图像语义分割的深度学习算法综述
图像语义分割的深度学习算法综述
原创 不靠谱的猫 2018-12-13 18:46:39

COCO数据集的示例
图像语义分割挑战在于将图像的每个像素(或仅几个像素)分类为实例,每个实例(或类别)对应于对象或图像的一部分(道路,天空......)。这项任务是场景理解概念的一部分:深度学习模型如何更好地学习视觉内容的全局背景呢?
在复杂性方面,对象检测任务已超出图像分类任务。它包括在图像中包含的对象周围创建边界框并对它们中的每一个进行分类。大多数对象检测模型使用anchor boxes和proposals来检测对象周围的边界框。不幸的是,只有少数深度学习模型考虑了图像的整个上下文,但它们只对信息的一小部分进行了分类。因此,他们无法提供对场景的完全理解。
为了理解场景,每个视觉信息必须在考虑空间信息的同时与实体相关联。为了真正理解图像或视频中的动作,还出现了其他几个挑战:关键点检测,动作识别,视频字幕,视觉问答等。更好地理解环境将有助于许多领域。例如,自动驾驶汽车需要以高精度划定路边,以便自行移动。在机器人技术中,生产机器应该理解如何抓取,转动和组合不同的部件,这些部件需要划定物体的确切形状。
在这篇文章中,将详细介绍一些先前关于图像语义分割挑战的最先进模型的架构。请注意,研究人员使用不同的数据集(PASCAL VOC,PASCAL Context,COCO,Cityscapes)测试他们的算法,这些数据集年份不同,并使用不同的评估指标。因此,所引用的性能本身不能直接比较。此外,结果取决于预训练的顶级网络(骨干),本文中公布的结果对应于每篇论文中关于其测试数据集发布的最佳分数。
数据集和指标
PASCAL视觉对象类(PASCAL VOC)
PASCAL VOC数据集(2012)是众所周知的常用于物体检测和分割的。超过11k的图像组成了训练和验证数据集,而10k图像专用于测试数据集。
使用mean Intersection over Union (mIoU)度量来评估分段挑战。Intersection over Union (IoU)是一种用于对象检测的度量,用于评估预测位置的相关性。IoU是模型所预测的检测框和ground truth的检测框的交集和并集之间的比例。mIoU是测试数据集的所有图像上的分割对象的IoU之间的平均值。

用于图像分割的2012 PASCAL VOC数据集的示例
PASCAL - Context
PASCAL-Context数据集(2014)是2010 PASCAL VOC数据集的扩展。它包含大约10k个用于训练的图像,10k用于验证和10k用于测试。这个新版本的特性是,整个场景被分割成400多个类别。
PASCAL-Context挑战的官方评估指标是mIoU。研究发布了如像素精度(pixAcc)等其他指标。在这里,性能将仅与mIoU进行比较。
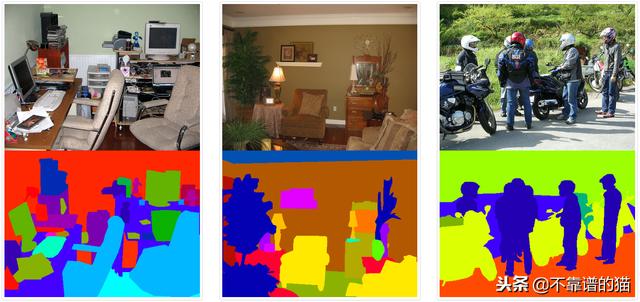
PASCAL-Context数据集的示例
COntext中的常见对象(COCO)
对于图像语义分割(“对象检测”和“stuff segmentation”),存在两个COCO挑战(2017年和2018年)。“对象检测”任务包括将对象分割和分类为80个类别。“stuff segmentation”任务使用的数据是对图像(天空、墙壁、草地)进行大分割的部分,它们几乎包含了全部的视觉信息。在这篇文章中,只会比较“对象检测”任务的结果,因为引用的研究论文中很少有人发布了“stuff segmentation”任务的结果。
用于对象分割的COCO数据集由超过200k个图像组成,具有超过500k对象实例被分割。它包含一个训练数据集,一个验证数据集,一个用于研究者的测试数据集(test-dev)和一个用于挑战的测试数据集(test-challenge)。两个测试数据集的注释都不可用。这些数据集包含80个类别,只对相应的对象进行分割。此挑战使用与对象检测挑战相同的指标:平均精度(AP)和平均召回(AR)均使用IoU。
与AP类似,平均召回使用多个IoU计算,IoU具有特定范围的重叠值。对于固定的IoU,保留具有相应测试/ ground truth重叠的对象。然后为检测到的对象计算Recall度量。最终AR度量是所有IoU范围值的计算Recall的平均值。基本上,用于分割的AP和AR指标与对象检测的工作方式相同,除了IoU是逐像素计算的,用于语义分割的是非矩形形状。

用于对象分割的COCO数据集的示例
Cityscapes
Cityscapes数据集已于2016年发布,包含50个城市的复杂分割城市场景。它由23.5k图像组成,用于训练和验证(精细和粗略注释)和5K个图像用于测试(仅精细注释)。图像是完全分割的,例如具有29个类别的PASCAL-Context数据集(在8个超级类别中:平面,人类,车辆,建筑,对象,自然,天空,虚空)。由于其复杂性,它通常用于评估语义分割模型。它也因其与自动驾驶应用的真实城市场景的相似性而众所周知。使用诸如PASCAL数据集的mIoU度量来计算语义分割模型的性能。
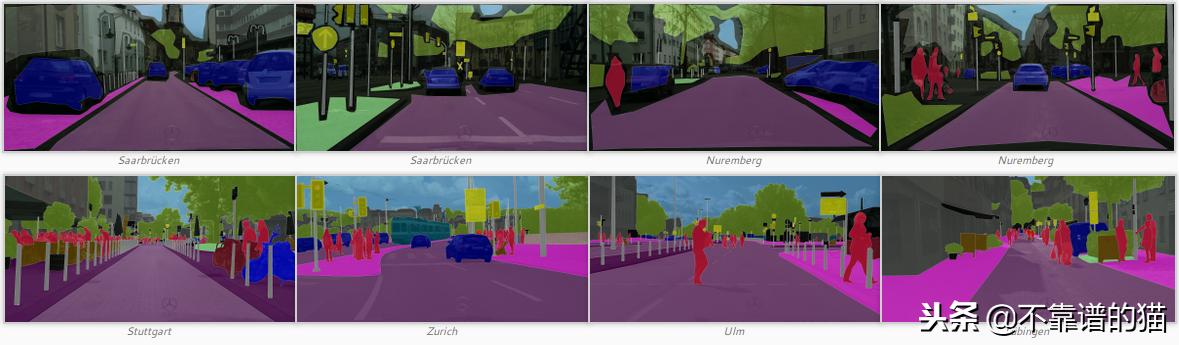
Cityscapes数据集的示例。顶部:粗略注释。底部:精细注释
全卷积网络(FCN)
J. Long等(2015)率先开发了经过端到端训练的全卷积网络(FCN)(仅包含卷积层),用于图像分割。
FCN采用任意大小的图像,生成相同大小的分割图像。作者首先修改著名的架构(AlexNet、VGG16、GoogLeNet),使其具有非固定大小的输入,同时将所有全连接层替换为卷积层。由于网络生成几个小尺寸和dense 表示的特征映射,因此,上采样对于创建具有与输入相同尺寸的输出是必需的。基本上,它是由一个步幅小于1的卷积层构成的。它通常被称为反卷积,因为它产生的输出比输入大。这样,网络就可以使用pixel-wise loss进行训练。此外,他们还在网络中添加了skip connections,以在网络的顶部将高级特征映射表示与更具体和更dense的特征相结合。
作者在2012年ImageNet数据集上使用经过预处理的模型,在PASCAL VOC分割挑战中取得了62.2%的mIoU分。在2012年PASCAL VOC对象检测挑战赛中,名为Faster R-CNN的基准模型mIoU达到了78.8%。即使我们不能直接比较这两个结果(不同的深度学习模型,不同的数据集,不同的挑战),似乎语义分割任务比目标检测任务更难解决。
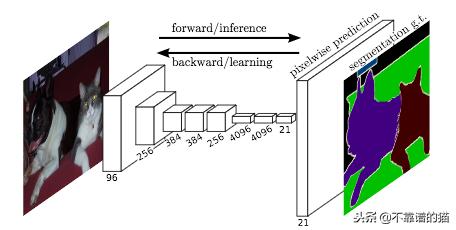
FCN的体系结构。未绘制了skip connections
ParseNet
W. Liu等。(2015)发表了一篇论文,解释了J. Long等人的FCN模型的改进。(2015年)。这组作者说,FCN模型通过专门化生成的特征映射,在其深层中丢失了图像的全局背景。ParseNet是一个端到端的卷积网络,可同时预测所有像素的值,并避免将区域作为输入来保存全局信息。作者使用模块将特征映射作为输入。第一步使用模型生成特征图,这些特征图被缩减为具有池化层的单个全局特征向量。使用L2欧几里德范数对该上下文向量进行归一化,并且它是unpooled的(输出是输入的扩展版本)以生成具有与初始相同尺寸的新特征图。第二步使用L2 Euclidian Norm对整个初始特征映射进行归一化。最后一步连接前两个步骤生成的特征图。归一化有助于缩放concatenated特征图值,从而获得更好的性能。基本上,ParseNet是一个FCN,该模块取代了卷积层。它在PASCAL-Context挑战中获得了40.4%的mIoU分数,在2012年PASCAL VOC分段挑战中获得了69.8%的mIoU分数。
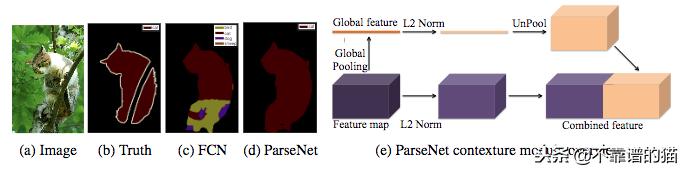
FCN和ParseNet的分段与ParseNet模块的体系结构之间的比较
卷积和反卷积网络
H. Noh等(2015)发布了一个端到端模型,由两个链接部分组成。第一部分是一个具有VGG16架构的卷积网络。它将实例建议作为输入,例如由对象检测模型生成的边框。该方案由卷积网络进行处理和转换,生成特征向量。第二部分是一个以特征向量为输入的反卷积网络,生成每个类的像素概率图。反容积网络使用针对最大激活的unpooling来保持图中信息的位置。第二个网络还使用反卷积将单个输入关联到多个特征映射。反卷积在保持信息dense的同时,扩展了特征图。
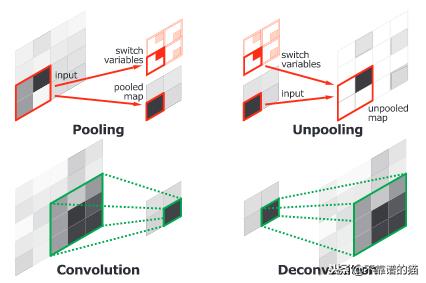
卷积网络层(池和卷积)与反卷积网络层(反池化和反卷积)的比较
作者分析了反卷积特征图,他们注意到低层特征图是特定于形状的,而较高层特征图有助于对提议进行分类。最后,当整个网络处理图像的所有提议时,连接这些地图以获得完全分割的图像。该网络在2012年PASCAL VOC细分挑战中获得了72.5%的mIoU。
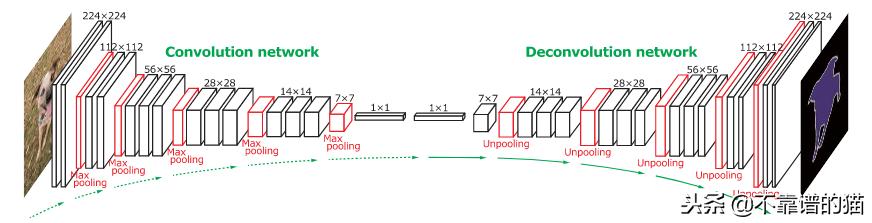
完整网络的体系结构。卷积网络基于VGG16架构。反卷积网络使用反池化和反卷积层
U-Net
O. Ronneberger等(2015)将J. Long等(2015)的FCN扩展到生物显微镜图像。作者创建了一个名为U-net的网络,由两部分组成:contracting部分用于计算特征,expanding部分用于对图像中的模式进行空间定位。下采样或contracting部分具有类似FCN的结构,提取具有3x3卷积的特征。上采样或扩展部分使用上卷积(或反卷积)减少特征图的数量,同时增加它们的高度和宽度。来自网络的下采样部分的裁剪特征映射被复制在上采样部分内,以避免丢失模式信息。最后,1x1卷积处理特征图以生成分割图,从而对输入图像的每个像素进行分类。此后,U-net架构在最近的工作(FPN、PSPNet、DeepLabv3等)中得到了广泛的扩展。请注意,它不使用任何全连接层。因此,模型的参数数量减少,并且可以使用小的标记数据集(使用适当的数据增强)进行训练。例如,作者在实验过程中使用了包含30张图像的公共数据集进行训练。
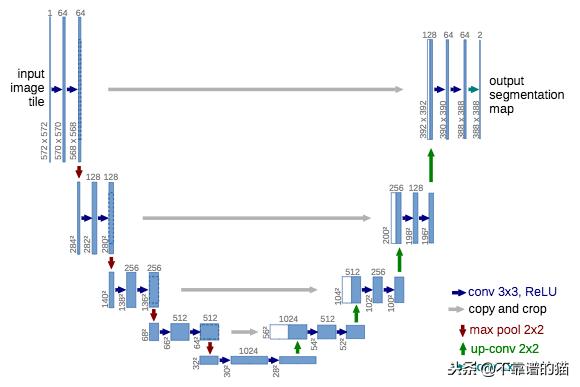
给定输入图像的U-net架构。蓝色框对应于具有其表示形状的特征映射块。白框对应于复制和裁剪的特征图
特征金字塔网络(FPN)
Feature Pyramid Network(FPN)由T.-Y开发。Lin等人(2016)将它用于对象检测或图像分割框架。其架构由自下而上的通道,自上而下的通道和横向连接组成,以便连接低分辨率和高分辨率的特征。自下向上路径以任意大小的图像作为输入。它由卷积层处理,由池化层降采样。注意,每一组具有相同大小的特征映射称为一个阶段,每个阶段的最后一层的输出是用于金字塔级别的特征。在自上而下的途径包括使用横向连接使用自下而上路径的同一阶段的特征映射来增强它们的最后一个特征映射,同时使用横向连接。这些连接包括将自下而上路径的特征图与1x1卷积(以减小其尺寸)与自上而下路径的特征图合并。
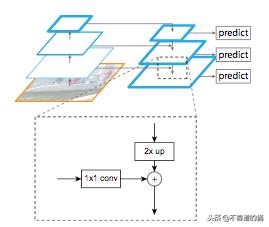
具有横向连接和特征映射之和的自上而下的块过程的细节
然后,通过3x3卷积处理级联的特征图以产生该级的输出。最后,自上而下路径的每个阶段生成预测以检测对象。对于图像分割,作者使用两个多层感知器(MLP)在对象上生成两个不同大小的masks。它类似于具有anchor boxes的Region Proposal Networks (R-CNN R. Girshick et al. (2014), Fast R-CNN R. Girshick et al. (2015), Faster R-CNN S. Ren et al.(2016)等)。这种方法很有效,因为它可以更好地将 low information传播到网络中。基于DeepMask的FPN(P. 0. Pinheiro等人(2015))和SharpMask(P. 0. Pinheiro等人(2016)))框架在2016年COCO细分挑战中获得了48.1%的平均召回(AR)分数。
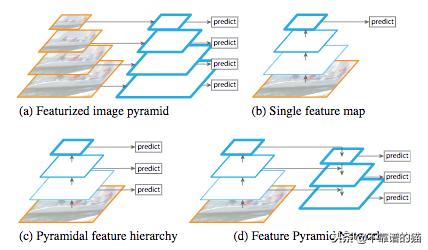
架构比较。(a):图像用几种尺寸缩放,每一种都用卷积处理,以提供计算上可扩展的预测。(b):图像具有由CNN处理的single scale ,其具有卷积和池化层。(c)CNN的每一步都用于提供预测。(d)FPN的体系结构,左上角部分和右上角部分。
金字塔场景解析网络(PSPNet)
H. Zhao等(2016)开发了金字塔场景解析网络(PSPNet),更好地学习场景的全局上下文表示。使用具有dilated network策略 的特征提取器(ResNet K.He 等人(2015))从输入图像中提取模式。特征图提供金字塔池化模块区分不同尺度的图案。它们与四个不同的尺度合并,每个尺度对应于金字塔级别,并由1x1卷积层处理以减小它们的尺寸。这样,每个金字塔级别分析具有不同位置的图像的子区域。金字塔级别的输出被上采样并连接到初始特征图以最终包含局部和全局上下文信息。然后,它们由卷积层处理以生成特征预测。具有预训练ResNet(使用COCO数据集)的最佳PSPNet在2012年PASCAL VOC分段挑战中达到了85.4%的mIoU分数。
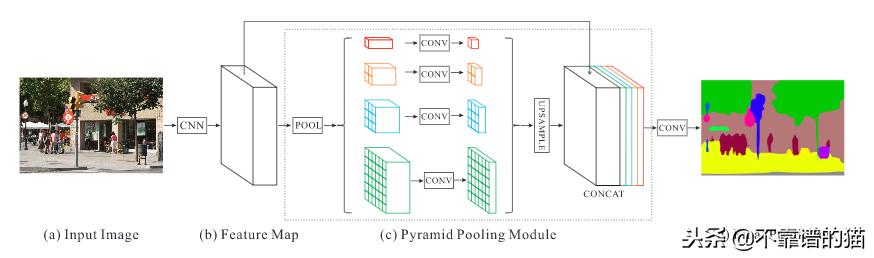
PSPNet架构。输入图像(a)由CNN处理以生成特征图(b)。它们提供金字塔池化模块©,最终卷积层生成逐像素预测
Mask R-CNN
K. He等。(2017年)发布了Mask R-CNN模型,击败了许多COCO挑战的所有先前基准。用于对象检测的Faster R-CNN(S.Ren等人(2015))架构使用RPN来提出边界框候选。RPN提取感兴趣区域(RoI)和RoIPoollayer计算这些提议中的特征,以便推断边界框坐标和对象的类。Mask R-CNN是一个Faster R-CNN,有3个输出分支:第一个计算边界框坐标,第二个计算相关类,最后一个计算二进制掩码以分割对象。二进制掩码具有固定大小,并且由给定RoI的FCN生成。它还使用RoIAlign层而不是RoIPool来避免由于RoI坐标的量化而导致的错位。Mask R-CNN模型的特殊性是其多任务损失,其组合了边界框坐标、预测类别和segmentation mask的损失。该模型试图解决互补任务,从而在每项任务中获得更好的表现。最好的Mask R-CNN使用ResNeXt(S。Xie 等人(2016))来提取特征和FPN架构。它在2016年COCO细分挑战中获得了37.1%的AP评分,在2017年COCO细分挑战中获得了41.8%的AP评分。
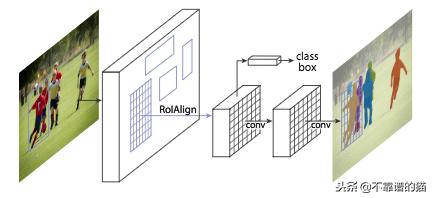
Mask R-CNN架构。第一层是提取RoI的RPN。第二层处理RoI以生成特征映射。它们直接用于计算边界框坐标和预测类。特征图也由FCN(第三层)处理以生成binary mask
DeepLab,DeepLabv3和DeepLabv3 +
DeepLab
灵感来自T.-Y的FPN模型。Lin等(2016),L.-C。陈等人。(2017年)发布了DeepLab,结合了atrous卷积,空间金字塔池化和CRF。本文中介绍的模型也称为DeepLabv2,因为它是对初始DeepLab模型的调整。作者说,连续的最大池化和striding降低了深度神经网络中特征图的分辨率。他们引入了atrous convolution,这基本上是H. Zhao等人的扩张卷积。(2016)。它由针对具有固定速率的稀疏像素的filters组成。例如,如果速率等于2,则filter将输入中的一个像素对准两个像素; 如果速率等于1,则atrous convolution是基本卷积。Atrous卷积允许捕获多个尺度的物体。如果在没有max-poolling的情况下使用它,它会增加最终输出的分辨率而不会增加权重数。
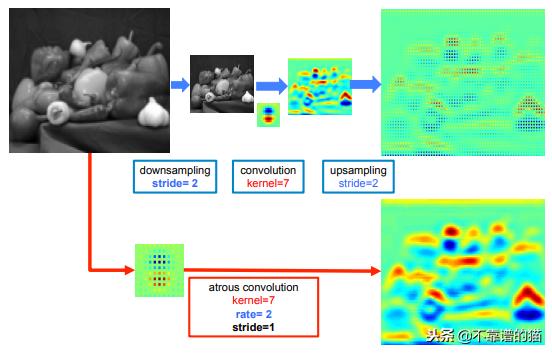
低分辨率输入(顶部)上的标准卷积与高分辨率输入(底部)上的速率为2的atrous 卷积之间的提取模式比较
Atrous Spatial Pyramid Pooling在于把同一输入以不同速率进行若干次atrous卷积,以检测空间模式。特征图在单独的分支中处理,并使用双线性插值连接以恢复输入的原始大小。输出为一个完全连接条件随机场(CRF)(Krähenbühl和V.Koltun(2012)),计算特征与长期依赖项之间的边缘,从而产生语义分割。
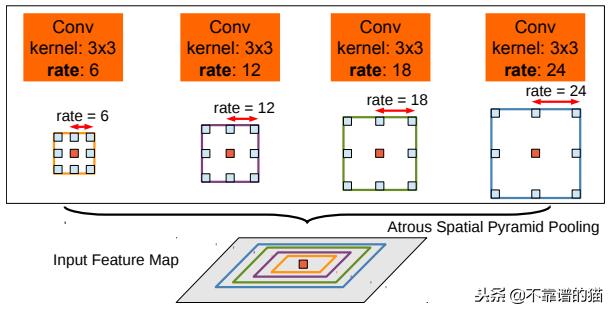
Atrous Spatial Pyramid Pooling(ASPP)利用多个对象比例对中心的像素进行分类
使用ResNet-101作为主干的最佳DeepLab在2012年PASCAL VOC挑战中达到了79.7%的mIoU分数,在PASCAL-Context挑战中获得了45.7%的mIoU分数,在Cityscapes挑战中获得了70.4%的mIoU分数。
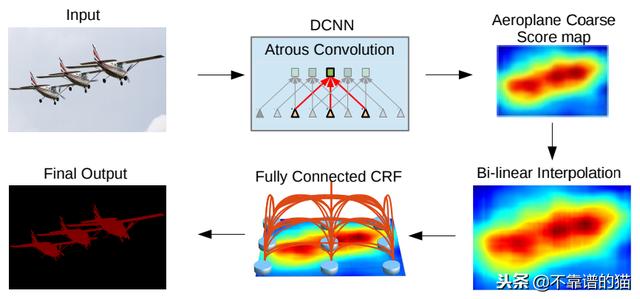
DeepLab框架
DeepLabv3
L.-C. 陈等人。(2017)重新审视了DeepLab框架,创建了DeepLabv3。作者修改了ResNet架构,使用atrous卷积将deep blocks中的高分辨率特征映射保留下来。
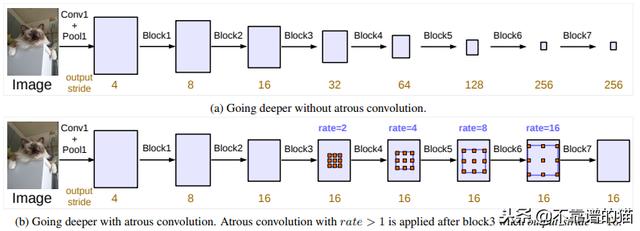
ResNet架构中的级联模块
并行的atrous卷积模块分组在Atrous Spatial Pyramid Pooling(ASPP)中。在ASPP中添加1x1卷积和批归一化。所有输出由另一个1x1卷积连接和处理,以创建具有每个像素的对数的最终输出。
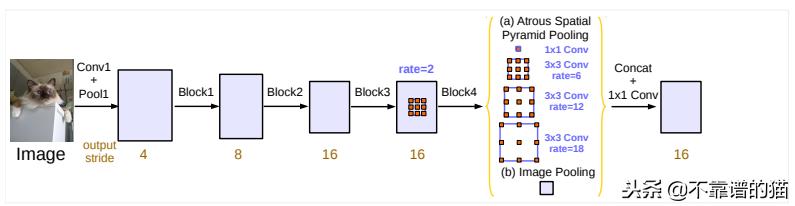
Deeplabv3框架中的Atrous Spatial Pyramid Pooling
在2012年PASCAL VOC挑战中,在ImageNet和JFT-300M数据集上预训练的ResNet-101的最佳DeepLabv3模型已达到86.9%mIoU分数。它还通过仅使用相关训练数据集训练的模型在Cityscapes挑战中获得81.3%的mIoU分数。
DeepLabv3 +
L.-C. 陈等人。(2018)最终使用编码器 - 解码器结构发布了Deeplabv3 +框架。作者引入了由深度卷积(输入的每个通道的空间卷积)和逐点卷积(1x1卷积与深度卷积作为输入)组成的可怕的可分离卷积。
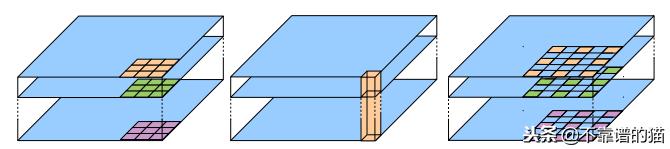
深度卷积(a)和逐点卷积(b)的组合产生Atrous可分离卷积(速率为2)
他们使用DeepLabv3框架作为编码器。最高性能的模型具有修改的Xception(F.Chollet(2017))backbone,具有更多层,atrous深度可分离卷积而不是最大池化和批归一化。ASPP的输出由1×1的卷积进行处理,并且以4的因子被上采样。编码器主干CNN的输出也由另一个1x1卷积处理,并连接到前一个。该特征图将两个3×3卷积层馈送,并且输出被以4的因子进行上采样,以创建最终的分割图像。
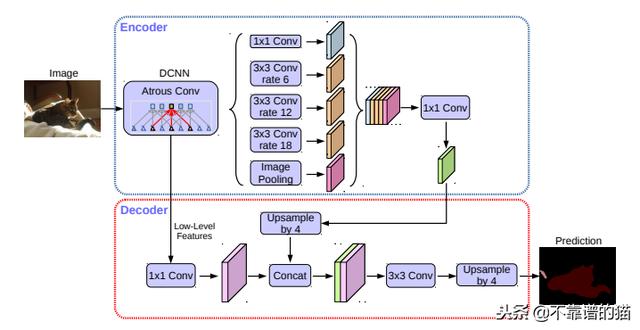
DeepLabv3 +框架:具有backbone的编码器CNN和ASPP产生特征表示,以向解码器馈送3x3卷积,产生最终预测图像
在COCO和JFT数据集上获得的最佳DeepLabv3 +在2012年PASCAL VOC挑战中获得了89.0%的mIoU分数。在Cityscapes数据集上训练的模型已达到相关挑战的82.1%mIoU分数。
Path Aggregation Network(PANet)
S. Liu等。(2018)最近发布了PANET。该网络基于Mask R-CNN和FPN框架,同时增强了信息传播。网络的特征提取器使用FPN架构,其具有新的增强自下而上路径,改善了低层特征的传播。该第三路径的每个阶段将前一阶段的特征图作为输入,并用3×3卷积层处理它们。使用横向连接将输出添加到自上而下路径的相同阶段特征图中,并且这些特征图为下一阶段提供信息。
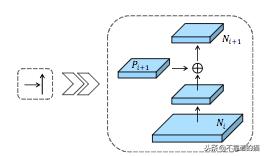
自上而下的通路和增强的自下而上通路之间的横向连接
增强的自下而上路径的特征图与RoIAlign层合并,以从所有级别特征中提取提议。的适应性特征池层处理每个阶段的特征映射具有完全连接的层并连接所有输出。
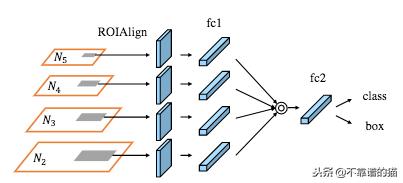
Adatative特征池化层
自适应特征池化层的输出与Mask R-CNN类似地馈送三个分支。前两个分支使用一个全连接层来生成包围框坐标和相关对象类的预测。第三个分支使用FCN处理RoI,以预测用于所检测的目标的binary pixel-wise mask 。作者添加了一个路径处理FCN卷积层的输出与一个全连接层,以改善预测像素的定位。最后,对并行路径的输出进行重构,并将其连接到生成binary mask的FCN的输出。
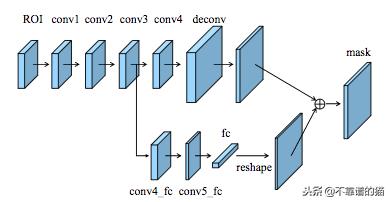
PANet的分支使用FCN预测binary mask和具有全连接层的新路径
使用ResNeXt作为特征提取器,PANet在2016年COCO分段挑战中获得了42.0%的AP分数。他们还使用七个特征提取器的集合进行了2017年COCO细分挑战,AP评分为46.7%:ResNet(K. He et al. (2015), ResNeXt (S. Xie et al. (2016)) and SENet (J. Hu et al.(2017))。
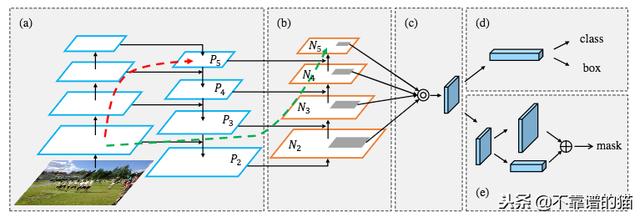
PANet Achitecture。(a):使用FPN架构的特征提取器。(b):新增加的自下而上的途径被添加到FPN架构中。(c):自适应特征池化层。(d):两个分支预测协调的边界框和对象类。(e):预测对象的binary mask的分支。虚线对应于低级和高级模式之间的链接,红色部分在FPN中并且包含超过100个层,绿色部分是PANet中由少于10个层组成的快捷方式
上下文编码网络(EncNet)
H. Zhang et al.(2018)创建了上下文编码网络(EncNet),在图像中捕捉全局信息,以提高场景分割。该模型首先使用一个基本的特征提取器(ResNet),并将特征映射提供给一个上下文编码模块,该模块灵感来自H. Zhang等人(2016)的编码层。基本上,它学习视觉中心和平滑因子来创建一个嵌入,同时突出依赖类的feature map,同时考虑上下文信息。在该模块之上,利用feature map attention layer (full connected layer)学习上下文信息的缩放因子。与此同时,对应于二元交叉熵损失的语义编码损失(SE-Loss)通过检测对象类的存在(不同于像素损失)来规范模块的训练。上下文编码模块的输出通过Dilated卷积策略进行重构和处理,同时最小化两个SE-losses和最终pixel-wise损失。在PASCAL-Context挑战中,最好的EncNet达到了52.6% mIoU和81.2% pixAcc得分。在2012 PASCAL VOC细分挑战赛中,mIoU也取得了85.9%的高分。
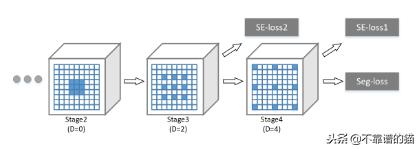
Dilated convolution strategy。蓝色卷积filter用D的扩张率。在第三和第四阶段之后应用SE损失(语义编码损失)以检测对象类。应用最终的Seg-loss(像素方式丢失)来改善分割
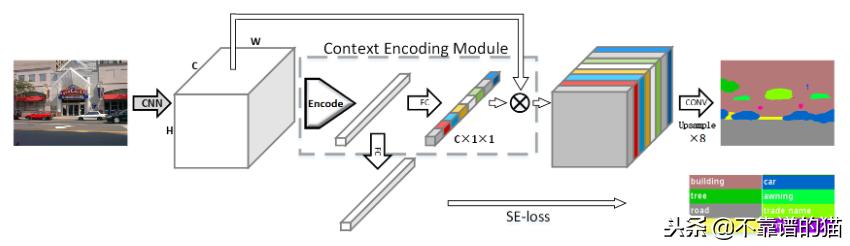
EncNet的体系结构。特征提取器生成作为上下文编码模块的输入的特征映射。使用语义编码丢失对模块进行正则化训练。模块的输出由Dilated卷积策略处理以产生最终的分段
结论
图像语义分割是最近由端到端深度神经网络引起的挑战。所有体系结构之间的主要问题之一是考虑输入的全局视觉上下文以改进分割的预测。最先进的模型使用架构试图链接图像的不同部分,以便理解对象之间的关系。
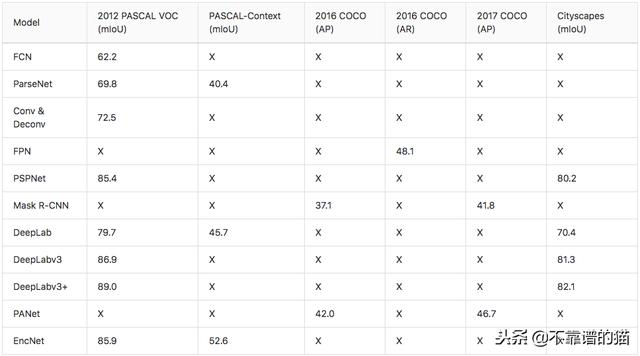
2012年PASCAL VOC数据集(mIoU),PASCAL-Context数据集(mIoU),2016/2017年COCO数据集(AP和AR)和Cityscapes数据集(mIoU)的模型得分概述
整个图像上的像素预测允许以高精度更好地理解环境。通过关键点检测,动作识别,视频字幕或视觉问题回答也可以了解场景。在我看来,分段任务与使用多任务丢失的其他问题相结合应该有助于超越场景的全局上下文理解。

- [置顶] 【译】DeepLab V2:基于深度卷积网、孔洞算法和全连接CRFs的语义图像分割
- 深度学习(二十一)基于FCN的图像语义分割-CVPR 2015
- 基于深度学习的图像语义分割技术概述之5.4未来研究方向
- 基于深度学习的图像语义分割技术概述之背景与深度网络架构
- 基于深度学习的图像语义分割技术概述之常用方法
- 基于深度学习的图像语义分割技术概述之背景与深度网络架构
- 语义分割 - 基于深度学习的图像背景移除
- 基于深度学习的图像语义分割技术概述之5.1度量标准
- 基于深度学习的图像语义分割技术概述之常用方法
- 图像语义分割综述(Overview of Image Segmentation)
- 基于深度学习的图像语义分割技术概述之背景与深度网络架构
- 推荐 | 基于深度学习的图像语义分割方法回顾(附PDF下载)
- 论文笔记 | 基于深度学习的图像语义分割技术概述之5.1度量标准
- 基于深度学习的图像语义分割技术概述之4常用方法
- 基于深度学习的图像语义分割技术概述之背景与深度网络架构
- 深度学习(二十一)基于FCN的图像语义分割-CVPR 2015-未完待续
- 深度学习(二十一)基于FCN的图像语义分割-CVPR 2015-未完待续
- 使用深度学习技术的图像语义分割最新综述
- 深度卷积网络CNN与图像语义分割
- CRF图像语义分割