Python爬虫 --爬取京东商品信息
2019-02-23 11:42
183 查看
本次学习的爬取内容是京东商品列表信息
网址是:https://search.jd.com/Search?keyword=手机&enc=utf-8
使用了第三方库 requests
因为京东每一页的商品信息被分为前30件商品和后30件商品信息,所以将分为两部分爬取
第一步:
获取页面前30件信息
利用开发者工具查看headers信息
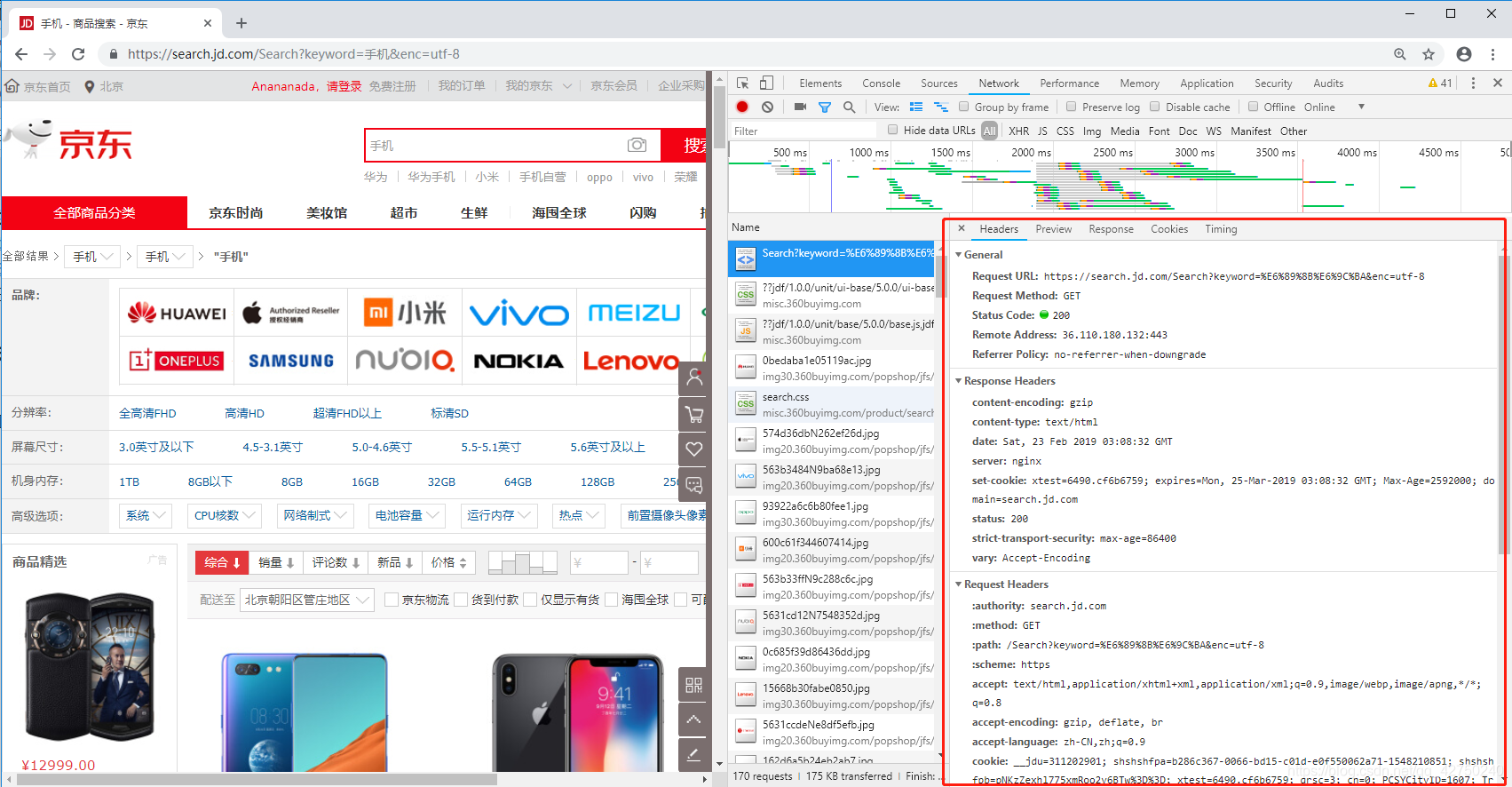
# 构造headers信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
下面对url的观察发现可改变page参数还获取不同的界面
对于防爬处理:requests请求的时候控制了访问时长
page = 2 * s - 1
url = 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page={}&s=115'.format(
page)
# 请求访问
try:
time.sleep(random.randint(0, 3)) # 控制访问速度
response = requests.get(url, headers=headers)
except RequestException:
print('请求前30失败')
exit()
请求成功后可以获取网页字符串再用re提取所需要的信息


用正则提取信息
try:
res = re.findall(
'<strong class="J_([\d]{1,15})" data-done="1"><em>¥</em><i>(\d{1,5}\.\d{2})</i></strong>.*?<em>([^¥].*?)</em>',
response.text, re.S)
return res
except:
return None
第二步:
获取页面后30件商品信息
同样也是利用开发者工具找到商品信息

尝试了很多次的访问这个网页,需要构造的headers信息有

另外对于url的观察后发现需要更改三个参数才可以获取数据
# 设置变化参数
page = 2 * s
shijian = '%.5f' % time.time()
n = 48 * s - 20
url = 'https://search.jd.com/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page={}&s={}&scrolling=y&log_id={}'.format(
page, n, shijian)
requests成功获取后30件商品信息后,对于信息的提取跟前30件商品一样的,这里就不展示了
第三步:
对数据处理和存储

如发现可以改进的地方或者哪里做得不好,希望大家能够提出多多交流。

相关文章推荐
- 利用Python爬虫爬取京东商品的简要信息
- python爬虫(三)selenium爬取京东商品信息
- Python爬虫二:抓取京东商品列表页面信息
- python爬虫(7)——获取京东商品评论信息
- python爬虫实战(一)----------爬取京东商品信息
- 京东商品信息及其价格爬虫
- Python爬虫(一)京东商品价格及详情页抓取
- Python爬虫实战(2):爬取京东商品列表
- 详细教程 :crawler4j 爬取京东商品信息 Java爬虫入门 crawler4j教程
- Python爬虫技术干货,教你如何实现抓取京东店铺信息及下载图片
- python爬取京东商品信息
- Java爬虫系列之一HttpClient【爬取京东Python书籍信息】
- python制作爬虫爬取京东商品评论教程
- Java多线程爬虫爬取京东商品信息
- Python批量获取京东商品列表信息
- python爬虫爬取淘宝商品信息(selenum+phontomjs)
- Python批量获取京东商品列表信息
- python爬虫(6)——获取天猫商品评论信息
- 基于selenium和requests的京东商品信息和评论爬虫
- Python爬虫模拟登录京东获取个人信息