论文解读(DGB)《Self-supervised Graph Representation Learning via Bootstrapping》
论文信息
论文标题:Self-supervised Graph Representation Learning via Bootstrapping
论文作者:Feihu Che, Guohua Yang, Dawei Zhang, Jianhua Tao, Pengpeng Shao, Tong Liu
论文来源:2020, Neurocomputing
论文地址:download
论文代码:download
1 介绍
不使用负样本的对比学习。
2 方法
Deep Graph Bootstrapping(DGB) 的框架如下:
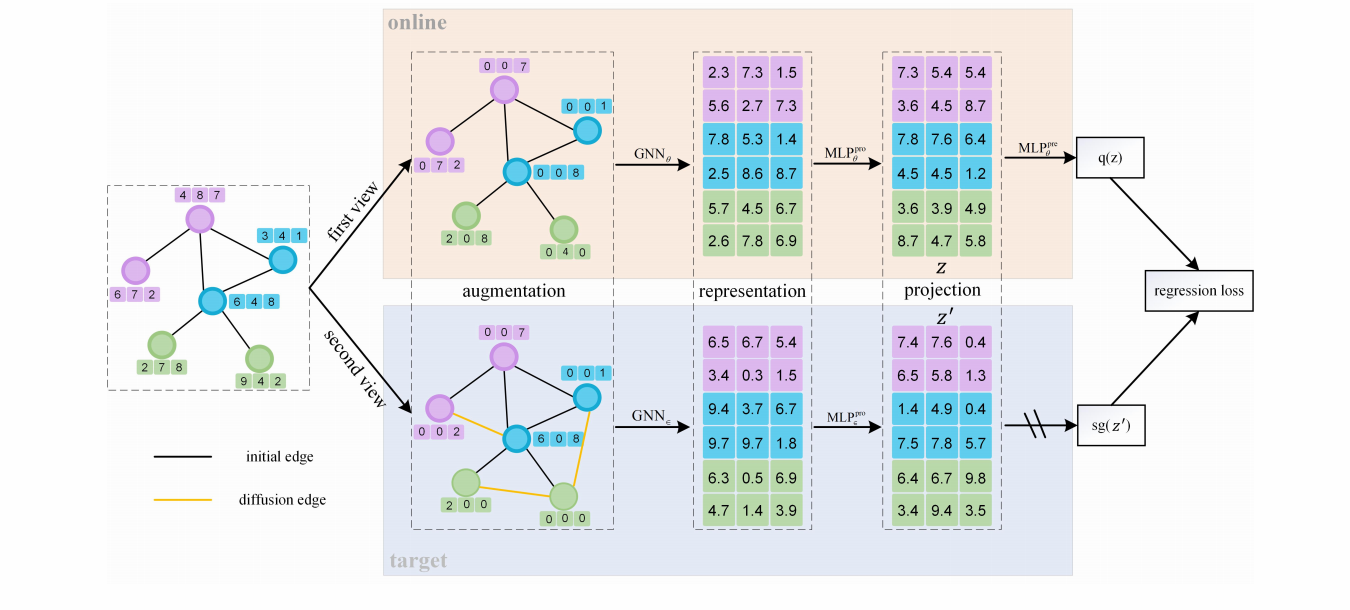
2.1 Encoder
$H^{(l+1)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right)$
2.2 数据增强
节点数据增强:
node dropout (ND) $\widetilde{\mathrm{X}}_{i}=\frac{\tilde{\epsilon}_{i}}{1-\delta_{n d}} \mathrm{X}_{i}$
node feature dropout (NFD) $\tilde{\mathrm{X}}_{i j}=\frac{\tilde{\epsilon}_{i j}}{1-\delta_{n f d}} \mathrm{X}_{i j}$
其中:$\delta_{n d}$ 和 $\delta_{n f d}$ 是 ND 和 NFD 各自的丢弃概率,$\tilde{\epsilon}_{i}$ 和 $\tilde{\epsilon}_{i j}$ 分别从伯努利分布 $\left(1-\delta_{n d}\right)$、$\left(1-\delta_{n f d}\right) $ 中提取。
邻接矩阵增强:
$S=\sum\limits _{k=0}^{\infty} \theta_{k} \mathbf{T}^{k}\quad\quad\quad(4)$
$\mathbf{S}^{\text {heat }}=\exp \left(t \mathbf{A} \mathbf{D}^{-1}-t\right)\quad\quad\quad(5)$
$\mathbf{S}^{\mathrm{ppr}}=\alpha\left(\mathbf{I}_{n}-(1-\alpha) \mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2}\right)^{-1}\quad\quad\quad(6)$
2.3 训练方式
指数移动平均
$\xi \leftarrow p \xi+(1-p) \theta\quad\quad\quad(7)$
2.4 损失函数
$\bar{q}(z) \triangleq q(z) /\|q(z)\|_{2}\theta\quad\quad\quad(8)$
$\bar{z}^{\prime} \triangleq z^{\prime} /\left\|z^{\prime}\right\|_{2}\theta\quad\quad\quad(9)$
$\mathcal{L}_{\theta}^{\text {DGB }} \triangleq\left\|\bar{q}(z)-\bar{z}^{\prime}\right\|_{2}^{2}\theta\quad\quad\quad(10)$
3 实验
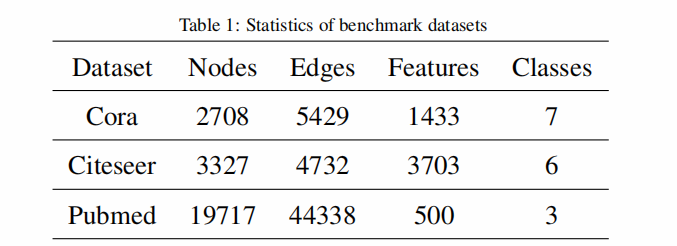
数据集
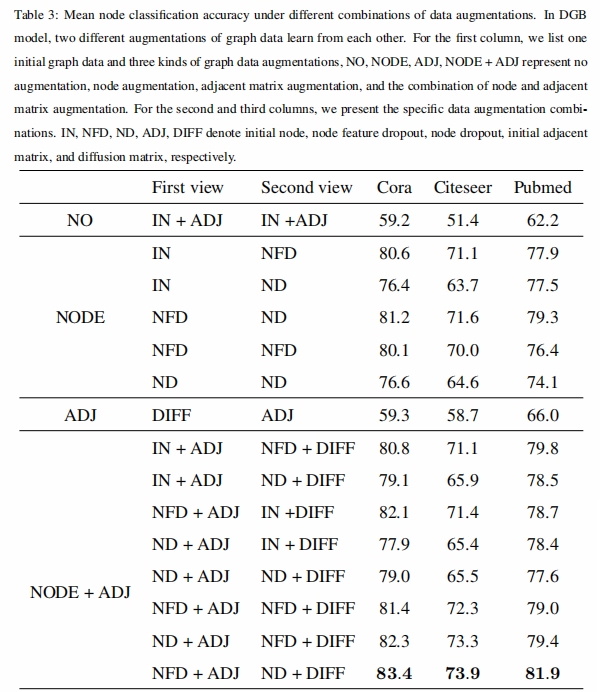
实验结果

更多细节,请参考论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》

- 论文解读(S^3-CL)《Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learning》
- 《Knowledge Transfer from Multiple Self-supervised Learning Tasks via Graph Distillation 对于视频分类》论文笔记
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
- 论文解读(Survey)《Self-supervised Learning on Graphs: Contrastive, Generative,or Predictive》第一部分:问题阐述
- 论文解读(Survey)《Self-supervised Learning on Graphs: Contrastive, Generative,or Predictive》第二部分:对比学习
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
- 论文解读(MCNS)《Understanding Negative Sampling in Graph RepresentationLearning》
- 论文解读(SupCosine)《Supervised Contrastive Learning with Structure Inference for Graph Classification》
- 论文解读(CSSL)《Contrastive Self-supervised Learning for Graph Classification》
- NRL论文解读:《Deep Network Embedding for Graph Representation Learning in Signed Networks》
- Extreme Learning to Rank via Low Rank Assumption论文解读
- 深度学习入门:Supervised Hashing for Image Retrieval via Image Representation Learning
- 论文解读(GraRep)《GraRep: Learning Graph Representations with Global Structural Information》
- 论文笔记(一)Deep Ranking for Person Re-Identification via Joint Representation Learning
- Learning to Cluster Faces on an Affinity Graph论文解读
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
- 深度学习:论文self-trainsfer learning for weakly supervised lesion localization
- CVPR 2016 Structural-RNN: Deep Learning on Spatio-Temporal Graphs 论文解读
- 【论文解读】Inductive Representation Learning on Large Graphs(GraphSAGE)
- DSOD: Learning Deeply Supervised Object Detectors from Scratch 论文解读