python读取TXT文件并进行修改
需求:统计每行中$的符号个数;在结尾处添加这样行的@后面的内容:第一次小于等于该行的$数目的行;若不存在那么写本行@后面的内容(将966txt转成100txt)
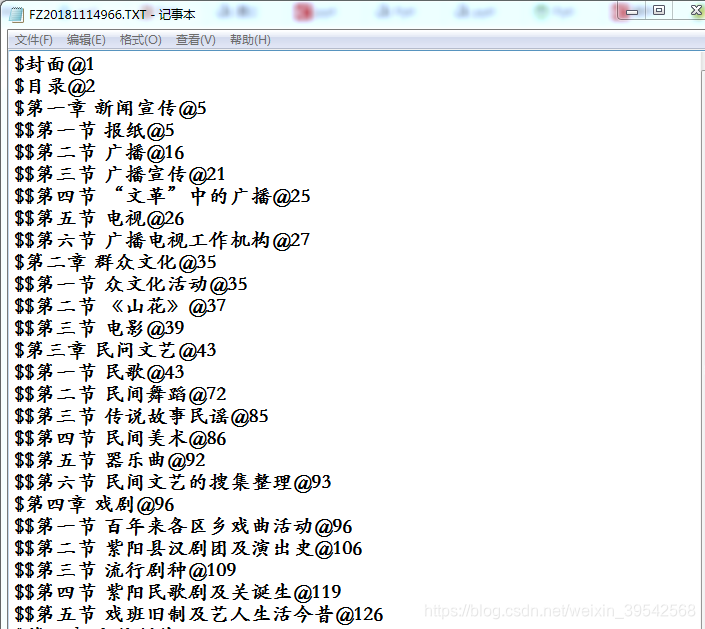

(一)打开文件:两种方式
[code]f = open("F:\曹珊软件\cs\FZ2018111496.TXT","r")
f
Out[3]: <_io.TextIOWrapper name='F:\\曹珊软件\\cs\\FZ2018111496.TXT' mode='r' encoding='cp936'>
但是必须不要忘记关闭文件,f.close()
为了防止忘记关掉这个文件,可以采用第二种方式打开文件
[code]with open("F:\曹珊软件\cs\FZ2018111496.TXT","r") as f:
str = f.read()
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-9-8892e43bf303> in <module>()
1 with open("F:\曹珊软件\cs\FZ2018111496.TXT","r") as f:
----> 2 str = f.read()
3
UnicodeDecodeError: 'gbk' codec can't decode byte 0xbf in position 2: illegal multibyte sequence
utf-8包含了全世界所有国家用到的全部字符,可以解码中英文,英文用一个字节,中文用三个字节,但是GBK是专门用来解码中文的,中英文都是两字节,如果开发的是偏向中文程序,使用GBK编码,如果是外语的,那就用utf—8解码节省空间。
UTF-8编码的文字可以在各国各种支持UTF8字符集的浏览器上显示。
UTF8是国际编码,它的通用性比较好,外国人也可以浏览论坛,GBK是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大~
报错的原因是,TXT文件时utf—8的编码,但是打开文件的时候默认是用gbk去解码,所以在open()函数的时候将r变成rb,或者encoding = utf-8
open()函数中的参数,encoding = utf-8或者gbk 代表返回的数据采用哪种编码,默认是gbk
[code]with open("F:\曹珊软件\cs\FZ20181114966.TXT",encoding = 'utf-8') as f:
all_lines = f.readlines()
(二)打开这个TXT文件,并且读整个文件,all_lines = f.readlines()
有三个读文件的函数,read()、readLine()、readlines()他们的区别就是,
[code]f = open("F:\曹珊软件\cs\FZ20181114966.TXT",encoding = 'utf-8')
txt1 = f.read()
print(txt1)
$封面@1
$目录@2
$第一章 新闻宣传@5
$$第一节 报纸@5
$$第二节 广播@16
$$第三节 广播宣传@21
$$第四节 “文革”中的广播@25
$$第五节 电视@26
$$第六节 广播电视工作机构@27
$第二章 群众文化@35
$$第一节 众文化活动@35
$$第二节 《山花》@37
$$第三节 电影@39
$第三章 民问文艺@43
$$第一节 民歌@43
$$第二节 民间舞蹈@72
$$第三节 传说故事民谣@85
$$第四节 民间美术@86
$$第五节 器乐曲@92
$$第六节 民间文艺的搜集整理@93
$第四章 戏剧@96
$$第一节 百年来各区乡戏曲活动@96
$$第二节 紫阳县汉剧团及演出史@106
$$第三节 流行剧种@109
$$第四节 紫阳民歌剧及关诞生@119
$$第五节 戏班旧制及艺人生活今昔@126
$第五章 文艺创作@146
$$第一节 创作概况@146
$$第二节 作品存目@153
$第六章 图书档案@175
$$第一节 图书@175
$$第二节 档案@177
$第七章 文物与古生物化石@180
$$第一节 古文化遗址@180
$$第二节 古栈道@181
$$第三节 古建筑@182
$$第四节 古墓葬@184
$$第五节 石刻@185
$$第六节 馆藏文物@188
$$第七节 革命文物@189
$$第八节 文物保护@194
$$第九节 古生物化石@197
$第八章 宗教@199
$$第一节 佛教@199
$$第二节 道教@202
$$第三节 伊斯兰教@207
$$第四节 天主教@210
$第九章 体育@213
$$第一节 发展概况及项目@213
$$第二节 机构设置@214
$$第三节 群众业余体育活动@214
$$第四节 体育竞赛@224
[code]f = open("F:\曹珊软件\cs\FZ20181114966.TXT",encoding = 'utf-8')
txt2 = f.readline()
print(txt2)
$封面@1
[code]f = open("F:\曹珊软件\cs\FZ20181114966.TXT",encoding = 'utf-8')
txt3 = f.readlines()
print(txt3)
['\ufeff$封面@1\n', '$目录@2\n', '$第一章 新闻宣传@5\n', '$$第一节 报纸@5\n', '$$第二节 广播@16\n', '$$第三节 广播宣传@21\n', '$$第四节 “文革”中的广播@25\n', '$$第五节 电视@26\n', '$$第六节 广播电视工作机构@27\n', '$第二章 群众文化@35\n', '$$第一节 众文化活动@35\n', '$$第二节 《山花》@37\n', '$$第三节 电影@39\n', '$第三章 民问文艺@43\n', '$$第一节 民歌@43\n', '$$第二节 民间舞蹈@72\n', '$$第三节 传说故事民谣@85\n', '$$第四节 民间美术@86\n', '$$第五节 器乐曲@92\n', '$$第六节 民间文艺的搜集整理@93\n', '$第四章 戏剧@96\n', '$$第一节 百年来各区乡戏曲活动@96\n', '$$第二节 紫阳县汉剧团及演出史@106\n', '$$第三节 流行剧种@109\n', '$$第四节 紫阳民歌剧及关诞生@119\n', '$$第五节 戏班旧制及艺人生活今昔@126\n', '$第五章 文艺创作@146\n', '$$第一节 创作概况@146\n', '$$第二节 作品存目@153\n', '$第六章 图书档案@175\n', '$$第一节 图书@175\n', '$$第二节 档案@177\n', '$第七章 文物与古生物化石@180\n', '$$第一节 古文化遗址@180\n', '$$第二节 古栈道@181\n', '$$第三节 古建筑@182\n', '$$第四节 古墓葬@184\n', '$$第五节 石刻@185\n', '$$第六节 馆藏文物@188\n', '$$第七节 革命文物@189\n', '$$第八节 文物保护@194\n', '$$第九节 古生物化石@197\n', '$第八章 宗教@199\n', '$$第一节 佛教@199\n', '$$第二节 道教@202\n', '$$第三节 伊斯兰教@207\n', '$$第四节 天主教@210\n', '$第九章 体育@213\n', '$$第一节 发展概况及项目@213\n', '$$第二节 机构设置@214\n', '$$第三节 群众业余体育活动@214\n', '$$第四节 体育竞赛@224']
所以三个函数返回的各不相同
(三)对文本进行按需求修改:
每一行文本的开头有$符号,我们根据$符号个数去添加每一行结尾的内容,$代表这行是一级目录,$$代表这条目录是二级目录,那么我们的一级目录的终止页码要写的是下一个一级目录的起始页码,也就是要找这个一级目录下面的第一个一级目录行。
下面代码:
[code]for i in range(len(all_lines)):
nb = all_lines[i].count("$")
for j in range(i+1,len(all_lines)):
if(all_lines[j].count("$")<=nb):
str = re.search(r'[^@]+$', all_lines[j]).group()
all_lines[i] = all_lines[i].strip() +'@'+str
break
这里面用到如何截取文本行中特定字符后面的内容,正则表达式可以解决这个问题。
http://www.runoob.com/python3/python3-reg-expressions.htmlPython3 正则表达式 菜鸟教程
这里也用到了去除每一行末尾的换行符,在换行符之前加@页码,所以这时候先去掉'\n'。str.strip()
(四)再对新的内容进行写操作
因为我们此时的all_lines 是一个list,里面的元素是一个个字符串,这时候写操作要用的函数式writelines而不是write()
file.write(str)的参数是一个字符串, file.writelines(sequence)的参数一个序列,list,tuple,它可以迭代写入文件。阅读更多

- python逐个读取txt字符修改过后放到另一个txt文件中
- Python读取多个txt文件并进行保存
- Python+Selenium进行UI自动化测试项目中,常用的小技巧2:读取配置文件(configparser,.ini文件)
- Python 读取TXT文件
- python操作表格、txt文件、字典进行参数化(数据驱动)
- python读取TXT文件并逐行写入另外一个TXT文件
- 对txt文件中读取的字母进行排序
- python读取和显示txt文件
- Java创建TXT文件并进行读、写、修改操作
- python读取txt文件时的中文乱码问题
- 关于C#和ASP.NET中对App.config和Web.config文件里的[appSettings]和[connectionStrings]节点进行新增、修改、删除和读取相关的操作
- MATLAB处理txt文本文件---数据格式要有规律性,否则要用编写特定方式进行读取
- python读取excel中表结构生成sql语句,存入txt文件
- c# 控制台将TXT文件进行修改并存到另一个txt中
- Java创建TXT文件并进行读、写、修改操作
- Python读取TXT文件问题
- 利用python读取带有中文的字符串,和将带有中文的字符串写到txt文件中
- Python读取json文件,并转化为字典进行提取字段(出现索引must be int,not str)解决方案
- 将TXT文件上传的服务器上并将读取内容绑定到DataTable进行验证
- 使用python读取txt文件的内容,并删除重复的行数方法