大数据构建模块:选择体系结构和开源框架
场景:Twitter情感分析
许多客户使用社交媒体来谈论产品和服务。Twitter也不例外。充满意见的推文可以传播,并极大地影响您的产品(和公司)的声誉。因此,在我们的示例场景中,让我们假设我们是一家区域性零售公司。我们希望实时跟踪和分析Twitter帖子,以便我们在必要时采取行动,表达我们对积极反馈的欣赏,并迅速减轻客户的不满。
问题:我们有许多产品和服务,并且在所有业务部门中,我们的客户每周七天,每小时生成100,000条推文。
业务目标:一种简单,自动化的方式来理解社交情绪,以便在问题升级之前解决问题。
解决方案要求:实时社交媒体监控,横向扩展以适应未来增长,以及实时汇总和警报系统,用于ping客户成功/运营团队(基于特定标准)。
我们将使用什么
将从Twitter API订阅和提取数据的实时订阅者。
消息队列。
文本解析器,可将推文调整为我们的情绪分析引擎可以使用的格式,以及添加喜欢,转发等元素。
情绪分析引擎将评估推文“感觉”并返回其情绪(正面/负面)。
分数引擎将从情绪分析引擎和解析器接收数据,运行定义推文严重性的算法并评估是否向我们的团队发出警报。
将存储我们的数据的数据库,服务层将使用该数据实时传输到仪表板。
通用架构选项
Kappa架构由消息队列,实时处理层和服务层组成。它专为并行处理和异步或同步管道而设计。
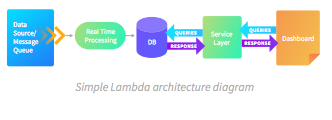
Lambda架构类似于Kappa,有一个额外的层,即批处理层,它根据产品需求组合所有摄取数据的输出。在我们的示例中,服务层负责创建我们的仪表板视图,其中我们将来自实时处理和批处理输入的输出组合在一起,以创建包含来自两者的见解的视图。
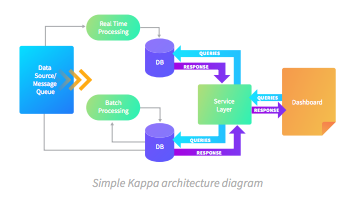
我们的解决方案选择:Kappa架构
由于需要维护批处理和实时处理代码库,Lambda架构可能有些复杂。由于我们希望从简化的解决方案开始,我们将使用Kappa架构选项。
我们的目标:
最小延迟:尽快评估新推文(即几秒钟)。
高吞吐量:并行消化许多推文。
水平可扩展性:适应负载增加。
集成:允许系统中的不同组件与其他系统集成,例如警报系统,Web服务等。这将有助于我们评估架构的未来变化以支持新功能。
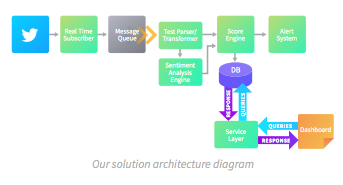
我们的决策过程
对于实时订户,云中存在许多商业产品(例如Azure Logic Apps)和内部部署。警报系统也是如此。一种选择是Graphite,它与Grafana配合得很好。虽然这两个很受欢迎,但我们应该使用普罗米修斯。Prometheus对我们来说效果更好,因为它提供了开箱即用的完整警报管理系统(Graphite和Grafana缺乏),以及数据收集和基本可视化。
至于我们的消息队列,有多个产品(例如RabbitMQ,Apache ActiveMQ和Apache Kafka)。许多框架,如Apache Spark和Apache Storm,都与Kafka内置集成。我们选择Kafka的可扩展性,高吞吐量,易于集成和社区支持。最重要的是,Kafka Stream客户端支持各种编程语言,这减少了专用编程语言的学习曲线。
我们的文本解析器,情感分析引擎和得分引擎可以使用Apache Storm或Apache Spark Streaming构建。Apache Storm专注于流处理,执行任务并行计算,并且可以与任何编程语言一起使用。Apache Spark包含一个内置的机器学习库MLlib,这可以帮助我们的情绪引擎。但Spark Streaming以微批处理数据,这可能会限制延迟功能。鉴于此,由于MLlib不支持所有机器学习算法,我们选择使用Apache Storm。使用Storm作为流层,我们可以将每个推文作为一个任务处理,最终比使用数据并行驱动的Spark更快。这符合我们的可扩展性,低延迟和高吞吐量目标。
最后,我们需要评估我们的数据库选项。由于我们希望在仪表板上实时查看我们的分析摘要,因此我们将使用像Redis这样的索引内存数据库来加快查询速度并减少延迟。
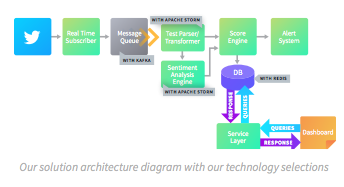
值得注意的是,我们的架构设置允许更改。随着我们的系统开发并添加统计功能,我们可以添加批处理层,将Kappa架构转换为Lambda架构。该架构还支持从各种社交网络添加多个输入,如LinkedIn。如果您将来很有可能添加批处理层,请考虑使用Apache Spark而不是Apache Storm。这样,您将为流和批处理维护一个框架。
大数据景观概览:概述和考虑
Apache Kafka提供统一,高吞吐量,低延迟的平台,用于处理实时数据馈送,大多数云支持托管Kafka。Kafka还提供Kafka Stream用于流应用程序,以及Kafka Connect,我们可以使用它创建一个数据库连接器,从Kafka读取数据并将其写入所需的数据库,如PostgreSQL,MongoDB等。Kafka提供有序,持久和可扩展的消息传递系统,支持微服务,并拥有蓬勃发展的开源社区 - 使其成为极受欢迎的消息队列框架。
Redis是一个开源的内存数据结构项目,它实现了一个具有可选持久性的分布式内存键值数据库。Redis支持不同类型的抽象数据结构,例如字符串,列表,映射,集合,有序集,HyperLogLog,位图,流和空间索引。在StackOverflow 2018开发人员调查中,Redis被列为开发人员“最喜爱的数据库”,但重要的是要注意Redis不支持加入操作或开箱即用的查询语言。您还需要学习Lua来创建自己的存储过程; 学习过程更长,也许更难。
Apache Spark是一种开源的分布式通用集群计算框架,最常用于机器学习,流处理,数据集成和交互式分析。Spark Streaming构建于Apache Spark之上。它是一个可扩展的容错流处理系统,可以本地支持批处理和流式工作负载,并为图形和机器学习库提供开箱即用的支持。Spark相对简单易懂,速度极快,并且拥有广泛的社区支持。
Apache Storm是一种主要以Clojure编程语言编写的分布式流处理计算框架。通常与Spark Streaming相比,Storm专注于流处理并执行任务并行计算。Storm经常与Kafka一起使用,其中Storm处理数据,Kafka用于事件流或消息总线。Storm在云中拥有巨大的支持,并且可以与任何编程语言一起使用,因为通信是基于JSON的协议。当前适配器存在于Python,Ruby,JavaScript,Perl等中。

- 软件体系结构之框架的选择及说明
- ABP框架的体系结构及模块系统讲解
- ABP框架的体系结构及模块系统讲解
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
- 想学大数据?大数据处理的开源框架推荐
- 一个开源的IoC采集服务器体系结构设计
- spring framework体系结构及内部各模块jar之间的maven依赖关系[即spring引入所需要的所有jar包]
- 测试驱动开发TDD(三)开源测试框架的选择
- 物联网平台机智云Android开源框架入门之旅(一)认识框架结构,导入PK、APP的id和secret。
- 002医疗项目-主工程模块yycgproject三层构建(三大框架的整合)
- 应用SuperIO(SIO)和开源跨平台物联网框架ServerSuperIO(SSIO)构建系统的整体方案
- spring framework体系结构及内部各模块jar之间的maven依赖关系
- 8月9日云栖精选夜读:大数据时代_如何构建国家地质基础数据更新体系
- maven构建系统项目的结构的体系确定
- AI 从业者该如何选择深度学习开源框架
- 基于C#语言开发的IM系统--数据库结构图(通讯框架为networkcomms2.3.1)【即将开源】
- 章二 软件体系结构的构建模式(1)
- 系统体系结构-概念和框架
- 一个开源的IoC采集服务器体系结构设计
- 构建企业级项目管理体系(06)-PMO是否需要参与项目选择?