学习笔记:从0开始学习大数据-34.hadoop集群准备之docker安装
今天是冬至日,广州冷了几天,阴了几天后,又阳光灿烂,气温升到了25°,阳台外,依然绿树成荫,鸟雀声声,冬眠了几天的乌龟也从角落爬出来伸展四肢晒太阳,这应该是去爬山的好日子,而正在学大数据的我,深感路还漫长,继续爬大数据这座山吧!大数据何常不是一朵信息科学之花呢

言归正传,今天要学习的是docker的安装使用。
为什么学习大数据要学习docker呢,因为我在学校的电脑是32G内存的,开几个虚拟机,构建大数据集群还能玩得转,但家里笔记本电脑只有8G内存,宿主win10上安装的vmware里的centos7只有5G内存了,所以前面安装大数据生态圈各软件都是all in one,是单机或伪分布式部署,学校的学生在校园云上,也难以满足每个学习大数据的学生都分配几个虚拟机,几十G的内存,这样,不但资源难于满足,效率也不高,因此,就想到了docker,利用这个,可以在资源不多的情况下构建hadoop分布式集群环境。因为以前没有需求,还真没接触过,今天就科普并尝试一下。
先记录个学习网址:
http://www.runoob.com/docker/docker-tutorial.html
以下介绍docker与虚拟机的差别,这个是从外看docker与虚拟机的差别,从安装在里面的应用角度来看,运行在docker沙盒还是在虚拟机上是一样的。
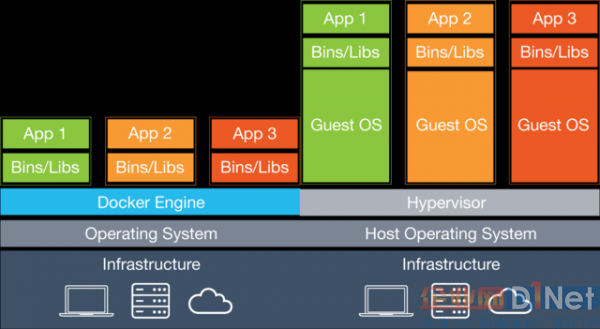
1.安装
在我的centos7上,尝试直接yum install docker 很快就安装成功
# yum install docker

2.测试
systemctl start docker

因为是第一次运行且没有指定版本,docker自动下载了latest即最新的linux版本的影像,并成功启动影像运行程序。
3. 测试运行 ubuntu16.04 的shell

指定docker运行ubuntu16.04的bash shell的交互模式,docker检测到本机没有ubuntu16.04的影像,自动下载后运行,这个和ubuntu16.04 操作系统1到几各G不同,只下载了几十M的一个影像,启动也非常快速。
查看正在运行的docker实例:
[root@centos7 linbin]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dc283b0e699b ubuntu:16.04 "/bin/bash" 17 seconds ago Up 17 seconds elegant_cray
因为这个特点,docker一般一个映像的一个实例里面只运行一个应用,有多个应用运行多个实例就行了,测试好了,部署时把整个映像实例复制过去,省却了在实施环境,再安装配置部署的麻烦。稳定,快速,高效。
很棒,下节利用docker先部署一个hadoop hdfs集群测试一下。

- 学习笔记:从0开始学习大数据-35.docker部署hadoop集群
- 学习笔记:从0开始学习大数据-36.docker部署zookeeper集群
- 学习笔记:从0开始学习大数据-2.hadoop安装
- hadoop学习笔记七 -- hadoop集群高可用架构安装配置
- 大数据学习笔记——Hadoop1.x基本概念和安装
- Hadoop 学习笔记五 集群安装
- hadoop学习笔记之前期准备 ubuntu16.04虚拟机安装、WMwareTools安装及网络配置
- 学习笔记:从0开始学习大数据-10. hive安装部署
- Hadoop学习笔记【12】-Hadoop2.1全分布式集群安装
- 大数据学习笔记01-HDFS-集群安装
- Spark学习笔记(二) 安装Hadoop单节点集群
- 学习笔记:从0开始学习大数据-18.kettle安装使用
- 学习笔记:从0开始学习大数据-16. kafka安装及使用
- Hadoop学习笔记二:准备工作之JDK安装
- 第114讲:Hadoop集群安装解析学习笔记
- 开始hadoop前的准备:ubuntu学习笔记-基本环境的搭建(ssh的安装,SecureCRT连接,vim的安装及使用、jdk的安装)
- Hadoop学习笔记(准备与安装)
- 一步两步,学习大数据(三)——Hadoop集群安装
- 大数据集群安装学习笔记
- 学习笔记:从0开始学习大数据-1.centos7安装