深入解析病毒(一)理论篇
猪年送安康,祝大家新一年健康、快乐。愿大家都做一个勤奋努力、真诚奉献的人,幸运会永远的眷顾你们。
引子:
某一天饶有兴趣在卡饭上浏览着帖子,故事的相遇就那么简单。当时一条评论勾起我的好奇心,那么好逆向开始。
根据我的习惯,拿到样本我会线上恶意代码分析,直接拉到virustotal之类的网站上,看看是否已经被大多数杀毒软件所能识别,看一些有价值的数据,如下图所示:
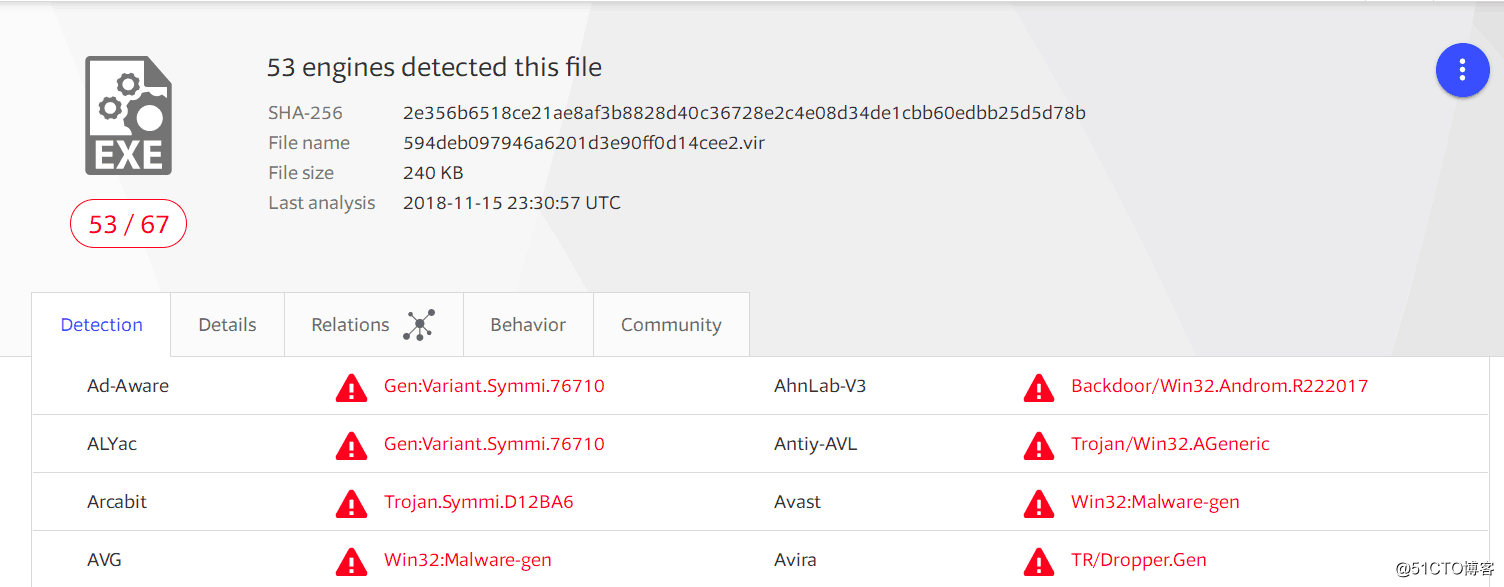
图片一:基本信息
当看到这个页面时候,看到最后的分析日期是18年11月,又看了一下导出表的函数信息,是一款老病毒。根据各大厂商对这个病毒行为特性、分析定位为特洛伊、伪装等,定位不一很正常......,其实兴趣降低了一大半,并不是新鲜品种,但不能这样侮辱一个病毒!接着习惯性拉入到IDA中,当我看到熟悉的汇编之后,如下图所示:
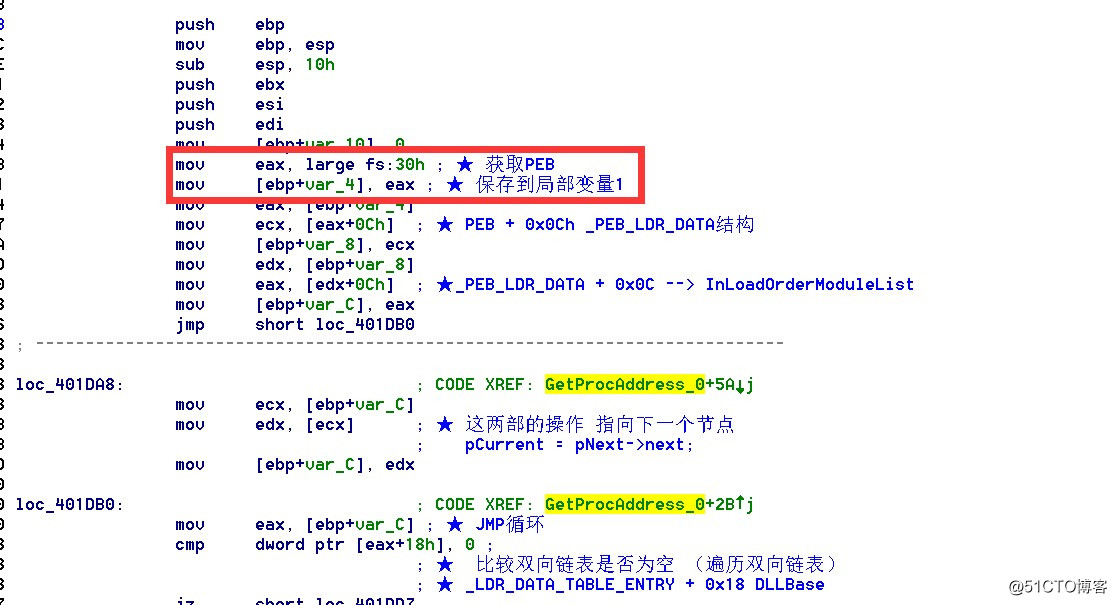
图片二:GetProcAddress实现
当点进去其中的一个函数,看到了fs寄存器,且一大堆比较复杂的操作,看到熟悉的汇编指令以后,心中已有定数,这是一个自己实现的GetProcAddress函数。
| 理论篇 | 汇编篇 | 逆向篇 |
|---|---|---|
| 定时器,保护模式,PE杂谈 | 手动实现GetProcAddress函数及Hash加密字符比对 | 逆向病毒 |
一、理论篇
先来看病毒样本中的一段代码,如下图所示:

图片三:CreateTimerQueueTimer
还记着以前分析熊猫烧香时候的定时器,如下图所示:
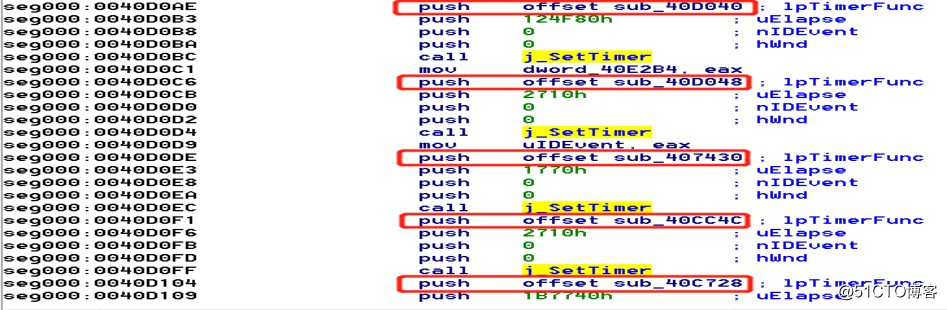
图片四:SetTimer
恶意代码大多都会利用到WinAPI提供的定时器操作,从而实现有规划、周期性的恶意代码,既然那么重要,所以我们先来聊聊那些定时器。
经常用ARK工具的朋友,应该都使用过遍历定时器相关的功能,有用户层定时器,IO定时器,DCP定时器,包括我们的时钟中断机制,都是具有定时器相关操作的。
我们先从用户层入手,windbg下深入分析一下上面提到的两个定时器操作,NtSetTimer汇编源码如下所示:
注:(为什么SetTimer会调用NtSetTimer,请看http://blog.51cto.com/13352079/2343452)
函数原型如下:
UINT_PTR SetTimer( HWND hWnd, // 窗口句柄 UINT_PTR nIDEvent, // 定时器ID,多个定时器时,可以通过该ID判断是哪个定时器 UINT nElapse, // 时间间隔,单位为毫秒 TIMERPROC lpTimerFunc // 回调函数 );
为了更好的理解定时器的汇编代码,简单分析一下函数调用的过程,就是如何获取当前线程。
kd> u PsGetCurrentProcess nt!PsGetCurrentProcess: mov eax,dword ptr fs:[00000124h] mov eax,dword ptr [eax+50h] ret
那么根据书籍或者相关资料,我们知道fs寄存器的值恒定(注意windows7 32位测试的),内核态是fs = 0x30,用户态 fs = 0x3B,fs在内核态指向_KPCR,用户态指向_TEB.。什么依据呢?凭什么说fs指向KPCR? 这里属于保护模式得内容,但是这里还是想与大家一起分享其中的原理,那么先说说段寄存器,为了方便理解做了一个简陋的图,如下所示:
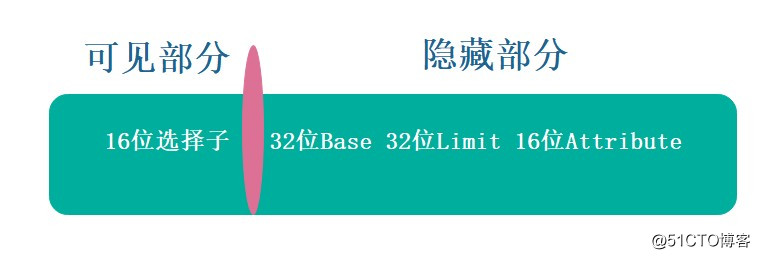
图片五:段寄存器
其实段寄存器共96位,只有其中的16位是可见的,剩余部分隐藏,可见的部分就是我们能查询到的立即数,也叫做选择子。隐藏部分只可以被CPU操作,不可以使用指令进行操作。
GDT全局描述符表,系统中按照不同的属性、类型进行描述,所以这些描述符统一存储到内存中,并且形成了一个数组,这就是GDT。全局描述符的索引保存在了可见部分16位的选择子中,这就是GDT与段选择子的关联。如何从选择子中知道索引呢?如下图所示:

图片六:选择子
高13位是索引号,也就是下标。TI = 0 代表GDT,TI = 1代表LDT。RPL是当前请求特权级别,权限检查会用到,这里不对权限检测做详细介绍。
清楚了上面的知识后,我们分析一下内核态fs = 30,16位选择子内容,如下图所示:

图片七:解析fs寄存器
通过上述分解,我们知道了fs在GDT中的第六项(0开始),接着获取gdtr,并且获取段描述符的属性状态,如下图所示:
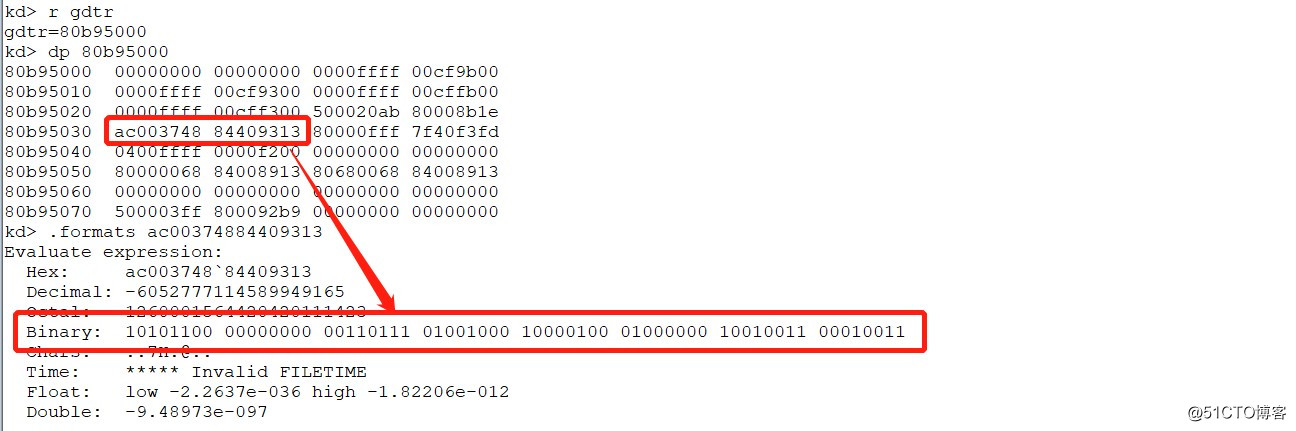
图片八:gdtr寄存器
段描述符如何来分解?段描述符都有那些属性呢?如下图所示:

图片九:通用描述符
介绍一些主要属性:
| L | D/B | P | S | DPL | TYPE | G |
|---|---|---|---|---|---|---|
| 64位代码段 | 默认操作大小 | 段有效值 | 描述符类型 | 描述符特权级别 | 段类型 | 粒度 |
我们按照上图分解,取Base Address,按照想对应的规则10101100 01001000 10000100 01000000进行地址拼接,其实这个就获取到了KPCR的结构。
fs寄存器其实拥有那么的数据量,本质是是从结构数据中获取,便于操作。推荐一下bochs这款x86硬件平台的开源模拟器,学习保护模式,除了书中获取相关知识以外,还可以多多阅读源码,才能更深层的学习理解。
回到主题,我们既然知道fs在内核态指向的是什么了,我们观察一下fs:[00000124h]是什么?结构体相关内容以前介绍过,这里不罗嗦,如下图所示:
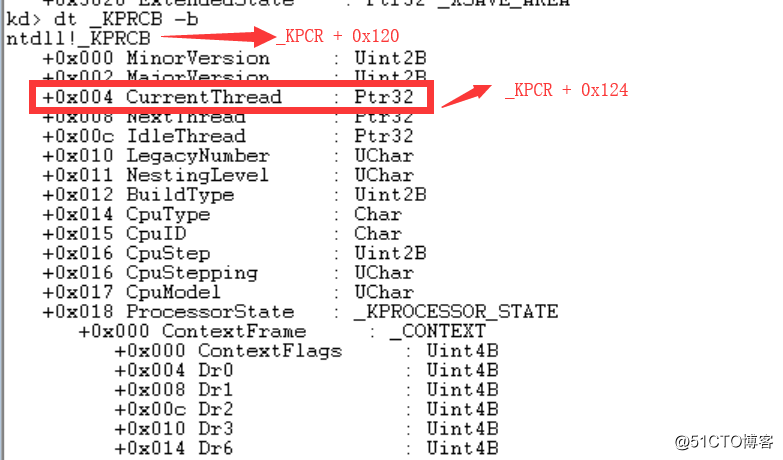
图片十:_KPRC
fs寄存器内核态指向的是_KPRC,fs:[0x124]指向CurrentThread(_EPROCESS),有了这些基础以后,我们继续分析NtSetTimer得调用过程。
NtSetTimer汇编代码:(因为排版 所以就上图了)
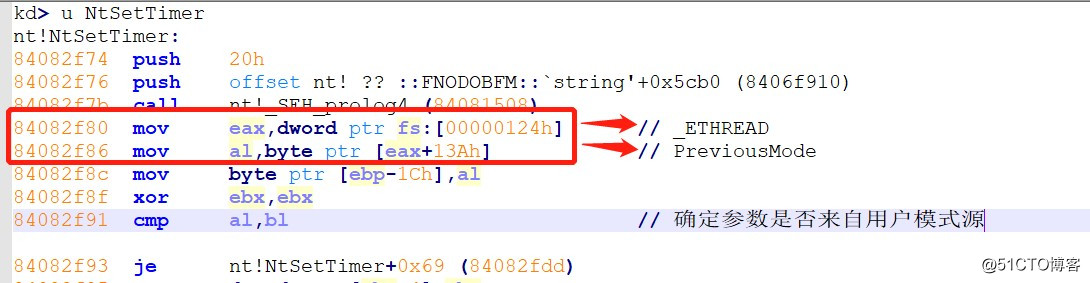
图片十一:NtSetTimer解析1
如上图所示,先是获取_ETHREAD,然后获取了ETHREAD+0x13a(Previous Mode),如下图所示:
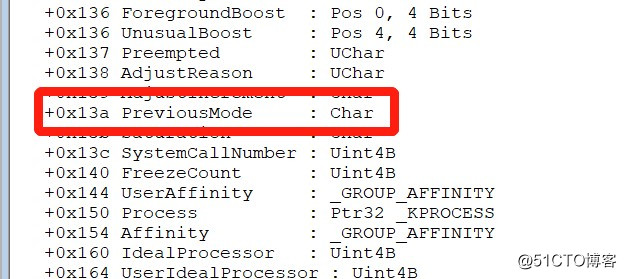
图片十二:
什么是Previous Mode?,简单来说调用Nt或Zw版本时,系统调用机制将调用线程捕获到内核模式,判定参数是否来源于用户模式标志。
The native system services routine checks the PreviousMode field of the calling thread to determine whether the parameters are from a user-mode source.
详细得内容介绍参考:https://msdn.microsoft.com/zh-cn/windows/desktop/ff559860
PreviousMode其中得两个状态值:
1、UserMode 状态码是1
2、KernelMode 状态码是0
所以上图中与0进行判断,判断当前是否内核态,是则跳转0x8402fdd。我们先来看看如果是内核态,是怎样一条执行路线,如下图所示:

图片十三:定时器ID判定
第二个参数必须大于等于0,否则会抛出异常,继续看,如下图所示:

图片十四:内核态汇编解析
OD中我们跟中一下看是否真的追加了第五个参数,如下图所示:

图片十五:NtUserSetTimer
如果为0则跳转,跳转位置如下图所示:


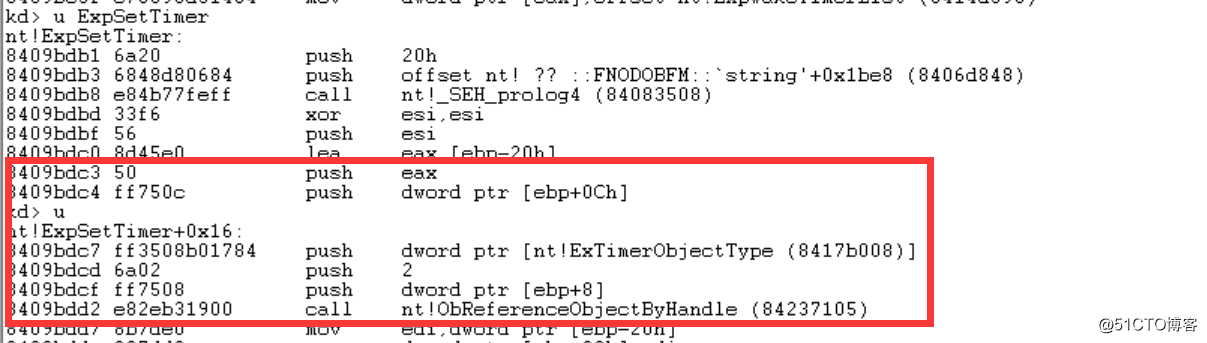
图片十六:ExpSetTimer
我们会发现,SetTimer->NtUserSetTimer->Wow64得函数(如果32位运行在64位)-->KiFastSystemCall->ExSetTimer-->ObReferenceObjectByHandle-->..........
所以SetTimer在内核态得过曾还是比较复杂得,大家可以通过函数栈来观察到底如何运作得,这告诉我们一个道理,谁HOOK得函数越底层,谁就有可能做更多得事情。
如果Previous Mode = UserMode呢?如何执行?如下图所示:
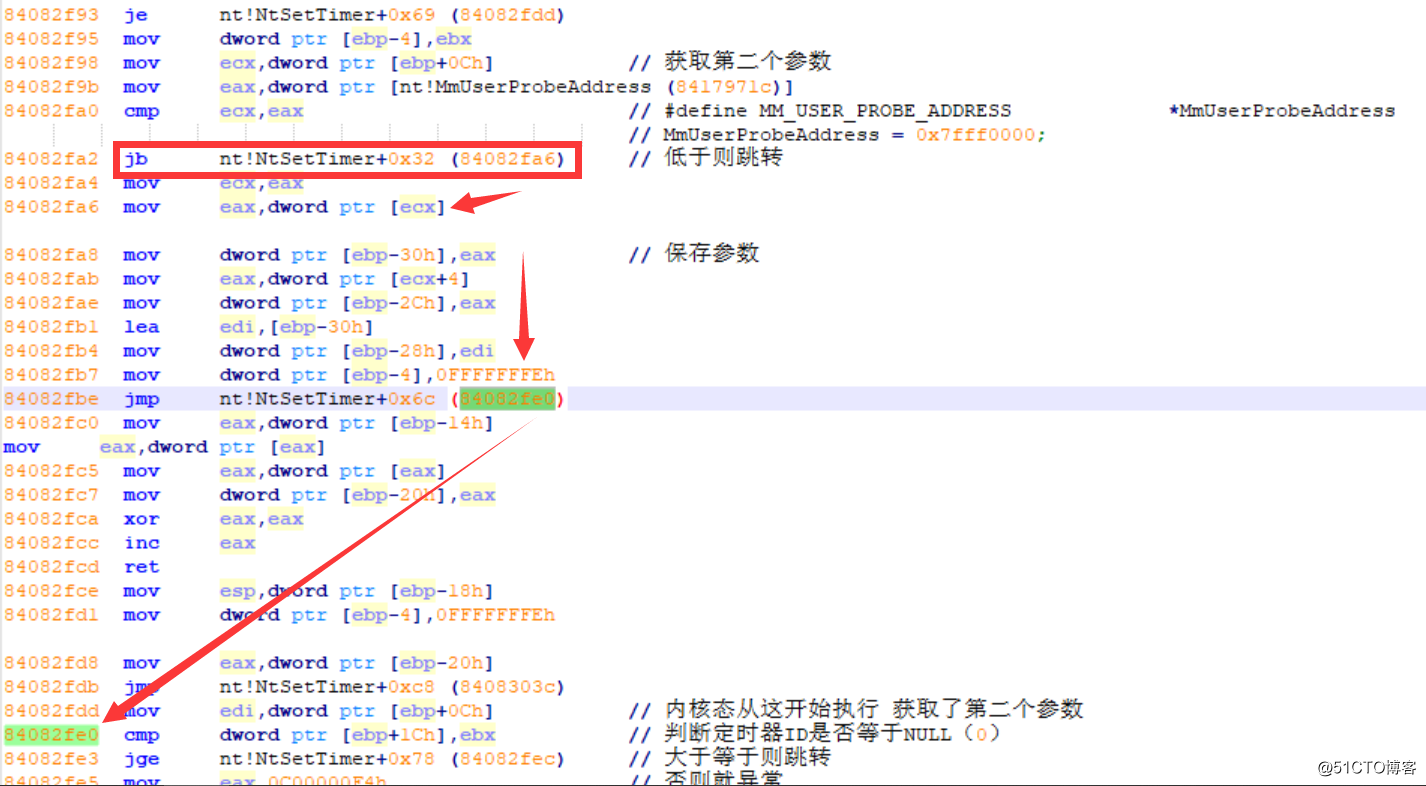
图片十七:用户态汇编分析
在做了一些判断赋值及参数保存操作以后,又跳回了与内核态执行得流程,所以说不论怎样最终还会调用那些函数。
关于SetTimer函数简单得分析到这里,我们下面接着看CreateTimerQueueTimer函数,先来看函数原型:
BOOL WINAPI CreateTimerQueueTimer( _Out_ PHANDLE phNewTimer, _In_opt_ HANDLE TimerQueue, _In_ WAITORTIMERCALLBACK Callback, _In_opt_ PVOID Parameter, _In_ DWORD DueTime, _In_ DWORD Period, _In_ ULONG Flags ); 图三中已经对参数进行了详细得介绍,这里不再做介绍
OD中我们动态观察一下,如下图所示:
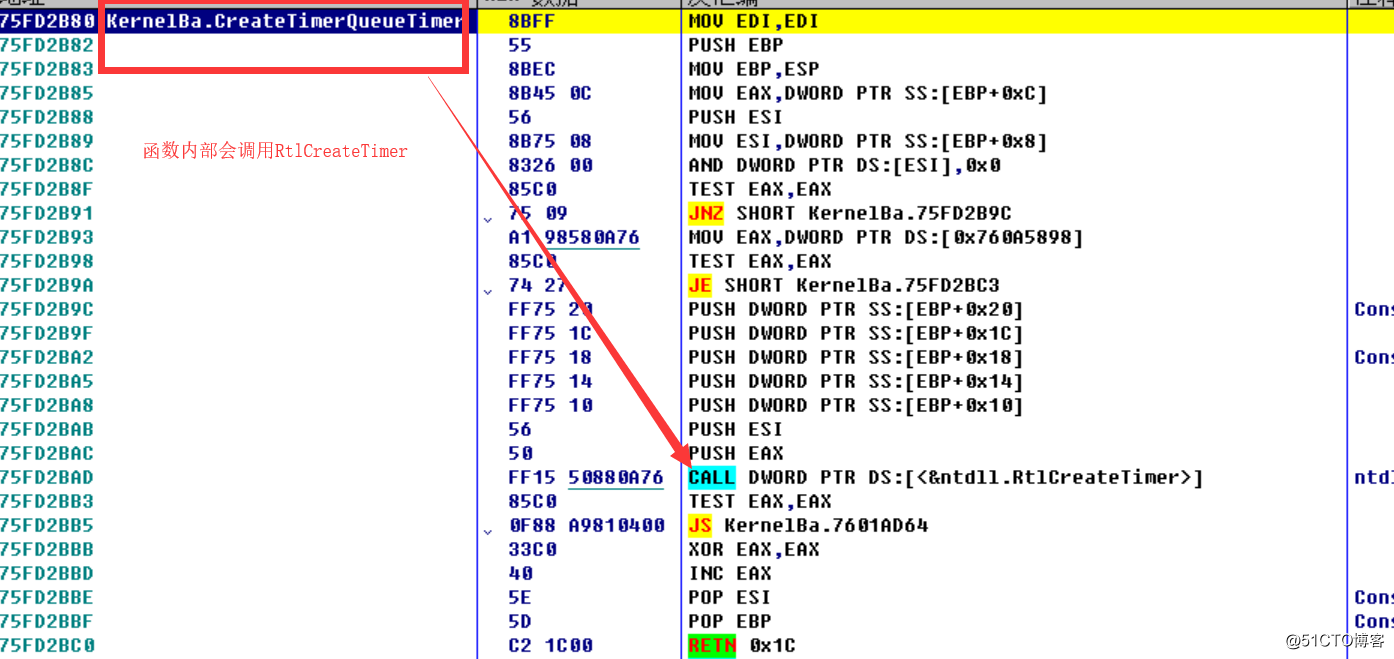
图片十八:CreateTimerQueueTimer
函数内部调用了RtlCreateTimer,我们继续动态跟踪,如下所示:
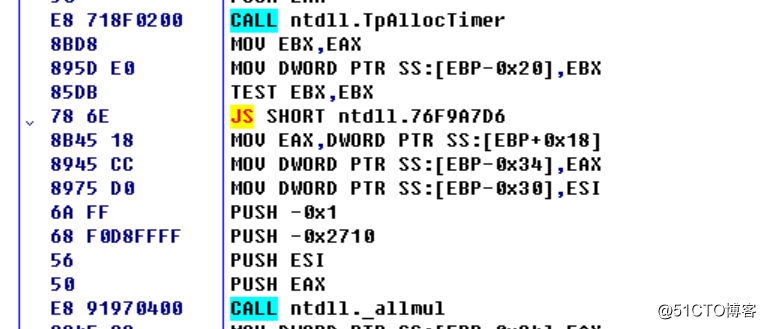
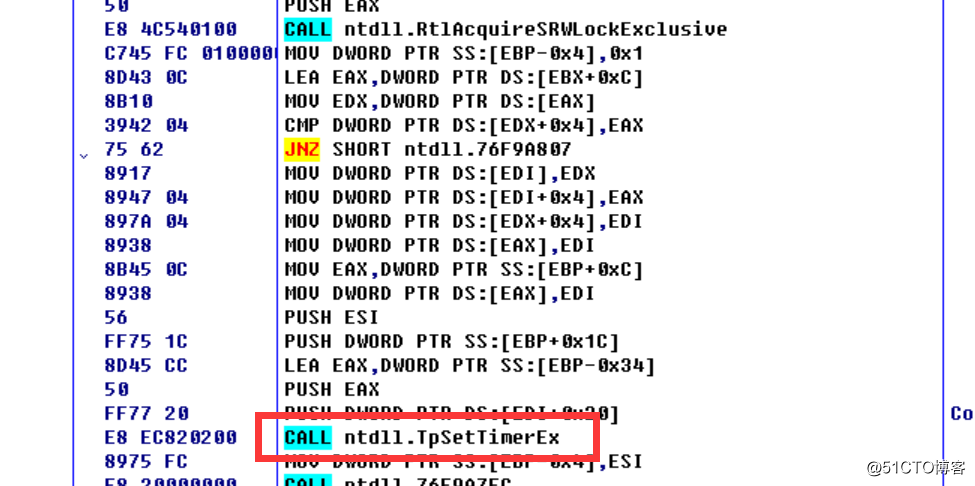
内部调用了大量的函数,其中包括TpSetTimer也在其中,基本确定内部是调用TpSetTimer来实现该函数功能,在windbg中简答了分析一下,内部调用了TppTimerpSet,且使用了Slim读写锁机制,因为触碰到了盲区,感觉不太准确,也找不到相关的参考所以有兴趣的朋友可以深入分析一下,这里就不讲解了。
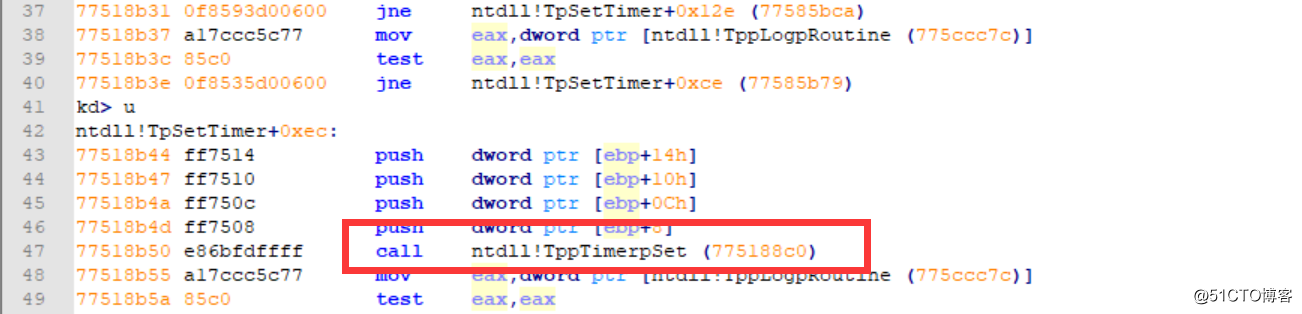
图片十九:TppTimerpSet
这里以上是给大家提供一些函数分析的思路罢了,有时间的话写一篇相关的话题一起讨论一下。
PE杂谈 :
关于PE知识虽然看起来杂乱,但还是比较有序的。PE涉猎的范围较广,PE文件是指一种格式,如可执行文件、动态链接库、驱动等等,都属于PE格式的文件。
想深入学习的朋友,推荐一本书籍《Windows PE权威指南》,里面内容是win32汇编撰写而成。
我们这里只对用到的基本知识和导出表做介绍,PE结构体大概分为几个部分,如下图所示:

图片二十:PE大体结构
上面顺序是一定的,PE是一个有序结构,标准的PE格式每个结构体对应的偏移是固定的,当然也有很多恶意代码会对PE结构体进行数据压缩等技术,达到隐匿、免杀的目的。
我们介绍一下DOS头的数据介绍,其实我们用VS编程的时候就可以获取到结构体,这里不再windbg下获取了,如下所示:
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
上面结构体是DOS头部的全部信息,其中DOS中两个重要属重点介绍一下:
| e_magi |
|---|
| “魔术”标志,判断是否PE格式第一道防线,恒定值为0x4D5A(MZ) |
| e_lfanew |
|---|
| Dos头与NT头之间有一部分Dos Stub的数据(Dos的数据)大小不确定,意味着NT头偏移不确定,所以 e_lfanew记录了该模块NT的偏移 |
如何找到NT头?模块基址 + e_lfanew = NT的位置。第二部分我们会用汇编获取且深入学习,用C/C++如何实现呢?如下代码所示:
// 1.获取PE格式文件
m_strNamePath = PathName;
// 2.打开文件
HANDLE hFile = CreateFile(PathName, GENERIC_READ | GENERIC_WRITE, FALSE, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
if ((int)hFile <= 0){ AfxMessageBox(L"当前进程有可能被占用或者意外错误"); return FALSE; }
HANDLE hFile = NULL;
// 3.获取文件大小
DWORD dwSize = GetFileSize(hFile, NULL);
// 4.申请堆空间
PuPEInfo::m_pFileBase = (void *)malloc(dwSize);
memset(PuPEInfo::m_pFileBase, 0, dwSize);
DWORD dwRead = 0;
OVERLAPPED OverLapped = { 0 };
void* pFileBaseAddress = nullptr;
// 5.读取文件到内存
int nRetCode = ReadFile(hFile, pFileBaseAddress, dwSize, &dwRead, &OverLapped);
// 6.转换成DOS头结构体
PIMAGE_DOS_HEADER pDosHander = (PIMAGE_DOS_HEADER)pFileBaseAddress;
// 7.Dos起始地址 + e_lfanew = NT头
PIMAGE_NT_HEADERS pHeadres = (PIMAGE_NT_HEADERS)(pDosHander->e_lfanew + (LONG)pFileBaseAddress);
如上述代码,获取可执文件路径,创建(获取文件句柄)、打开文件、读取文件大小、申请堆空间、读取文件数据到内存(加载到了内存)、获取NT头,第7步正式上述所表达的 模块基址 + e_lfanew。
NT头内部是如何?如下所示:

图片二十一:NT结构
如上所示,NT分为三部分,介绍如下:
| Signature | FileHeader | OptionalHeader |
|---|---|---|
| 标记,判断是否PE格式第二道防线,恒定值为0x4550(PE) | 文件头,存储这PE文件的基本信息 | 存储着关于PE文件的附加信息 |
既然已经介绍了PE格式两条应规定,两道标杆,如果判断是否是一个PE格式的文件呢?如下代码所示:
//判定是否是PE文件
BOOL IsPE(char* lpBase)
{
PIMAGE_DOS_HEADER pDos = (PIMAGE_DOS_HEADER)lpBase;
if (pDos->e_magic != IMAGE_DOS_SIGNATURE/*0x4D5A*/)
{
return FALSE;
}
PIMAGE_NT_HEADERS pNt = (PIMAGE_NT_HEADERS)(pDos->e_lfanew + lpBase);
if (pNt->Signature != IMAGE_NT_SIGNATURE/*0x4550*/)
{
return FALSE;
}
return TRUE;
}
FileHeader结构体如下:
// File header format.
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
| Machine | NumberOfSections | TimeDateStamp | NumberOfSymbols |
|---|---|---|---|
| 文件运行平台 | 区段的数量 | 文件创建时间 | 符号个数 |
| SizeOfOptionalHeader | PointerToSymbolTable | Characteristics |
|---|---|---|
| 扩展头大小 | 符号表偏移 | PE文件属性 |
补充:
1、Machine:0x014c代表i386,平时intel32为平台,0x0200表示Intel 64为平台。
2、NumberOfSymbols:这个很重要了,你遍历节表先要获取数量,这个就是。
3、Characteristics:PE的文件属性值,如下所示:
| 数值 | 介绍 | 宏定义 |
|---|---|---|
| 0x0001 | 从文件中删除重定位信息 | IMAGE_FILE_RELOCS_STRIPPED |
| 0x0002 | 可执行文件 | IMAGE_FILE_EXECUTABLE_IMAGE |
| 0x0004 | 行号信息无 | IMAGE_FILE_LINE_NUMS_STRIPPED |
| 0x0008 | 符号信息无 | IMAGE_FILE_LOCAL_SYMS_STRIPPED |
| 0x0010 | 强制性缩减工作 | IMAGE_FILE_AGGRESIVE_WS_TRIM |
| 0x0020 | 应用程序可以处理> 2GB的地址 | IMAGE_FILE_LARGE_ADDRESS_AWARE |
| 0x0080 | 机器字的字节相反的 | IMAGE_FILE_BYTES_REVERSED_LO |
| 0x0100 | 运行在32位平台 | IMAGE_FILE_32BIT_MACHINE |
| 0x0200 | 调试信息从.DBG文件中的文件中删除 | IMAGE_FILE_DEBUG_STRIPPED |
| 0x0400 | 如果文件在可移动媒体上,则从交换文件复制并运行。 | IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP |
| 0x0800 | 如果在网络存储介质中,则从交换文件中复制并运行。 | IMAGE_FILE_NET_RUN_FROM_SWAP |
| 0x1000 | 系统文件 | IMAGE_FILE_SYSTEM |
| 0x2000 | DLL文件 | IMAGE_FILE_DLL |
| 0x4000 | 单核CPU运行 | IMAGE_FILE_UP_SYSTEM_ONLY |
| 0x8000 | 机器字的字节相反的 | IMAGE_FILE_BYTES_REVERSED_HI |
OptionalHeader结构体介绍:
typedef struct _IMAGE_OPTIONAL_HEADER {
//
// Standard fields.
//
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
//
// NT additional fields.
//
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
挑重点介绍一下:
| Magic | AddressOfEntryPoint | BaseOfData |
|---|---|---|
| 标志一个文件什么类型 | 程序入口点RVA | 起始数据的相对虚拟地址(RVA) |
| ImageBase | SizeOfImage | SizeOfHeaders |
|---|---|---|
| 默认加载基址0x400000 | 文件加载到内存后大小(对齐后) | 所有头部大小 |
| NumberOfRvaAndSizes | DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES] | SizeofStackReserve |
|---|---|---|
| 数据目录个数(一般是0x10) | 数据目录表 | 栈可增长大小 |
补充:
1、文件中的数据是0x200对齐的(FileAlinment),内存中是以0x1000对齐的(SectionAlignment),对齐什么意思?打个比方,假如从0开始,数据只占用了0x88字节,那么下一段数据会在0x200开始,中间填充0。
2、DataDirectory这是一个数组,IMAGE_NUMBEROF_DIRECTORY_ENTRIES = 16。所以共有16项,每一项对于整个执行程序来说都有特殊的意义,当然不是每个程序每一项数据表都有内容。下面我们介绍的导出表,便是这16项中的第1项,下标为0。
那么DataDirectory是什么样结构呢?如下所示:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
每一个数组都保存了这样的一个结构体指针,VirtualAddress是什么?就是相对虚拟地址RVA,而Size意味着数据的大小。
术语介绍:
**虚拟地址**: 在一个程序运行起来的时候,会被加载到内存中,并且每个进程都有自己的4GB,这个4GB叫做**虚拟地址**,由物理地址映射过来的,4GB的空间,并没有全部被用到。 **物理地址**:在物理内存中存在的地址。在windows中是没有表现出来的,因为windows使用了保护模式。 **所有的数据都存储在了相应的区段(节)**,rdata存储只读数据,data存储的全局数据,text存储的代码,rsrc存储的是资源。 **入口点(OEP)**:他保存的是一个 **RVA** ,然后使用 OEP + Imagebase == 入口点的VA,通常情况下,OEP指向的不是main函数,是一个用于初始化(实际加载地址) **加载基址**:默认由PE文件指定,但是通常开启随机基址后,它的位置是由系统指定的 **镜像大小**: 就是exe在文件中展开之后的大小, = 最后一个区段的RVA + 最后一个区段的size 再按照0x1000对齐。 **代码/数据基址**:第一个代码区段和第一个数据区段的RVA **虚拟地址(VA)**:在进程4GB中所处的位置。 **相对虚拟地址(RVA)**:相对于内存(映像)中<u>加载基址</u>的一个偏移, **文件偏移(FOA)**:相对于文件(镜像)起始位置的偏移。 **文件块对齐:** 0x200(512),一个区段在文件的大小必须是0x200的倍数 **内存块对齐:**0x1000(4kb),一个区段在内存中的大小必须是0x1000的倍数 **关系:** 数据段(有效数据长度是0x100) => 文件对齐 => (0x200) => 映射到内存 => 0x1000 文件对齐力度和内存对齐力度可以自己改变,但是文件对齐力度必须不大于内存对齐力度 **标志字:**标识可运行的平台,x86,x64 **子系统**:窗口WinMain,控制台main **特征值**: 对应的是文件头中的Characteristics,标识当前模块有哪些属性(重定位已分离=>动态基址) **可选头的大小**:可选头有多少个字节,和操作系统的位数有关,x86/x64
节表就不再这里过多的介绍,说说导出表,也就是数据目录表的第1项,下标为0。
导出表是干什么的?PE文件导出的供其他使用的函数、变量等行为。当查找导出函的时候,能够方便快捷找到函数的位置。
看一看导出表的结构体,如下所示:
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
图片二十一:Export Format
| Characteristics | TimeDateStamp | MajorVersion | NumberOfFunctions |
|---|---|---|---|
| 保留值, 为0 | 时间 | 主版本号 | 函数数量 |
| MinorVersion | Name | Base | NumberOfNames |
|---|---|---|---|
| 次版本号 | PE名称 | 序号基数 | 函数名称数量 |
| AddressOfFunctions | AddressOfNames | AddressOfNameOrdinals |
|---|---|---|
| 函数地址表RVA | 函数名称表RVA | 函数序号表RVA |
补充:
导出表一般会被安排到.edata中,一般也都合并到.rdata中。上述中有三个字段分别是AddressOfFunctions,AddressOfNames和AddressOfNameOrdinals,对应着三张表,上面三个字段保存了相对虚拟地址,且有关联性,下面来看一下三个表的关联性,如下所示:
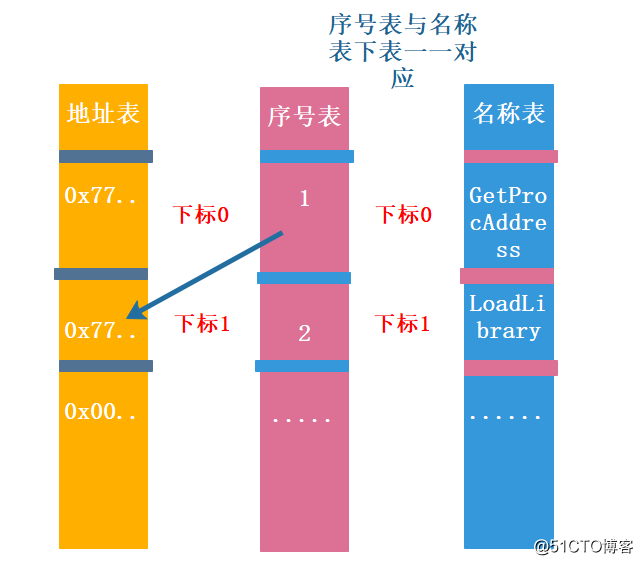
图片二十二:Table关联
如上图所示,序号表与名称表一一对应,下标与下标中存储的值是相关联的,这三张表设计巧妙,利用了关系型数据库的概念。
需要注意的是,序号不是有序的,而且会有空白。地址表中有些没有函数名,也就是地址表有地址却无法关联到名称表中,这时候用序号调用,序号内容加上Base序号基址才是真正的调用号,且注意序号表是两个字节WORD类型。
了解这三张表之后,C/C++代码实际应用获取一下,代码如下:
// lpBase就是读取文件申请的缓冲区(把文件读到内存后的首地址)
// 1. 找到导出表
PIMAGE_DOS_HEADER pDos = (PIMAGE_DOS_HEADER)lpBase;
PIMAGE_NT_HEADERS pNt =
(PIMAGE_NT_HEADERS)(pDos->e_lfanew + lpBase);
PIMAGE_DATA_DIRECTORY pDir =
&pNt->OptionalHeader.DataDirectory[0];
DWORD dwExportFOA = RVAtoFOA(pDir->VirtualAddress);
// 2. 导出表在文件中的位置
PIMAGE_EXPORT_DIRECTORY pExportTable =
(PIMAGE_EXPORT_DIRECTORY)
(dwExportFOA + lpBase);
printf("模块名称%s\n", (RVAtoFOA(pExportTable->Name) + lpBase));
// 3. 获取函数数量
DWORD dwFunCount = pExportTable->NumberOfFunctions;
// 3.1 获取函数名称数量
DWORD dwOrdinalCount = pExportTable->NumberOfNames;
// 4. 获取地址表
DWORD* pFunAddr =
(DWORD*)(RVAtoFOA(pExportTable->AddressOfFunctions) + lpBase);
// 5. 获取名称表
DWORD* pNameAddr =
(DWORD*)(RVAtoFOA(pExportTable->AddressOfNames) + lpBase);
// 6. 获取序号表
WORD* pOrdinalAddr =
(WORD*)(RVAtoFOA(pExportTable->AddressOfNameOrdinals) + lpBase);
// 7. 循环遍历
for (DWORD i = 0; i < dwFunCount; i++)
{
// 7.1 如果为0说明是无效地址,直接跳过
if (pFunAddr[i] == 0)
{
continue;
}
// 7.2 遍历序号表中是否有此序号,如果有说明此函数有名字
BOOL bFlag = FALSE;
for (DWORD j = 0; j < dwOrdinalCount; j++)
{
if (i == pOrdinalAddr[j])
{
bFlag = TRUE;
DWORD dwNameRVA = pNameAddr[j];
printf("函数名:%s,函数序号:%04X,函数序号:%04X\n",
RVAtoFOA(dwNameRVA) + lpBase,
i + pExportTable->Base);
}
}
// 7.3 如果序号表中没有,说明此函数只有序号没有名字
if (!bFlag)
{
printf("函数名【NULL】,函数序号:%04X\n", i + pExportTable->Base);
}
}
上述代码是对导出表进行的遍历,上述中也许有一些细节性的知识表达的不够到位,如果你能对以上的知识都很熟悉且汇编还不错,那么用汇编获取函数导出表也许对你来说是一件比较轻松的事情。
第二部分我们一起学习一下如何用汇编手动获取函数名称表及对应的函数地址(上面三张表关系一定搞清楚),用汇编实现自己的GetProcAddress,且Hash加密字符串进行与名称表进行对比,理论知识先告一段落。

- JDK的动态代理深入解析(Proxy,InvocationHandler)(转)
- register_chrdev 深入解析
- C++ 11学习和掌握 ——《深入理解C++ 11:C++11新特性解析和应用》读书笔记(一)
- 《Hadoop技术内幕深入解析Hadoop和HDFS》2.2 Configuration详解
- Javascript闭包深入解析及实现方法
- 玩转Google开源C++单元测试框架Google Test系列(gtest)之七 - 深入解析gtest
- 道不远人--深入解析ASP.NET 2.0控件开发 第12章前部分试读
- 深入解析浏览器的幕后工作原理
- 深入理解Nginx:模块开发与架构解析
- 深入解析CSS样式层叠权重值(转)
- equals&hashCode的深入解析
- 玩转Google开源C++单元测试框架Google Test系列(gtest)之七 - 深入解析gtest
- 深入解析FileInputStream和FileOutputStream
- 深入解析android 消息机制
- 项目——通过自动回复机器人学Mybatis(深入解析读取xml源码)(九)
- Linux Desktop Entry 文件深入解析
- 【读过的书,留下的迹】Spring技术内幕——深入解析Spring架构与设计原理
- 深入解析神秘的 --- 仿函数
- Android EventBus源码解析 带你深入理解EventBus
- 探索深入理解java虚拟机之java内存区域解析(1)