[论文学习]3——在工业炼油中应用VM-SAE的案例分析
《Deep Learning-Based Feature Representation and Its Application for Soft Sensor Modeling With Variable-Wise Weighted SAE》
论文地址:https://ieeexplore.ieee.org/document/8302941
一周多的时间终于将这篇论文翻译完了。其中包括三科学校的考试
在整个翻译过程中,可以说,让我逐步了解了AE、SAE、VM-SAE几种编码器的基本原理,具体的学习还需在UFLDL中深入学习。
UFLDL教程:http://ufldl.stanford.edu/wiki/index.php/UFLDL教程
本人将继续将同相关方法的论文(老师给我的)继续翻译进行了解及学习,若有同方向的同学可以一起学习交流哈。
在本节中,所提出的基于深度学习的软测量在工业脱丁烷塔过程中得到验证。首先,详细给出了关于该过程的描述。然后,进行产品浓度预测通过软测量建模。案例研究在MATLAB 2013a的平台上进行。
A.脱丁烷塔的描述
在工业炼油厂中,对单个单元及整个过程进行优化和检测具有重要意义,这可以大大提高对产品质量和盈利能力的控制。脱丁烷塔是炼油工艺的重要组成部分,用于脱硫和石脑油裂解。图5给出了该脱丁烷塔的流程图。该过程主要有六种装置,即热交换器,塔顶冷凝器,底部再沸器,回流泵,液化石油气(LPG)分流器的进料泵和回流蓄能器。在脱丁烷塔中,从石脑油流中除去丙烷(C3)和丁烷(C4)。由于希望使脱丁烷塔底部的丁烷含量最小化,因此丁烷含量的实时测量对于改善脱丁烷塔的控制是至关重要的。然而,C4浓度不是直接测量底部流量,而是直接测量气相色谱仪连续的去异戊烷塔的消耗量,这通常会导致较大的测量延迟。

为了解决测量问题提高色谱柱的控制质量,采用软测量实时估算底部的丁烷浓度。在工厂安装了几个硬传感器来收集过程变量,这些变量可以用作软测量的次要变量。选择七个变量用于软测量建模。表1给出了这些变量的详细描述。炼油厂过程的脱丁烷塔中涉及的变量之间存在复杂的非线性。这可以通过比较每对变量之间的趋势图来验证。因此,有必要进行非线性软测量建模以提高预测性能。为此,将设计好的特征作为回归模型的输入至关重要。因此,这里采用深度学习来从原始数据获得高级特征。特别地,VW-SAE可用于设计逐层分层输出相关特征。
B.结果和讨论
为了在采样时间t估计输出样本,应考虑过程动态。也就是说,基于采样时间t处的输入变量和具有滞后输入和输出的数据的先前采样的数量来增加新变量。在L. Fortuna, S. Graziani, and M. G. Xibilia, “Soft sensors for product quality monitoring in debutanizer distillation columns,” Control Eng. Pract., vol. 13, no. 4, pp. 499–508, 2005.中,Fortuna等人已经做了很多实验来研究最佳增强变量,这些增强变量是在试验和误差方法中获得的,由专家知识和物理洞察力指导。最后,设计了用于软测量的增强变量数
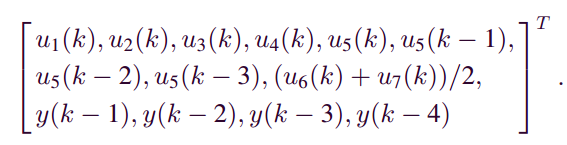
因此,本文还有13个变量用于软测量建模。从该过程中收集了总共2390个样本。对于模型的构建和测试,1000个样本用作训练样本,其余样本用于测试数据集。要将VW-SAE用于特征表示,第一步是确定模型结构。VW-SAE的输入层有13个神经元,因为13个变量用于特征提取。网络的结构由试点法决定。因此,VW-SAE模型结构由三个AE层组成,其中隐藏的神经元数分别为10,7和4。为了获得VW-SAE,使用逐层贪婪预训练来获得每个VW-AE的权重和偏差良好的初始化。使用随机批量梯度下降算法训练每个VW-AE模型,其批量大小设置为20个样本。图6显示了每个VW-AE的批量的训练误差趋势。批量大小为20,总共1000个训练样本,每个VW-AE迭代训练50次。从图6中可以看出,对于每个VW-AE,VW-AE模型可以在少量训练批次内非常快速地收敛。
在VW-SAE逐层预训练之后,将输出层添加到VW-SAE的顶部以进行权重微调和输出预测。测试数据集上的预测RMSE和R2分别为0.0379和0.9444。详细的预测结果如图7所示。可以看出,预测输出值通常可以很好地跟踪测试数据集上的实际输出值。主要预测误差在于具有极小或极大输出值的那些数据样本上。对于这些数据点,训练数据集中很少有样本很难提供有用建模的信息。
特别地,图8中用四个图形描述了各个方面中的预测误差。图8(a)显示了误差趋势以及样本数量。从图8(a)可以看出,预测误差大多在零附近,只有少量大的误差点。这表明对于大多数测试数据点,预测通常是准确的。图8(b)给出了评估预测误差是否遵循高斯分布的正态概率图。可以看出,大多数数据点位于红色参考线周围。然而,仍有一些点不在红色对角线上,这些红色对角线是正态分布的指标。因此,预测误差不严格遵循正态分布。这也可以在图8(c)中看到,图8(c)以图形方式呈现预测误差的直方图。图8(d)显示了每个样本的预测误差与其先前滞后样本之一的散点图。可以看出,滞后误差之间存在线性模式。它表明脱丁烷塔是一个动态过程,相邻样本之间存在动态信息。这就是我们为特征表示和输出预测采用滞后过程变量的原因。
为了验证所提方法的有效性和灵活性,还采用了具有相同网络结构的原始SAE进行特征表示和输出预测,其中不使用所提出的变量加权技术。另外,训练具有神经元层结构[13 10 7 4 1]的多层神经网络以预测输出变量,其中权重和偏差用随机值初始化。同时,支持机器的浅层模型(SVM)也被用于软测量建模。这些神经网络的学习率设置为1。在训练这些模型后,它们可用于测试样本的输出预测。表II给出了测试数据集上SVM,多层神经网络(NN),SAE和VW-SAE的预测结果。可以看出,SVM给出了最差的预测结果,因为它无法充分描述非线性数据结构。通过采用多层网络结构,后三种方法可以比SVM更准确地逼近复杂数据关系。然而,传统的多层NN在三种NN方法中提供最差的预测性能,而VW-SAE可以实现最佳的预测精度。对于多层NN,权重和偏差是随机初始化的。它倾向于局部最优。不同的是,可以在SAE中逐层提取高级抽象特征。不同的是,可以在SAE中逐层提取高级抽象特征。因此,这些特征对于预测任务而言更加结构化。此外,通过使用SAE来初始化完全连接的预测网络的权重和偏差项,可以避免在较低的局部最优处停止并加速学习过程。因此,SAE可以提供比多层NN更好的预测精度。但是,SAE侧重于输入空间的每个维度的同等重建。因此,它不能保证所有特征都与每层中的输出变量相关。通过分析不同变量的相关性,VW-SAE旨在选择性地重建每个VW-AE中不同变量的不同权重的数据。因此,每个VW-AE可以从其输入层找到与输 23ff8 出相关的特征表示,然后VW-SAE可以逐层提取高级输出相关特征。这样,VW-SAE比多层NN和SAE具有更好的预测性能。
此外,我们已经研究了用于多层NN,SAE和VW-SAE的每个全连接监督预测网络的学习过程。计算机的模拟配置如下。操作系统:Windows 7(64位); CPU:Intel Core TM i5-3230M(2.4 GHz); RAM:4.0 GB; MATLAB的版本是2013a。图9显示了这三种方法的完整批次训练误差。在图9中,可以看出多层NN的初始训练误差远大于其他两种方法。这是因为NN的参数是随机初始化的,而其他两种方法利用逐层预训练的SAE来初始化参数。因此,它们具有更好的初始参数。此外,基于SAE和VW-SAE的方法可以比多层NN更快地达到收敛状态。这可以从以下事实看出:基于SAE和VW-SAE的方法仅需要约40个时期来收敛,而多层NN为80个时期。此外,VW-SAE在每个时期具有最低的训练误差。这表明所提出的VW-SAE优于传统的多层NN和SAE。
结论
在本文中,已经介绍了软测量应用中的特征表示的深度学习。为了克服传统深度学习算法的局限性,提出了一种新的VW-SAE模型用于高级输出相关的特征提取。与传统的深度学习模型不同,传统的深度学习模型通常以无监督的方式进行分层预训练,VW-SAE可以以监督或半监督的方式进行预训练。首先,通过与输出变量的相关性分析,从每个AE的输入层中的其他变量识别重要变量。然后,根据它们与输出变量的相关性,为这些变量分配不同的权重。然后,VW-AE被设计和堆叠以形成深度网络。所提出的VW-SAE的有效性在工业应用中得到验证。
对于将来的工作,所提出的VW-SAE也可用于分类问题的模式识别。 此外,尽管相关系数用于测量变量重要性和权重以构建VW-SAE深度模型,但它是线性相关性测量。 因此,没有充分挖掘相关性。 未来的工作还可以解决如何构建非线性变量加权深度学习模型以获得更强大的性能的问题。

- 多任务学习概述论文:从定义和方法到应用和原理分析
- 统计分析学习笔记——图像处理中的统计应用案例
- 开源力量公开课第二十六期-大数据的实时分析与应用案例分享
- hashset的应用及注意事项,以及案例分析和详细注释
- 个人作业2---英语学习APP案例分析
- 一站式学习Wireshark(三):应用Wireshark IO图形工具分析数据流
- 一站式学习Wireshark(三):应用Wireshark IO图形工具分析数据流
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
- VM 操作系统实例化(基于 KVM 的虚拟化研究及应用--崔泽永(2011))的论文笔记
- phpwind代码分析之global.php简单说明(主要学习php基础知识的应用)
- [置顶] 机器学习、深度学习、计算机视觉、自然语言处理及应用案例——干货分享(持续更新......)
- Linux 学习笔记_12_Windows与Linux文件共享服务_1.1_--Samba(下)Samba经典应用案例
- 机器学习、深度学习、计算机视觉、自然语言处理及应用案例——干货分享
- 深度学习在视频分析中的架构、算法及应用
- 论软件需求分析方法和工具的选用—论文4:IC行业内部的CAD应用
- K-means聚类算法原理分析与实际应用案例分析(案例分析另起一篇博客)
- 干货 | 论文解读:GAN在网络特征学习中的应用
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- Android Service(不和用户交互应用组件)案例分析
- 《循序渐进DB2.DBA系统管理、运维与应用案例》 第二章 菜鸟学习时会遇到的问题