DB2 查询数据,并且统计某一条数据重复出现的次数,并且按照时间顺序取最大的记录
2018-10-22 20:40
399 查看
分享一个sql查询
首先:介绍一下表结构
[code]CREATE TABLE ZYRS_METADATA.T_EXTRACTOR_MESSAGE ( ID VARCHAR ( 32 ) NOT NULL PRIMARY KEY, --uuid TASK_INSTANCE_ID VARCHAR ( 32 ), -- 任务ID LAST_UPDATE_TIME BIGINT, --上次更新时间 DATASOURCE_NAME VARCHAR ( 32 ) NOT NULL,--数据源名称 DATASOURCE_ID VARCHAR ( 32 ), --数据源ID NEW_SCRIPT_PATH VARCHAR ( 128 ), --新脚本路径 OLD_SCRIPT_PATH VARCHAR ( 128 ), --旧脚本路径 IS_ADD_SCRIPT CHAR ( 2 ) --是否新增脚本 )
其次:介绍一下我的查询需求
第一步我需要查询 DATASOURCE_ID, DATASOURCE_NAME, LAST_UPDATE_TIME这三个字段。
第二步我要按照DATASOURCE_ID查询出这个记录出现了多少次,left join字段WAIT_NUMBER表示出现的次数。
第三步我需要根据我查出的记录按照DATASOURCE_ID为基准取每条记录中LAST_UPDATE_TIME最大的那个值
最后:我编写的SQL如下所示
[code]select * from ( select DATASOURCE_ID,DATASOURCE_NAME,LAST_UPDATE_TIME,WAIT_NUMBER,ROW_NUMBER() OVER (PARTITION BY DATASOURCE_ID ORDER BY LAST_UPDATE_TIME DESC) AS RN FROM ( SELECT DISTINCT t.DATASOURCE_ID, t.DATASOURCE_NAME, t.LAST_UPDATE_TIME, g.WAIT_NUMBER FROM T_EXTRACTOR_MESSAGE t LEFT JOIN ( SELECT f.DATASOURCE_ID, count( * ) AS WAIT_NUMBER FROM T_EXTRACTOR_MESSAGE f GROUP BY f.DATASOURCE_ID ) g ON g.DATASOURCE_ID = t.DATASOURCE_ID)) d where RN=1
附:查询样式
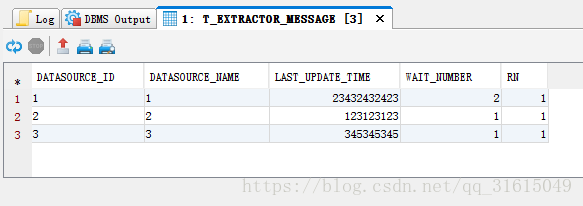

相关文章推荐
- oracle查询指定字段 重复记录大于一条的记录,并统计该记录出现的总次数
- mysql中记录某一字段中重复的个数并且按照次数排序
- 使用SQL语句对重复记录查询、统计重复次数、删除重复数据
- 使用SQL语句对重复记录查询、统计重复次数、删除重复数据
- MySQL查询重复出现次数最多的记录
- SQL 查询重复出现次数最多的记录,按出现频率排序(SQL语句)
- C#统计文章中单词的重复次数,并且按照次数从高到低排序返回(无法处理中文)
- sql查询重复数据且显示出不同数据的重复次数并且排序
- db2 查询某字段值重复记录次数大于2的记录
- MySQL查询重复出现次数最多的记录
- MySQL 查询重复出现次数最多的记录
- 按某一字段分组取最大(小)值所在行的数据,如何按字段删除重复记录
- Oracle查询一批数据,某字段的内容有重复数据,怎样取相同的记录中时间最近的一条
- MySQL 查询重复出现次数最多的记录
- 存储过程查询一张表中记录是否连续、重复并且取出对应的数据
- MySQL根据某一个或者多个字段查找重复数据,并且保留某字段值最大的记录
- 查询任意时间内重复出现的记录
- 编写一个程序,从标准输入中读取若干string对象并查找连续重复出现的单词。所谓连续重复出现的意思是:一个单词后面紧跟着这个单词本身。要求记录连续重复出现的最大次数以及对应的单词
- 随机产生50个30到35的整数,统计每个数字出现的次数(TreeMap实现),输出时按照数字的降序排列,并且统计出现次数最多的数字和它的次数。
- MySQL根据某一个或者多个字段查找重复数据,并且保留某字段值最大的记录