python Scrapy网络爬虫实战(存Json文件以及存到mysql数据库)
2018-10-23 11:26
417 查看
版权声明:本人原创文章,转载时请保留所有权并以超链接形式标明文章出处 https://blog.csdn.net/qq_37138818/article/details/83304125
1-Scrapy建立新工程
在开始爬取之前,您必须创建一个新的 Scrapy 项目。 进入您打算存储代码的目录中【工作目录】,运行下列命令,如下是我创建的一个爬取豆瓣的工程douban【存储路径为:C:\python27\web】:
命令: scrapy startproject douban
2-目录 如下
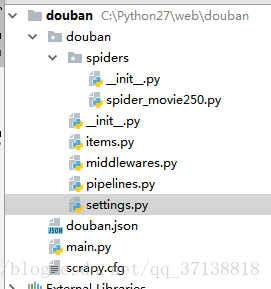
3--items的编写
首先,文件中有items.py,这个里面这要是用来封装爬虫所要爬的字段,如爬豆瓣电影,需要爬电影的ID,url,电影名称等。
[code]# -*- coding:utf-8 -*- import scrapy class MovieItem(scrapy.Item): rank = scrapy.Field() title = scrapy.Field() link = scrapy.Field() rate = scrapy.Field() quote = scrapy.Field()
4-spider_movie250.py 的编写
[code]# -*- coding:utf-8 -*-
import scrapy
from douban.items import MovieItem
class Movie250Spider(scrapy.Spider):
# 定义爬虫的名称,主要main方法使用
name = 'doubanmovie'
allowed_domains = ["douban.com"]
start_urls = [
"http://movie.douban.com/top250/"
]
# 解析数据
def parse(self, response):
items = []
for info in response.xpath('//div[@class="item"]'):
item = MovieItem()
item['rank'] = info.xpath('div[@class="pic"]/em/text()').extract()
item['title'] = info.xpath('div[@class="pic"]/a/img/@alt').extract()
item['link'] = info.xpath('div[@class="pic"]/a/@href').extract()
item['rate'] = info.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract()
item['quote'] = info.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()').extract()
items.append(item)
yield item
# 翻页
next_page = response.xpath('//span[@class="next"]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
#爬每一页
yield scrapy.Request(url, self.parse)
5-编写pipelines
[code]# -*- coding: utf-8 -*-
import json
import codecs
#以Json的形式存储
class JsonWithEncodingCnblogsPipeline(object):
def __init__(self):
self.file = codecs.open('douban.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
#将数据存储到mysql数据库
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class MySQLStorePipeline(object):
#数据库参数
def __init__(self):
dbargs = dict(
host = '127.0.0.1',
db = '数据库名',
user = 'root',
passwd = 'root',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = True
)
self.dbpool = adbapi.ConnectionPool('MySQLdb',**dbargs)
'''
The default pipeline invoke function
'''
def process_item(self, item,spider):
res = self.dbpool.runInteraction(self.insert_into_table,item)
return item
#插入的表,此表需要事先建好
def insert_into_table(self,conn,item):
conn.execute('insert into douban(rank,title,rate,qute,link) values(%s,%s,%s,%s,%s)', (
item['rank'][0],
item['title'][0],
item['rate'][0],
item['quote'][0],
item['link'][0])
)
6-settings的编写
[code]USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1) XXXXXXX) Chrome/70.0.3538.67 Safari/537.36'
# start MySQL database configure setting
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = '数据库名'
MYSQL_USER = 'root'
MYSQL_PASSWD = 'root'
# end of MySQL database configure setting
ITEM_PIPELINES = {
'douban.pipelines.JsonWithEncodingCnblogsPipeline': 300,
'douban.pipelines.MySQLStorePipeline': 300,
}
7-main 的编写
[code]from scrapy import cmdline
cmdline.execute("scrapy crawl doubanmovie".split())
阅读更多

相关文章推荐
- Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
- Python3[爬虫实战] scrapy爬取汽车之家全站链接存json文件
- python3将本地JSON数据文件(大文件)写入MySQL数据库
- python 读取文件以及对文件的json字符串的操作
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
- python备份文件以及mysql数据库的脚本代码
- python3实战scrapy生成csv文件
- Python中Json文件的读入和写入以及simplejson
- python中xlsx,csv以及json文件的相互转化
- python3实战scrapy获取数据保存至MySQL数据库
- Python3实现将本地JSON大数据文件写入MySQL数据库的方法
- 【网络爬虫】【python】网络爬虫(四):scrapy爬虫框架(架构、win/linux安装、文件结构)
- json的两种结构以及json文件转化为python的dict的方式
- 解决python3.6下scrapy中xpath.extract()匹配出来的内容转成json与.csv文件没有编码(unicode)的问题
- Python网络爬虫Scrapy框架研究 以及 代理设置
- python生成以及打开json、csv和txt文件的实例
- [Python进阶-7]文件和目录的IO操作,以及json序列化和反序列化
- 【项目实战】使用Scrapy爬取商品信息并写入MySQL数据库
- 基于Scrapy框架的python网络爬虫学习(3)
- Python实现的读写json文件功能示例