Python实现语音识别(基于百度语音识别)
我是一名2016级电子信息工程的学生,这是第一次发博客,因为经常在这里查资料 ,自己也应该贡献一点经验吧,也可以当是记录自己学习的过程吧。
最近在自学python,然后18年9月份正好python加入计算机二级,再然后我趁这个机会就混过了。
百度了一下语音识别,有很许多厂商提供语音识别服务,比如:阿里云、百度AI平台、腾讯云、讯飞AI…
大家可以尝试一下其他的免费平台,我这里选择的是百度语音识别,当然需要注册一个百度云平台的账号,附上网址点击直达
支持的语音格式
原始 PCM 的录音参数必须符合 8k/16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。
我这里采用的是采样率为16KHz、单声道、wav格式的录音参数。
附上录音的源代码
这里需要pyaudio和wave库
LuYin(5, ‘test.wav’)表示录音5秒,文件名为test.wav
import pyaudio
import wave
def LuYin(Time,filename):
CHUNK = 1024 #wav文件是由若干个CHUNK组成的,CHUNK我们就理解成数据包或者数据片段。
FORMAT = pyaudio.paInt16 #这个参数后面写的pyaudio.paInt16表示我们使用量化位数 16位来进行录音。
CHANNELS = 1 #代表的是声道,这里使用的单声道。
RATE = 16000 # 采样率16k
RECORD_SECONDS = Time #采样时间
WAVE_OUTPUT_FILENAME = filename #输出文件名
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* 录音开始")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* 录音结束")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
注意事项
如果需要使用实时识别、长语音、唤醒词、语义解析等其它语音功能,请使用Android或者iOS SDK 或 Linux C++ SDK 等。
请严格按照文档里描述的参数进行开发,特别请关注原始录音参数以及语音压缩格式的建议,否则会影响识别率,进而影响到产品的用户体验。
目前系统支持的语音时长上限为60s,请不要超过这个长度,否则会返回错误。(摘自官方文档)
获取tokent
tokent(鉴权认证机制)相当于是自己的身份,有个这个合格的身份平台才会给你提供服务。
可以把tokent获取出来直接使用,不用每一次都获取,但是这个tokent隔一段时间会失效,我感觉是一个月左右/笑哭
import requests
import json
def Gettokent():
baidu_server = "https://openapi.baidu.com/oauth/2.0/token?"
grant_type = "client_credentials"
#API Key
client_id = "你的API Key"
#Secret Key
client_secret = "你的Secret Key"
#拼url
url = 'https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(client_id, client_secret)
#print(url)
#获取token
res = requests.post(url)
#print(res.text)
token = json.loads(res.text)["access_token"]
print(token)
上传识别
后两项参数为非必须(摘自官方文档)
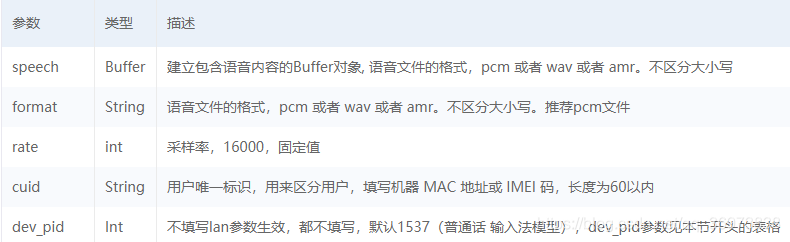
dev_pid 参数列表(摘自官方文档)
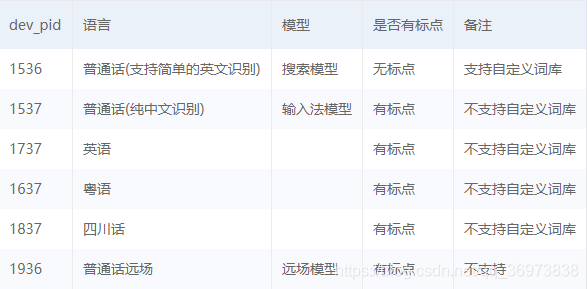
语音识别 返回数据参数详情(摘自官方文档)

返回样例(摘自官方文档)

错误码解释(摘自官方文档)
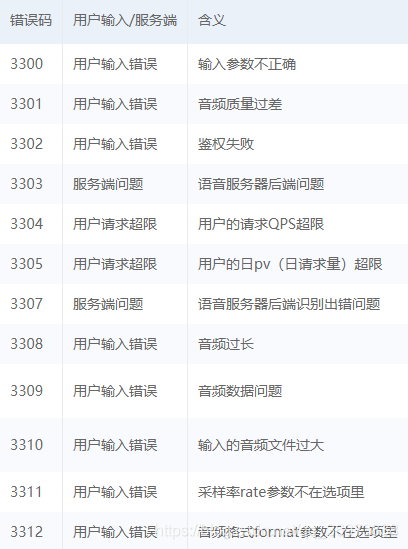
直接附上程序
参数为本地文件的地址
附一个示例音频文件16k.wav
import pyaudio
import wave
import requests
import json
import base64
import os
def BaiduYuYin(fileurl):
try:
RATE = "16000" #采样率16KHz
FORMAT = "wav" #wav格式
CUID = "wate_play"
DEV_PID = "1536" #无标点普通话
token = '你的token'
# 以字节格式读取文件之后进行编码
with open(fileurl, "rb") as f:
speech = base64.b64encode(f.read()).decode('utf8')
size = os.path.getsize(fileurl)
headers = {'Content-Type': 'application/json'}
url = "https://vop.baidu.com/server_api"
data = {
"format": FORMAT,
"rate": RATE,
"dev_pid": DEV_PID,
"speech": speech,
"cuid": CUID,
"len": size,
"channel": 1,
"token": token,
}
req = requests.post(url, json.dumps(data), headers)
result = json.loads(req.text)
return result["result"][0][:-1]
except:
return '识别不清'
第一次写博客,希望大家多多指正,有什么问题请留言,一定及时回复。

- python调用百度语音识别实现大音频文件语音识别功能
- python借用百度语音识别实现大音频文件语音识别功能
- Android开发学习之使用百度语音识别SDK实现语音识别(下)
- Python语言实现百度语音识别API的使用实例
- python tensorflow基于cnn实现手写数字识别
- 基于Python的Selenium自动化(3)— 实现验证码截取并识别
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
- 【机器学习算法实现】kNN算法__手写识别——基于Python和NumPy函数库
- 利用百度语言识别API实现语音识别python
- python实现百度语音识别api
- 基于Python使用CloudSight API实现简单的图像识别(image Recognition)
- 百度语音识别API的使用样例(python实现)
- python实现百度语音之语音识别
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
- 【机器学习算法实现】kNN算法__手写识别——基于Python和NumPy函数库
- Python基于OpenCV库Adaboost实现人脸识别功能详解
- Android开发学习之使用百度语音识别SDK实现语音识别(上)
- 【基于百度AI的人脸识别Python实现】
- Python基于OpnenCV实现人脸识别
- 基于Python的Face_recognition来实现实时人脸识别