Solr安装及入门使用教程
Solrs使用教程
目录
- Solr简介
- Solr特点
- Solr工作方式
- Solr安装及配置
- Solr简单使用
Solr简介
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。用户可以通过https请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面, 是一款非常优秀的全文搜索引擎。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过https请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果;
Solr特点
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
文档通过Http利用XML 加到一个搜索集合中。查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。

Solr工作方式
文档通过Http利用XML 加到一个搜索集合中。
查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。

Solr安装及配置
Solr使用
Solr简单命令
开启命令:
solr.cmd start
重启命令:
solr restart –p 8983
关闭命令:
solr.cmd stop -p 8983
步骤1.把mysql的jar包放在C:\Solr\solr-7.3.1\server\solr-webapp\webapp\WEB-INF\lib目录下面,如图:

步骤2.以管理员的身份运行cmd,启动solr,命令如下:
solr.cmd start

浏览器测试
localhost:8983
成功,如图:

步骤3.创建一个核心管理员,如图:

上图我们看到了报错,解决方法如下:
把C:\Solr\solr-7.3.1\server\solr\configsets_default目录下的conf复制到我们刚才创建的new_core目录下(C:\Solr\solr-7.3.1\server\solr\new_core的目录下),然后cmd输入重启命令:
重启命令:
solr restart –p 8983
浏览器点击刷新后再点击Add core就创建成功了,如图:

创建成功:

步骤4.下面我们来配置中文的分词索引
在下图中我们可以看到我们随便输入一些中文的词字,它不会把一个词放在一起,而是分开的。

那我们应该把整个词合并在一起呢,下面请看配置步骤:
1.在C:\Solr\solr-7.3.1\server\solr\new_core\conf的目录下的文件solrconfig.xml中加入如下jar包:
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex="lucene-analyzers-smartcn-\d.*\.jar" />

2.在C:\Solr\solr-7.3.1\server\solr\new_core\conf的目录下的文件;
managed-schema中添加如下配置:
<fieldType name="text_ik_zd" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
(1) fieldType:为field定义类型,最主要作用是定义分词器,分词器决定着如何从文档中检索关键字
(2)analyzer:他是fieldType下的子元素,这就是传说中的分词器,他由一组tokenizer和filter组成
搞定,cmd执行停止命令:
solr.cmd stop -p 8983
再输入运行命令,然后刷新浏览器,如下图:
solr.cmd start
或者重启服务命令:
solr restart –p 8983

好了现在我们可以看到分词搜索可以用啦
DIH导入索引数据
DIH全称是Data Import Handler 数据导入处理器,顾名思义这是向solr中导入数据的,我们的solr目的就是为了能让我们的应用程序更快的查询出用户想要的数据,而数据存储在应用中的各种地方入xml、pdf、关系数据库中,那么solr首先就要能够获取这些数据并在这些数据中建立索引来达成快速搜索的目的,这里就列举我们最常用的从关系型数据库中向solr导入索引数据
步骤1.C:\Solr\solr-7.3.1\server\solr\new_core\conf目录下的文件solrconfig.xml中加入如下配置和jar包:
<lib dir="${solr.install.dir:../../../..}/dist" regex="solr-dataimporthandler-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist" regex="solr-dataimporthandler-extras-\d.*\.jar" />
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <!--datasorce config--> <str name="config">data-config.xml</str> </lst> </requestHandler>


步骤2.在C:\Solr\solr-7.3.1\server\solr\new_core\conf目录下新增一个data-config.xml文件,在data-config.xml中加入如下配置:
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/test" user="root" password="root" name="productSource"/> <document> <entity name="product" query="SELECT pid,name,price,description FROM products " pk="pid" dataSource="productSource"> <field column="pid" name="product_id"/> <field column="name" name="product_name"/> <field column="price" name="product_price"/> <field column="description" name="product_desc"/> </entity> </document> </dataConfig>

cmd重新启动,然后刷新浏览器:
solr restart –p 8983
步骤3.把数据库里的字段添加到Schema里,上图中我们有四个字段所以要添加四个
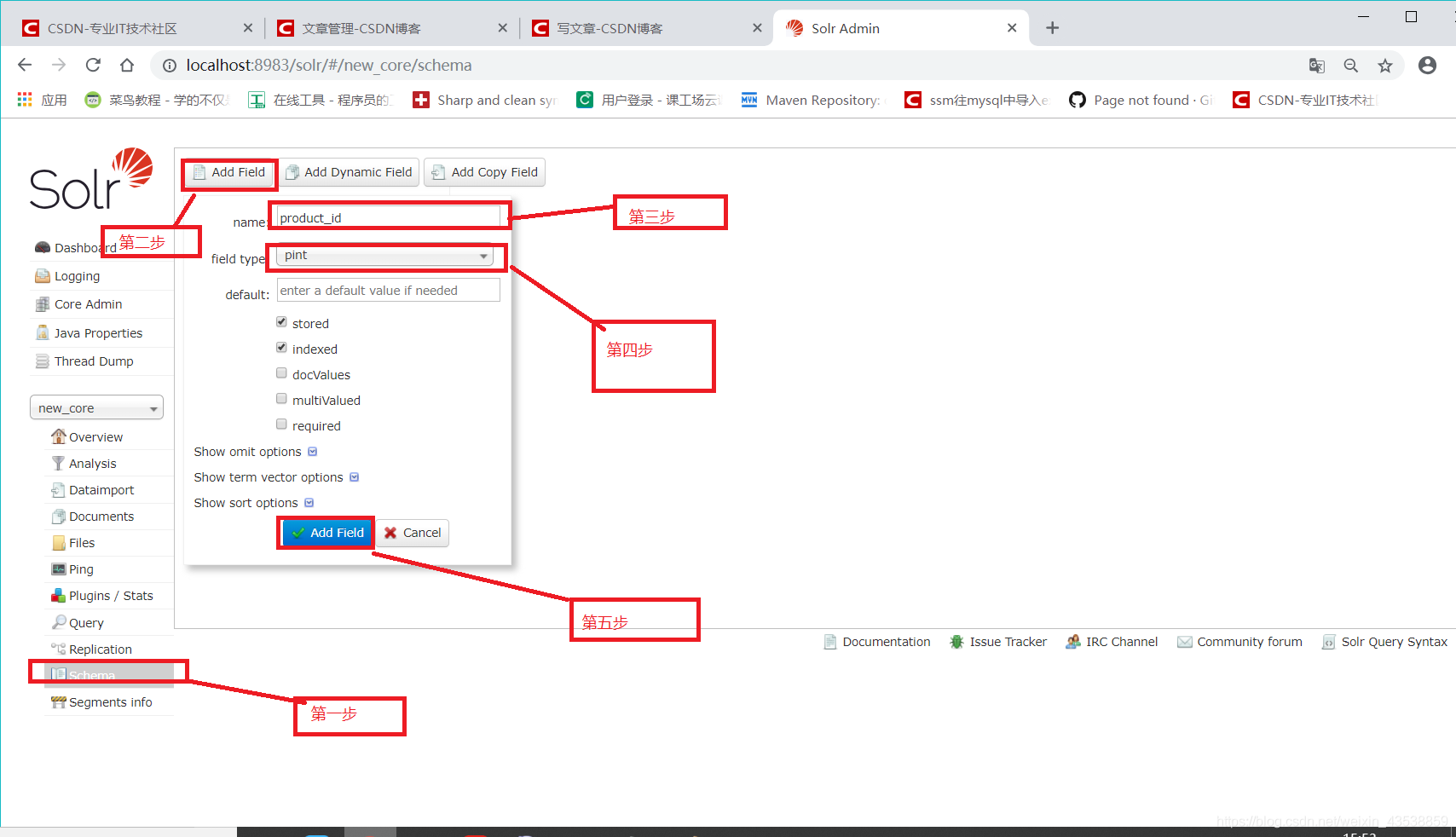



上图中第四步是选择数据类型,
int对应pint,
string 对应的是前面我们添加的分词text_ik_zd,
float对应的是pfloat
步骤3.添加完成后接下来我们要进行数据导入:

上图中我们成功的导入了两行数据,接下来我们把导入的两行数据以JSON的格式查询出来:


上图就是我们从数据库查出来的两行数据
我把数据库的表也放出来:
CREATE TABLE `products` ( `pid` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) DEFAULT NULL, `price` FLOAT DEFAULT NULL, `description` VARCHAR(50) DEFAULT NULL, PRIMARY KEY (`pid`) ) ENGINE=INNODB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8; /*Data for the table `products` */ INSERT INTO `products`(`pid`,`name`,`price`,`description`) VALUES (1,'烧饼',22,'阿斯顿发生'),(2,'长皮',2,'的说法地方');
PS:到这里基本上已经介绍完了,如果又不懂的地方欢迎留言

- phpMyAdmin下载、安装和使用入门教程
- 《Visual C++ 2010入门教程》系列二:安装、配置和首次使用VS2010
- 《Visual C++ 2010入门教程》系列二:安装、配置和首次使用VS2010
- phpMyAdmin下载、安装和使用入门教程
- 《Visual C++ 2010入门教程》系列二:安装、配置和首次使用VS2010
- ubuntu14.04环境中github的安装与使用入门教程(最新,2016-06-03)
- 树莓派入门教程——I2C Tools的安装和使用
- Jmeter系统入门教程(安装、组件使用、Demo展示、连接数据库、压测报告)
- MongoDB入门教程(包含安装、常用命令、相关概念、使用技巧、常见操作等)
- Zabbix 全新安装教程 入门使用教程
- phpMyAdmin下载、安装和使用入门教程
- opencv 入门教程, ubuntu安装,及python 下简单使用
- Scrapy爬虫入门教程 安装和基本使用
- [置顶] docker-compose教程(安装,使用, 快速入门)
- solr安装使用教程
- 我的美丽天使(My Fair Angel)入门经典教程(下载 安装 汉化 使用)
- 《Visual C++ 2010入门教程》系列二:安装、配置和首次使用VS2010(转)
- PHP模板之Smarty安装与使用入门教程
- Flash Media Server安装与使用入门教程(转)
- 在Linux 系统 Latex安装 使用入门教程