则集合组成的模型,这样的好处是允许使用基于梯度的优化方法和目标规划框架。本文受TensorLog的启发,将推断任务编译成可微的数值矩阵序列,这个方法叫做Neural LP
模型
知识库推理:本文考虑的知识图谱推理任务是对于一个查询和一个尾实体,头实体是查询的答案。目标是检索出实体的排序,使得满足查询的实体有尽可能靠前的排序。对于每个查询,本文的兴趣在于学习具有如下形式的带有权重的链式规则,

TensorLog:
将实体表示成one-hot的形式,一个关系R表示为邻接矩阵MRM_RMR,MR(i,j)=1M_R(i,j)=1MR(i,j)=1表示实体i 和实体j之间存在关系R。逻辑规则推断可以表示成算子的运算。P(Y,Z)⋀Q(Z,X)−>R(Y,X)P(Y,Z)\bigwedge Q(Z,X)->R(Y,X)P(Y,Z)⋀Q(Z,X)−>R(Y,X) 表示为MP⋅MQ⋅vx=sM_P\cdot M_Q\cdot v_x = sMP⋅MQ⋅vx=s, 如果s是非零向量,则表明存在y,z,x满足P(y,z)P(y,z)P(y,z), Q(z,x)Q(z,x)Q(z,x), 类似任意长度的逻辑规则可以归结为算子的运算。
对于每一个查询,期望能够学习到一些带有置信度(权重)的规则:
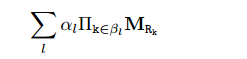
在进行推断的时候,给定一个实体vxv_xvx, 对于检索到的实体进行打分:
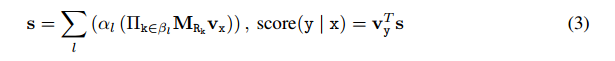
因此对于每个查询来说,我们的目标函数是:
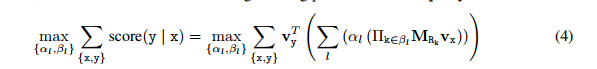
(x,y)(x,y)(x,y)是满足查询的实体对,ala_lal 和βl\beta_lβl需要学习的,
学习逻辑规则:
可微的逻辑规则学习过程难点在于参数是和每个规则关联的,但是规则是离散的。
为了克服这个困难,将(2)式转化成如下形式:

TTT表示规则的最大程度,RRR表示关系的数量。
在上面(5)(5)(5)中,所有的规则具有相同的长度,为了克服这一点,引入了循环的形式:
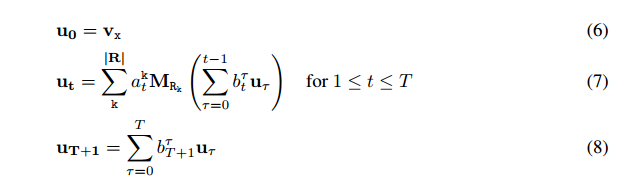
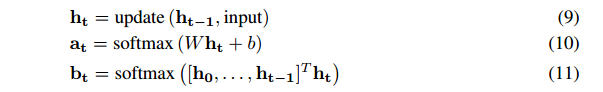
内存中维护utu_tut, 计算hth_tht使用了lstm模型,inputinputinput指的是1≤t≤T1\leq t \leq T1≤t≤T 时的query, 这里的query 指的是关系的向量表示
目标函数:最大化logvyTulog v^T_yulogvyTu
本文逻辑规则推断系统架构如下图:
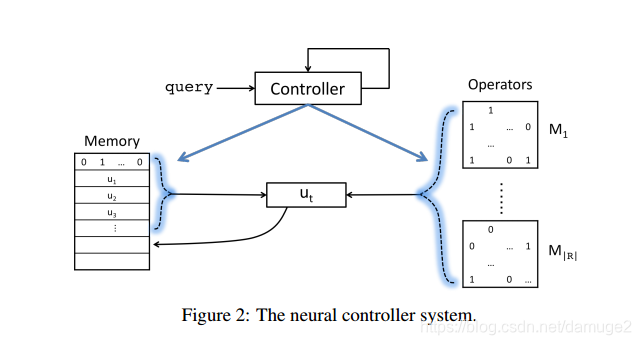
实验
- 统计关系学习
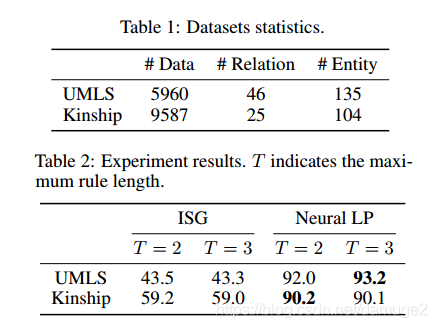
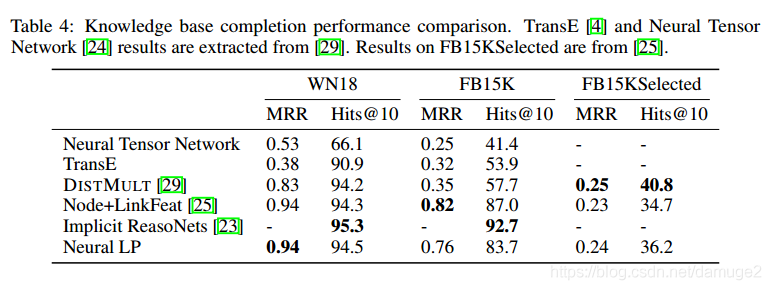
统计指标是hits@10
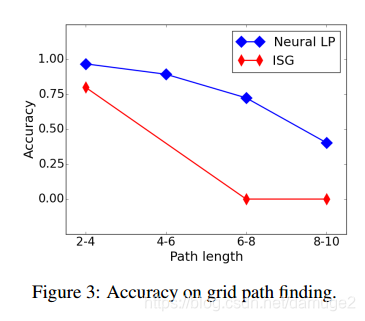
2.网格路径寻找
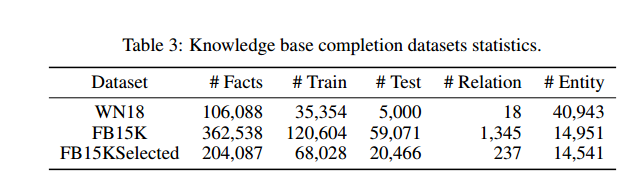
3. 知识图谱补全
代码

- Reasoning With Neural Tensor Networks for Knowledge Base Completion
- End-to-End Learning of Geometry and Context for Deep Stereo Regression
- Deep Learning of Binary Hash Codes for Fast Image Retrieval
- 图像检索系统《Deep Learning of Binary Hash Codes for Fast Image Retrieval》
- 快速图像检索(Deep Learning of Binary Hash Codes for Fast Image Retrieval)
- matlab 出现Undefined function 'functionname' for input arguments of type 'logical'问题的解决办法
- Joint Learning of Convolutional Neural Networks and Temporally Constrained Metrics for Tracklet Asso
- 立体匹配——End-to-End Learning of Geometry and Context for Deep Stereo Regression
- 图像检索系列一:Deep Learning of Binary Hash Codes for Fast Image Retrieval
- Remote Debugging of Loadable Kernel Modules with kgdb: a Knowledge-based Article for Getting Started
- Deep Learning of Binary Hash Codes for Fast Image Retrieval 代码编译
- 1607.CVPR-Joint Learning of Single-image and Cross-image Representations for Person ReID 论文笔记
- 解密谷歌机器学习工程最佳实践——机器学习43条军规 翻译 2017年09月19日 10:54:58 98310 本文是对Rules of Machine Learning: Best Practice
- Densely-Connected Deep Learning System for Assessment of Skeletal Maturity
- A Large set of Machine Learning Resources for Beginners to Mavens
- The NOTE of learning ASP.NET [6] 关于 .NET BCL(Base Class Library,基础类库)
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- [EMNLP2017]Context-Aware Representations for Knowledge Base Relation Extraction
- state of the art result for machine learning problems
- 【软件分析与挖掘】A Comparative Study of Supervised Learning Algorithms for Re-opened Bug Prediction