【学习笔记—Yolov3】Yolov3训练VOC数据集&训练自己的数据集
(一) yolov3训练voc数据集
1、下载安装darknet
依次执行如下三条命令
git clone https://github.com/pjreddie/darknet.git cd darknet make
此时,已经编译生成了darknet的可执行文件。
2、安装cuda和opencv
!!!注意:这一步只针对有GPU配置的电脑,如果没有GPU也可省略这一步。
当然,如果不安装cuda和opencv的结果就是不能测试video和webcam而已,训练速度慢一点而已。
关于opencv怎么安装,自行百度!这里默认cuda和opencv都安装成功了。
在darknet目录下,有一个makeFile文档,将里面的第一行和第二行把0改为1,若电脑安装了opencv则修改为1。

3、测试一下yolov3的效果
这时,需要去yolo官网下载一个yolov3.weights。这里给出下载命令:
wget https://pjreddie.com/media/files/yolov3.weights

可以看到,我的darknet目录下已经下载下了yolov3.weights权重。
此时就可以一睹yolov3的检测效果图啦!!!
终端下输入命令(注意一定是cd到darknet目录下操作啊啊):
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
OK继续,放检测结果图:

哈哈,不得不说,yolov3真的很强大,在tx2上一张图片的处理速度是0.X秒,在我教研室的服务器上是0.03秒左右,在我破电脑CPU上的速度竟然要20多秒,真的是要炸啊!!!
废话不多说,继续!下面才是博文的主题,训练voc数据。
4、在VOC上训练YOLO
- (1)下载VOC数据集并解压
下载VOC数据集,解压。 下载地址link,下载下来的目录是这样的:

voc2007也是一样的上面这样的。解压之后,我们在darknet目录下建一个VOCdevkit文件,里面包含VOC2007,VOC2012,VOC2007_test三个文件。
说明:下载下来的VOC2007测试数据集后将VOC2007文件名改为VOC2007_test,避免和voc2007训练集重名,然后一起放在VOCdevkie文件夹中。
下面是我的目录:

此时,VOC训练集就已经准备就绪了。进行下一步: - (2)修改voc_label.py中的代码
将scripts文件下的voc_label.py拷贝到darknet目录下,然后修改第7行,将最后一个元组改为(‘VOC2007_test’,‘test’)。
然后执行:
python voc_label.py
之后,在VOCdevkit/VOC2007等目录下就可以看到多了一个labels文件。在darknet目录下可以看到如下5个txt文件,分别为:
2007_val.txt
2007_train.txt
2007_test_test.txt
2012_val.txt
2012_train.txt
然后将上面2007和2012 的所有验证集和训练集合成一个大的训练集,终端下执行如下命令,完成。
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
这时,在darknet目录下,生成了一个tran.txt的文件。这就是后续训练的训练集txt文件。
剩下的2007_test_test.txt作为测试集。
-
(3)修改配置文件voc.data
修改darknet/cfg目录下的voc.data,主要是train 和valid后面的路径,改为自己的路径,这个就是上一步生成的train.txt 和2007_test_test.txt的位置。classes好像默认就为20不用改。backup是训练生成权重的位置,不用理会。下面是我的截屏:
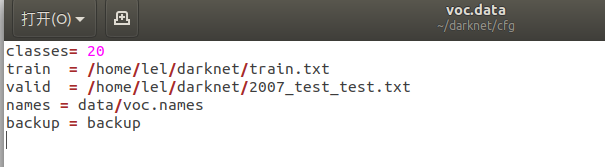
大家,对应修改即可。 -
(4)修改配置文件yolov3-voc.cfg
在darknet/cfg目录下,打开yolov3-voc.cfg文件,第默认的3、4行是Testing测试状态,训练时注释掉,将第6、7行training下的注释去掉。如下图:

如果电脑显存较小,则把batch该小,把subdivisions增大。例如改为32和16。 -
(5)下载预训练权重,训练
终端下执行如下命令 下载预训练权重:
wget https://pjreddie.com/media/files/darknet53.conv.74
训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
OK 到这里训练voc数据集就成功了,等两三天差不多就可以了。
写的忘乎所以,晚饭还没吃,好饿!
(二) yolov3训练自己的数据集
理解了上面的训练过程之后,训练自己的数据就很容易了。这里主要是针对交通场景训练可以识别person、car、Bus、motorcycle、bicycle共5类目标。对应修改配置文件即可,具体过程如下:
1、修改voc_label.py
将voc_label.py文件中的 classes 列表修改为自己的类别,我这里只是针对交通场景的5类目标为例。

之后,运行:
python voc_label.py
然后,链接voc2007和2012 的训练文件合成一个train.txt 训练文件。
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
这里的操作和上面的(一)中类似。
2、配置文件voc.names的修改
打开 data 文件夹下,有一个voc.names的文件,修改成你自己的类别,默认的是20类 voc 数据集的类别。我的是这样的:

修改完,保存即可。
3、配置文件yolo-voc.cfg的修改
在darknet下的cfg文件夹中,打开yolov3-voc.cfg网络结构文件,一共修改三处。
- (1)将测试状态改为训练状态
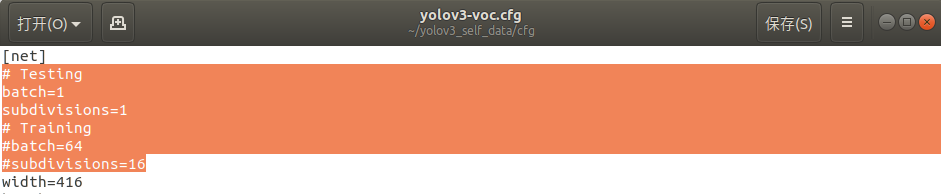
默认是测试状态,即上图所示。这里我们将Testing下下两行注释掉,同事将Training下的两行注释删掉。batch的大小可以根据自己电脑的显存大小适当修改,显存小的可以减少batch的值,增大subdivision的值。 - (2)修改 filters 的值
打开yolov3-voc.cfg文件之后,按住Ctrl+F打开搜索,输入yolo,可以发现一共有三处yolo层,即改网络结构的检测层。因为,yolov3的网络结构就是darknet53+yolo检测层组成的。
这里我们修改yolo 检测层前一层的 filters 的值大小。filters 大小利用如下公式计算:
filters = 3×(classes + 1 + 4) ,我这里5个目标,所以 filters 的值为30(注意一共需要改3处)。3代表的是多尺度预测,即yolov3是3次预测,所以乘以3。1代表的是置信度,4代表的是 boxes 的位置,即左顶点的坐标和长宽,四个参数。

- (3)修改 classes 的值
classes 的值就是自己检测的类别,Coco里是80种,voc数据集是20种。我这里针对交通场景只有5种。注意每一个yolo 层的 classes 值都要修改 ,一共也是三处。

4、配置文件voc.data的修改
cfg 文件夹下,打开 voc.data 文件,修改classes 的数值,改为你自己的类别数。修改train 和valid 的路径,也就是前面生成的 train.txt 训练集和voc2007_test_test.txt测试集的路径。
backup是生成权重的位置。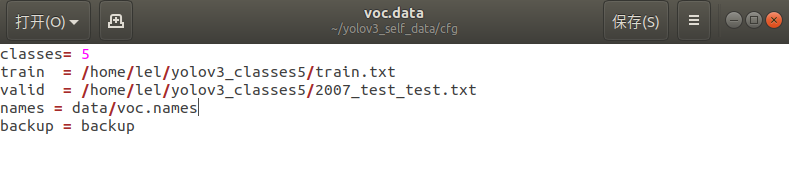
5、开始训练
终端下执行如下命令 下载预训练权重:
wget https://pjreddie.com/media/files/darknet53.conv.74
训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
到这里就完成了训练自己数据集过程了。
说明:这里都是对VOC数据集的操作,只训练自己的类别。当然也可以自己标注数据集来训练,这里推荐labelimg 标注工具,它标注的格式是xml, 我们可以利用voc_label.py 转换成yolo需要的 txt 格式。这都是可行的。
这里就不一一展示了,网上有很多labelimg的下载地址,使用也很简单。本质上和上面对voc数据集操作是一样的!

- caffe学习笔记6--训练自己的数据集
- 深度学习Caffe实战笔记(20)Windows平台 Faster-RCNN 训练自己的数据集
- Caffe学习笔记3——制作并训练自己的数据集
- caffe学习笔记(五)--使用自己的数据集第一次进行训练
- caffe学习笔记(十九)-训练和测试自己的数据集
- 【CNTK】CNTK学习笔记之制作自己的数据集(以MNIST手写数字数据集为例)
- YOLOv2训练自己的数据集(VOC格式)
- 【Darknet】【yolo v2】训练自己数据集的一些心得----VOC格式
- 【caffe学习笔记之6】caffe-matlab/python训练LeNet模型并应用于mnist数据集(1)
- 用DPM(Deformable Part Model,voc-release4.01)算法在INRIA数据集上训练自己的人体检测模型
- 深度学习ssd检测模型训练自己的数据集
- YOLOv3 ubuntu 配置及训练自己的VOC格式数据集
- CAFFE学习笔记(二):训练和测试自己的图片
- Windows Caffe 学习笔记(一)训练和测试CIFAR-10数据集
- caffe学习笔记(四)--制作自己的数据集train.txt和val.txt,生成LMDB文件
- 【caffe学习笔记之7】caffe-matlab/python训练LeNet模型并应用于mnist数据集(2)
- 深度学习Caffe实战笔记(19)Windows平台 Faster-RCNN 制作自己的数据集
- 【心得】深度学习入门——训练并测试自己数据集
- YOLOv2训练自己的数据集(VOC格式)
- OpenCV学习笔记(三十一)——让demo在他人电脑跑起来 OpenCV学习笔记(三十二)——制作静态库的demo,没有dll也能hold住 OpenCV学习笔记(三十三)——用haar特征训练自己