简单NLP分析套路(2)----分词,词频,命名实体识别与关键词抽取
文章大纲
google 近期发布了颠覆性的NLP模型–BERT ,大家有空可以了解一下,
这是张俊林博士写的科普文章:
https://mp.weixin.qq.com/s/EPEsVzbkOdz9GovrAM-p7g
上一篇文章讲讲解了,https://blog.csdn.net/wangyaninglm/article/details/83479837
如何使用python 爬取三种类型的网站语料库,我就使用其中一种针对自己的博客进行一些简单的分析工作。
代码链接:
https://github.com/wynshiter/NLP_DEMO
主要包含以下一些内容:
- 分词
- 词频
- 命名实体识别
- 关键词抽取
中文分词技术
之前写过两篇分词相关的文章,里面简要介绍了中文分词技术,我认为汉语分词技术在深度学习之前完全是一种独立的技术手段。主要使用规则,统计或者混合的方式进行分词。
在文章,深度学习与中文短文本分析总结与梳理第三小节中
中我都曾简单介绍过中文分词技术。那么文章中提到的各类分词技术到底实战效果如何,我们就来看看
评测参考
https://www.geek-share.com/detail/2719221034.html
云服务
哈工大语言云 ltp
准确率:
综合准确率较高,windows下安装时候坑比较多,linux 估计会好一些
文档:
https://pyltp.readthedocs.io/zh_CN/latest/api.html
github:
https://github.com/HIT-SCIR/ltp
分词例子:nlp_demo
LTP_DATA_DIR = r'..\ltp_data_v3.4.0' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model`
ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 命名实体识别模型路径,模型名称为`pos.model`
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 依存句法分析模型路径,模型名称为`parser.model`
srl_model_path = os.path.join(LTP_DATA_DIR, 'pisrl_win.model') # 语义角色标注模型目录路径,注意windows 和linux 使用不同模型
def main():
words = segmentor('我家在中科院,我现在在北京上学。中秋节你是否会想到李白?')
print(roles)
# 分句,也就是将一片文本分割为独立的句子
def sentence_splitter(sentence='你好,你觉得这个例子从哪里来的?当然还是直接复制官方文档,然后改了下这里得到的。我的微博是MebiuW,转载请注明来自MebiuW!'):
sents = SentenceSplitter.split(sentence) # 分句
print('\n'.join(sents))
"""分词"""
def segmentor(sentence=None):
segmentor = Segmentor() # 初始化实例
segmentor.load(cws_model_path) # 加载模型
words = segmentor.segment(sentence) # 分词
#默认可以这样输出
print ('\t'.join(words))
# 可以转换成List 输出
words_list = list(words)
segmentor.release() # 释放模型
return words_list
安装报错参考
https://blog.csdn.net/weixin_40899194/article/details/79702468
基于深度学习方法的中文分词
https://github.com/rockyzhengwu/FoolNLTK
一个领域细分的中文分词工具包(北大最新开源)
https://github.com/lancopku/PKUSeg-python
信息检索与关键词提取
这个部分我们来介绍一些能够衡量文章中词汇重要性 的指标
早先我在做一个简单POC 的时候现学现卖了一些,那时候居然 不知道jieba 库直接提供了计算TF-IDF TEXTRANK的接口,还是找着论文自己写了一段程序实现的。
之前文章:《短文本分析----基于python的TF-IDF特征词标签自动化提取》没有写完,现在想针对NLP 的通用技术方法做一个阶段性总结:
文本被分词之后,会有如下两个问题:
其一,并不是所有的词汇都对表达文章意思有意义;
其二,一个语料库的词量是非常大的,传统的文本挖掘方法又是基于向量空间模型表示的,所以这会造成数据过于稀疏。
为了解决这两个问题一般会进行停用词过滤和关键字提取,而后者现有基于频率的TF-IDF计算方法和基于图迭代的TextRank的计算方法两种。下面看看这两种方法是怎么工作的
TF-IDF
信息检索概述
信息检索是当前应用十分广泛的一种技术,论文检索、搜索引擎都属于信息检索的范畴。通常,人们把信息检索问题抽象为:在文档集合D上,对于由关键词w[1] … w[k]组成的查询串q,返回一个按查询q和文档d匹配度 relevance (q, d)排序的相关文档列表D。
对于这一基问题,先后出现了布尔模型、向量模型等各种经典的信息检索模型,它们从不同的角度提出了自己的一套解决方案。
布尔模型以集合的布尔运算为基础,查询效率高,但模型过于简单,无法有效地对不同文档进行排序,查询效果不佳。
向量模型把文档和查询串都视为词所构成的多维向量,而文档与查询的相关性即对应于向量间的夹角。不过,由于通常词的数量巨大,向量维度非常高,而大量的维度都是0,计算向量夹角的效果并不好。另外,庞大的计算量也使得向量模型几乎不具有在互联网搜索引擎这样海量数据集上实施的可行性。
TF-IDF原理概述
如何衡量一个特征词在文本中的代表性呢?以往就是通过词出现的频率,简单统计一下,从高到低,结果发现了一堆的地得,和英文的介词in of with等等,于是TF-IDF应运而生。
TF-IDF不但考虑了一个词出现的频率TF,也考虑了这个词在其他文档中不出现的逆频率IDF,很好的表现出了特征词的区分度,是信息检索领域中广泛使用的一种检索方法。
Tf-idf算法公式以及说明:
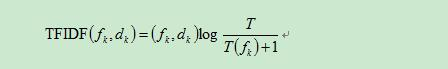
具体实现如下所示,公式分成两项,词频*逆词频,逆词频取log值。

对于本博客进行tf-idf 关键词提取 的结果
def getTopkeyWordsTFIDF(stop_word_file_path,topK=100,content = ''):
try:
jieba.analyse.set_stop_words(stop_word_file_path)
tags = jieba.analyse.extract_tags(content, topK, withWeight=True,allowPOS=('ns', 'n', 'vn', 'v'))
for v, n in tags:
print (v + '\t' + str((n )))
top_word_dict_TFIDF[v] = n * 100
#tfidf *100 作为词频
except Exception as e:
print(e)
finally:
pass
'''
算法 0.08462815202056018
图像 0.06854115641965353
数据 0.05283910802670873
文档 0.05101220109808328
使用 0.04392841012376796
函数 0.04240757682591333
查询 0.0403819432194448
匹配 0.037694924619685634
代码 0.036335922349209154
方法 0.03484516772501038
节点 0.03421192915540486
特征 0.03318907987532231
进行 0.03178994977740093
排序 0.029891585563684996
计算 0.029777524393560077
需要 0.029736538415988556
线程 0.029006587816953804
像素 0.028699044745897434
模型 0.027916255808773046
文件 0.027420392410540367
字段 0.026784762281347744
结果 0.026095752460980292
视差 0.024639602681519393
信息 0.024103853358438333
分片 0.02334856522790845
文章 0.021895636116826444
处理 0.02126962755753931
学习 0.021179099985705236
定义 0.020732334877947022
实现 0.020613687169542698
'''
TEXTRANK
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
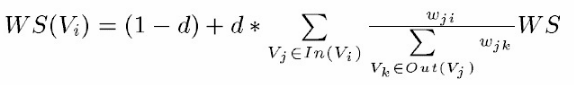
textRank认为一个节点如果入度多且权重大,那么这个节点越重要。
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001
def getTopkeyWordsTextRank(stop_word_file_path, topK=100, content=''):
try:
jieba.analyse.set_stop_words(stop_word_file_path)
tags = jieba.analyse.textrank(content, topK, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v'))
for v, n in tags:
print(v + '\t' + str(((n))))
top_word_dict_TEXTRANK[v] = n * 100
# tfidf *100 作为词频
except Exception as e:
print(e)
finally:
pass
'''
数据 1.0
进行 0.8520047479125313
算法 0.7878563717681994
使用 0.7413343451163064
图像 0.733750388302769
需要 0.6527613198715548
方法 0.5983757281819947
没有 0.5513815490421555
特征 0.5053884991210178
时候 0.5031281843586937
信息 0.4642691681828157
问题 0.45032962083226463
结果 0.4213188543199718
函数 0.41455249888086887
计算 0.41196285238282
匹配 0.4071946751633247
系统 0.382567649352275
学习 0.379993505382963
查询 0.35052867047739833
模型 0.3491924762856509
可能 0.3402092089518257
文档 0.32547879984341055
实现 0.32384145738670744
文件 0.3208866809932887
代码 0.3179633754741148
处理 0.31097955145706435
时间 0.30036400417108766
用户 0.2886245261221456
工作 0.2882269554425558
节点 0.2855624228572076
'''
word2vector
体验一下百度的word2vector,在文章:
https://blog.csdn.net/wangyaninglm/article/details/81232724
我有说过百度目前为止提供的NLP相关服务业界领先,我们来体验一下
# -*- coding:utf-8 -*-
"""@author:season@file:main.py@time:2018/6/1323:01"""
from aip import AipNlp
""" 你的 APPID AK SK """
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
word1 = "张飞"
dict_zhangfei = {}
word2 = "关羽"
dict_liubei = {}
""" 调用词向量表示 """
dict_zhangfei = client.wordEmbedding(word1)
print(dict_zhangfei)
dict_liubei = client.wordEmbedding(word2)
print(dict_liubei)
vector_zhangfei = dict_zhangfei['vec']
vector_liubei = dict_liubei['vec']
import numpy as np
import math
def Cosine(vec1, vec2):
npvec1, npvec2 = np.array(vec1), np.array(vec2)
return npvec1.dot(npvec2)/(math.sqrt((npvec1**2).sum()) * math.sqrt((npvec2**2).sum()))
# Cosine,余弦夹角
print(""" 调用词义相似度: """,client.wordSimEmbedding(word1, word2))
print("余弦相似度:",Cosine(vector_zhangfei, vector_liubei))
百度词向量其实返回的是一个1024维的词向量,而且相似度的衡量用的就是余弦相似度可以说是非常接地气了
结果:

当然这个是一个讨巧的方案,因为目前来看word2vector 要自己用语料来训练,假如我们要针对行业 的语料来进行训练,应该怎么搞呢?
gensim 训练词向量
工业级开源组件,强烈推荐
部分开源词向量
- 1.Chinese Word Vectors:目前最全的中文预训练词向量集合
https://www.jiqizhixin.com/articles/2018-05-15-10
https://github.com/Embedding/Chinese-Word-Vectors - 2.Tencent AI Lab Embedding Corpus for Chinese Words and Phrases
https://ai.tencent.com/ailab/nlp/embedding.html - 3.Pre-trained word vectors
We are publishing pre-trained word vectors for 294 languages, trained on Wikipedia using fastText.
These vectors in dimension 300 were obtained using the skip-gram model described in Bojanowski et al. (2016) with default parameters.
https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
未完待续
NLP系列文章:

- 聊天机器人 ,中文翻译,繁简 ,关键词提取,主题提取,摘要提取 ,命名体识别,分词 ,情感分析,正负类分析 ,近义词,同义词,句子相似性,聚类,监督,无监督,词性标注,词向量句子向量
- nlp 总结 分词,词义消歧,词性标注,命名体识别,依存句法分析,语义角色标注
- 学习笔记CB007:分词、命名实体识别、词性标注、句法分析树
- 使用Stanford CoreNLP的Python封装包处理中文(分词、词性标注、命名实体识别、句法树、依存句法分析)
- 自然语言分析之命名实体识别_Stanford Named Entity Recognizer (NER)简单实例
- nlp-形式语言与自动机-ch07-自动分词、命名实体识别与词性标注
- 学习笔记CB007:分词、命名实体识别、词性标注、句法分析树
- 自然语言分析之命名实体识别_Stanford Named Entity Recognizer (NER)简单实例
- HMM算法-viterbi算法的实现及与分词、词性标注、命名实体识别的引用
- 哈工大ltp,分词,词性标注,命名实体识别技术的特征提取
- 怎样用OpenNLP来实现命名实体识别
- 命名实体识别 | NLP系列学习
- NLP入门(五)用深度学习实现命名实体识别(NER)
- 干货 | 深度学习在NLP的命名实体识别中(NER)的应用
- Python 结巴分词实现关键词抽取分析
- NLP入门(五)用深度学习实现命名实体识别(NER)
- [NLP] 命名实体识别简要知识点
- NLP之中文命名实体识别
- Python 结巴分词 关键词抽取分析
- 自然语言处理之分词、命名主体识别、词性、语法分析-stanfordcorenlp-NER(二)