模型评估的方法:Holdout检验、交叉验证、自助法(Bootstrap)
Holdout检验:
将原始的样本集合随机划分成训练集和验证集两部分。
如:
对于一个点击率预测模型,我们把样本按照70%~30% 的比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。
Holdout 检验的缺点很明显,即在验证集上计算出来的最后评估指标与原始分组有很大关系。为了消除随机性,研究者们引入了“交叉检验”的思想。
交叉检验:
k-fold交叉验证:
首先将全部样本划分成k个大小相等的样本子集;依次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k经常取10。
留P验证:
每次留下P个样本作为验证集,其余所有样本作为测试集。样本总数为n,依次对n个样本进行遍历,进行n次验证,再将评估指标求平均值得到最终的评估指标。
事实上,我们往往使用的是留一验证。
因为留p验证是每次留下p个样本作为验证集,而从n个元素中选择p个元素有种可能,因此它的时间开销更是远远高于留一验证,故而很少在实际工程中被应用。
在样本总数较多的情况下,留一验证法的时间开销极大。
自助法(Bootstrap):
这种方法往往在神经网络的训练中常用。即每一次训练迭代(称为iteration)都从一个总数n的样本中抽取m个样本(batch_size),然后一共进行n/m次迭代后称为一次epoch(即我们一共用了整个数据集大小数量的样本进行了训练)。
注意:
在自助法的采样过程中,对n个样本进行n次自助抽样,当n趋于无穷大时,最终有多少数据从未被选择过?
一个样本在一次抽样过程中未被抽中的概率为
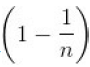
则n次抽样均未抽中的概率为

当n趋于无穷大时,概率为

数学中的重要极限:

于是我们可以计算
:

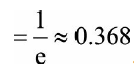
因此,当样本数很大时,大约有36.8%的样本从未被选择过,可作为验证集。
阅读更多
- 模型评估-交叉验证与自助法
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- HAWQ + MADlib 玩转数据挖掘之(十二)——模型评估之交叉验证
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 评估方法与CrossValidation交叉验证
- 【模型比较与选择】交叉验证方法原理及R语言代码实现
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】28 交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- [翻译中]【Scikit-Learn 中文文档】二十八:交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN
- 7.8 回归模型评估与交叉验证
- 【Scikit-Learn 中文文档】交叉验证 - 模型选择和评估 - 用户指南 | ApacheCN