python:一个简单爬虫的python实现过程
摘 要
随着互联网的不断普及和发展,结构庞大而复杂的万维网所承载的数据量早已浩如烟海。要从这样一个庞大的“数据库”中批量的有组织的获取想要的数据,搜索引擎早已不能满足我们的需求,而网络爬虫作为网络数据获取的重要技术,在网络数据的批量获取和收集中具有不可替代的重要作用。本文作为笔者学习爬虫的笔记,主要介绍了什么是爬虫(what),爬虫的适用范围(when)以及分享了笔者使用python语言实现了一个简单的详细过程(how),并展示了最终的测试效果。笔者初识爬虫,尚未精通,若有不当,敬请指正!
一,什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
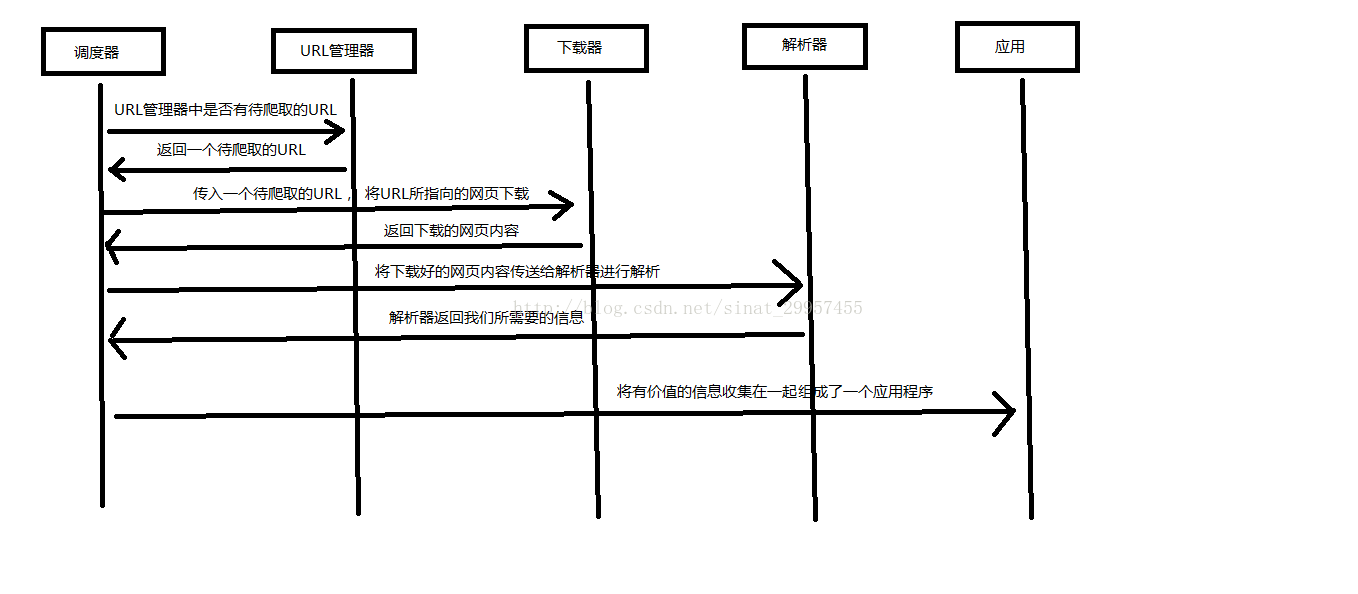
1)调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
2)URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
3)网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
4)网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
5)应用程序:就是从网页中提取的有用数据组成的一个应用。
二,爬虫的使用范围
利用爬虫我们可以才互联网网页上获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
1)知乎:爬取优质答案,为你筛选出各话题下最优质的内容。
2)淘宝、京东:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
3)安居客、链家:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
4)拉勾网、智联:爬取各类职位信息,分析各行业人才需求情况及薪资水平。
5)雪球网:抓取雪球高回报用户的行为,对股票市场进行分析和预测。
......
三,爬虫的实现步骤
1)打开Anaconda Prompt:

2)升级pip的版本到最新版本:conda install pip;

3)通过pip安装Scripy框架:pip install Scrapy(本机已经安装,所以出现如下图效果);

4)检验scrapy时候安装成功:scrapy(出现如下图效果即为安装成功);

5)创建爬虫项目:scrapy startproject ITcast1;

输入tree命令可以查看到创建的爬虫文件的目录结构:

6)编写item.py文件:打开目录下的item文件并改写代码;
[code]# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ItcastItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 老师姓名 name = scrapy.Field() # 老师职称 title = scrapy.Field() # 老师信息 info = scrapy.Field()
7)编写管道文件pipeline.py:打开目录下的pipeline.py文件并改写代码;
[code]# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ItcastPipeline(object
4000
):
def __init__(self):
self.f = open("itcast_pipeline.json","w")
def process_item(self, item, spider):
content = str(json.dumps(dict(item), ensure_ascii = False)) + ",\n"
self.f.write(content)
#self.f.write(item)
return item
def close_spider(self, spider):
self.f.close()
8)在spiders目录下创建爬虫scrapy genspider itcast "http://www.itcast.cn";

itcast为爬虫名称,"http://www.itcast.cn"为需要爬取的网站的域名。
9)改写itcast.py文件:打开itcast.py文件并改写;
[code]# -*- coding: utf-8 -*-
#import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
import scrapy
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response):
#items = []
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
item = ItcastItem()
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#print(item)
#items.append(item)
# 返回提取到的每个item数据,给管道文件处理,同时还回来继续执行后面的代码
yield item
#items.append(item)
10)检查爬虫文件:scrapy check itcast;

11)执行爬虫:scrapy crawl itcast;


并且将爬取的数据生成了json文件,如下图:

四,总结
爬虫在网络数据获取中具有重要的地位,本文作为笔者的学习笔记,主要介绍了爬虫的相关理论和爬取传智播客网站的教师信息的详细过程,希望作为大家学习的参考。
阅读更多

- 用Python3实现一个简单的爬虫。
- Python实现一个简单的图片爬虫
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
- python实现的一个简单的网页爬虫
- python实现一个简单的爬虫
- Python手记(一):实现简单爬虫过程中的坑
- 实现一个简单的邮箱地址爬虫(python)
- 一个简单的解释器——python实现
- python实现简单爬虫功能
- python实现简单爬虫功能
- 一个简单的Python爬虫
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
- 用Python实现一个简单的算术游戏
- [python脚本]一个简单的web爬虫(1)
- Python 实现一个简单的http服务器
- 一个简单求和函数的C-》SSE-》AVX的实现过程
- 1. python实现简单爬虫功能
- 一个简单的oracle分页存储过程的实现和调用
- python实现简单爬虫功能